python-win10-tesseract-图像中印刷体字符识别(含字库训练)
目录
- win10安装
- 简单使用
- 训练字库
-
-
- 0.修改环境变量
- 1.先存tiff文件
- 2.产生box
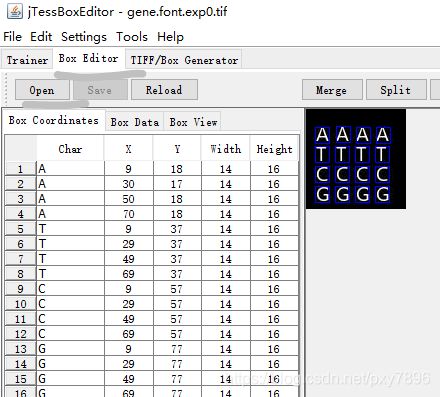
- 3.在jTessBoxEditor里修改字框的位置和实际值
- 4.继续命令行命令
- 5.把上面产生的文件都改名叫gene.XXX
- 6.产生训练数据
- 7.现在的问题是logo区上下两块看不到,而且结果是按列读取的
- 完整命令输出
-
- linux安装我没成功,但是有些资料供参考
-
-
- 原因
- 安装命令
- Ubuntu 报错
-
win10安装
https://github.com/UB-Mannheim/tesseract/wiki
- 安装,一路点next就好
此时默认安装在 C:\Program Files\Tesseract-OCR,我用的是下面这个:

- pip install pytesseract
简单使用
import cv2
import pytesseract
# 下面这句一定要有。pytesseract其实是一个接口,调用的还是引擎
pytesseract.pytesseract.tesseract_cmd = r'C:\\Program Files\\Tesseract-OCR\\tesseract.exe'
import os
path = "G:\\share\\qrcode\\demo\\lib"
os.chdir(path)
img = cv2.imread('1.jpg')
# 这里可以指定语言,看 C:\Program Files\Tesseract-OCR\tessdata 里面XX.traineddata
# lang="eng"
text = pytesseract.image_to_string(img)
print(text)训练字库
上面那种方法识别准确率差异蛮大的,因为tesseract为了兼容性,识别率有下降。因此,我们应该训练自己的字库。我需要识别的仍然是ATCG之类的字符【生信特色:)】
经本人测试,以下两种训练效果一致。简便起见,可以只用4个字符的。多字符修改起来更麻烦。

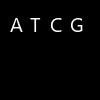
0.修改环境变量
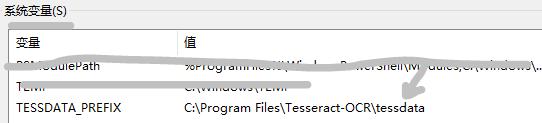
Path也加入exe的路径
![]()
1.先存tiff文件
用G:\share\qrcode\demo\lib\train\jTessBoxEditor-2.3.0\jTessBoxEditor
tools\merge下打开一个jpg,另存为XX.tif,格式最好是XX.font.expN.tif
(jTessBoxEditor-2.3.0这个应该挺好找的,如果找不到可以私信我)
以下是命令行执行命令:
2.产生box
tesseract gene.font.exp0.tif gene.font.exp0 batch.nochop makebox3.在jTessBoxEditor里修改字框的位置和实际值
4.继续命令行命令
例子里只用了一张图片,如果有多张图片要分别处理的。
tesseract gene.font.exp0.tif gene.font.exp0 nobatch box.train
#以上都是对多个文件分别进行的,下面是合并
unicharset_extractor gene.font.exp0.box
shapeclustering -F font_properties -U unicharset gene.font.exp0.tr
mftraining -F font_properties -U unicharset -O unicharset gene.font.exp0.tr
cntraining gene.font.exp0.tr其中font_properties文件内容是:
font 0 0 0 0 0
5.把上面产生的文件都改名叫gene.XXX

6.产生训练数据
combine_tessdata gene.
此时会出现gene.traineddata,把它拷贝到C:\Program Files\Tesseract-OCR\tessdata下,使用时即可:
>>> text = pytesseract.image_to_string(img,lang="gene")
>>> print(text)
TCAATTTAGAAAGCT
ATGGGAACCCGCCCT
ACTCCGGGAGTGGAC
AGCGACTTACCTCGG
GTATGACTAGGTATC
TAGTGCATATTCGTA
CATTCAACGTTGCTG
GATTAAAGTCTTACC
TATCGAATTACCAGA
CGCACAACCGAGATG
>>>原图:

7.现在的问题是logo区上下两块看不到,而且结果是按列读取的
考虑:切分图片,分块读取,然后合并
完整命令输出
G:\share\qrcode\demo\lib>tesseract gene.font.exp0.tif gene.font.exp0 batch.nochop makebox
Tesseract Open Source OCR Engine v5.0.0-alpha.20200328 with Leptonica
Page 1
Warning: Invalid resolution 1 dpi. Using 70 instead.
Estimating resolution as 184
G:\share\qrcode\demo\lib>tesseract gene.font.exp0.tif gene.font.exp0 nobatch box.train
Tesseract Open Source OCR Engine v5.0.0-alpha.20200328 with Leptonica
Page 1
Warning: Invalid resolution 1 dpi. Using 70 instead.
Estimating resolution as 184
APPLY_BOXES:
Boxes read from boxfile: 16
Found 16 good blobs.
Generated training data for 4 words
G:\share\qrcode\demo\lib>unicharset_extractor gene.font.exp0.box
Extracting unicharset from box file gene.font.exp0.box
Other case a of A is not in unicharset
Other case t of T is not in unicharset
Other case c of C is not in unicharset
Other case g of G is not in unicharset
Wrote unicharset file unicharset
G:\share\qrcode\demo\lib>shapeclustering -F font_properties -U unicharset gene.font.exp0.tr
Failed to load font_properties from font_properties
G:\share\qrcode\demo\lib>shapeclustering -F font_properties -U unicharset gene.font.exp0.tr
Reading gene.font.exp0.tr ...
Building master shape table
Computing shape distances...
Stopped with 0 merged, min dist 999.000000
Computing shape distances...
Stopped with 0 merged, min dist 999.000000
Computing shape distances...
Stopped with 0 merged, min dist 999.000000
Computing shape distances... 0
Stopped with 0 merged, min dist 999.000000
Computing shape distances... 0
Stopped with 0 merged, min dist 999.000000
Computing shape distances... 0
Stopped with 0 merged, min dist 999.000000
Computing shape distances... 0
Stopped with 0 merged, min dist 999.000000
Computing shape distances...
Stopped with 0 merged, min dist 999.000000
Computing shape distances...
Stopped with 0 merged, min dist 999.000000
Computing shape distances... 0 1 2 3
Stopped with 0 merged, min dist 0.280303
Master shape_table:Number of shapes = 4 max unichars = 1 number with multiple unichars = 0
G:\share\qrcode\demo\lib>mftraining -F font_properties -U unicharset -O unicharset gene.font.exp0.tr
Read shape table shapetable of 4 shapes
Reading gene.font.exp0.tr ...
Warning: no protos/configs for Joined in CreateIntTemplates()
Warning: no protos/configs for |Broken|0|1 in CreateIntTemplates()
Done!
G:\share\qrcode\demo\lib>cntraining gene.font.exp0.tr
Reading gene.font.exp0.tr ...
Clustering ...
Writing normproto ...
G:\share\qrcode\demo\lib>combine_tessdata gene.
Combining tessdata files
Output gene.traineddata created successfully.
Version string:v5.0.0-alpha.20200328
1:unicharset:size=387, offset=192
3:inttemp:size=120220, offset=579
4:pffmtable:size=68, offset=120799
5:normproto:size=662, offset=120867
13:shapetable:size=76, offset=121529
23:version:size=21, offset=121605
G:\share\qrcode\demo\lib>linux安装我没成功,但是有些资料供参考
linux安装始终不可,下一步考虑编译安装的方法,看cmake文件修改
原因
因为我的lubuntu用的是libpng16,但由pip装的pytesseract需要12。libpng12.so.0已经过时了,最新的好像是16,用下面的命令搜一下看看。
ls -ld $(locate -r libpng.*\.so.*)参考 https://jingyan.baidu.com/article/fdbd4277d625f9b89e3f482c.html
安装命令
pip install pytesseract
sudo apt-get update
sudo apt-get install tesseract-ocr
sudo apt-get install libtesseract-devUbuntu 报错
dpkg: 处理归档 /var/cache/apt/archives/libpng12-0_1.2.50-1ubuntu2.14.04.3_amd64.deb (--unpack)时出错:
无法安装 /lib/x86_64-linux-gnu/libpng12.so.0 的新版本: No such file or directory
错误信息显示本地系统有一些问题,因此没有写入 apport 报告
在处理时有错误发生:
/var/cache/apt/archives/libpng12-0_1.2.50-1ubuntu2.14.04.3_amd64.deb
E: Sub-process /usr/bin/dpkg returned an error code (1)我试过:拷贝法无用、添加中科院源法无用、fix --install那个也无用
sudo cp /mnt/shared/0921/libpng12.so.0 /usr/lib/x86_64-linux-gnu/
sudo cp /mnt/shared/0921/libpng12.so.0 /lib/x86_64-linux-gnu/