Videos Understanding Dataset
视频理解(Videos Understanding)常见数据集和研究现状
- Dataset
-
-
- 1. KTH (2004)
- 2. Weizmann (2005)
- 3. Hollywood V1/V2 (2008、2009)
- 4. HMDB51 (2011)
- 5. UCF101(2007-2012)
- 6. THUMOS(2014)
- 7. Sports-1M(2014)
- 8. ActivityNet(2015)
- 9. Youtube-8M(2016)
- 10. Charades(2016)
- 12. Kinetics(2017)
- 13. AVA(2017)
- 14. Moments(2018)
- 15. Something Something v1/v2(2019)
- 16. HiEve(2021)
-
- TASK
-
- 1. Video Action Classfication
-
- 裁剪
- 人数
- 2. Temporal Action Dection
-
- 标注困难
- 3. Spatial Temporal Action Detection
- 4. 持续学习
- 5. 动作预测
Dataset
1. KTH (2004)
Link:http://pan.baidu.com/s/1hsuQktA 密码: rfr7
Size:unknow
Class:9类
Brief Description:KTH数据集于2004 年的发布,是计算机视觉领域的一个里程碑。此后,许多新的数据库陆续发布。数据库包括在 4个不同场景下 25 个人完成的 6 类动作(walking, jogging, running,boxing, hand waving and hand clapping)共计 2391个视频样本,是当时拍摄的最大的人体动作数据库,它使得采用同样的输入数据对不同算法的性能作系统的评估成为可能。数据库的视频样本中包含了尺度变化、 衣着变化和光照变化,但其背景比较单一,相机也是固定的。(静态)
SOTA:
2. Weizmann (2005)
Link:https://www.wisdom.weizmann.ac.il/~vision/SpaceTimeActions.html
Size:340MB
Class:9类
Brief Description:2005年,以色列 Weizmann institute 发布了Weizmann 数据库。数据库包含了 10个动作(bend, jack, jump, pjump, run,side, skip, walk, wave1,wave2),每个动作有 9 个不同的样本。视频的视角是固定的,背景相对简单,每一帧中只有 1 个人做动作。数据库中标定数据除了类别标记外还包括:前景的行为人剪影和用于背景抽取的背景序列。(静态)
SOTA:
3. Hollywood V1/V2 (2008、2009)
Link:http://www.di.ens.fr/~laptev/actions/hollywood2/
Size:动作识别15G、场景识别25G
Class:12类
Brief Description:Hollywood(2008年发布)、Hollywood-2数据库是由法国IRISA研究院发布的。早先发布的数据库基本上都是在受控的环境下拍摄的,所拍摄视频样本有限。2009年发布的Hollywood-2是Hollywood数据库的拓展版,包含了 12 个动作类别和 10个场景共3669个样本,所有样本均是从69部 Hollywood 电影中抽取出来的。视频样本中行为人的表情、姿态、穿着,以及相机运动、光照变化、遮挡、背景等变化很大,接近于真实场景下的情况,因而对于行为的分析识别极具挑战性。较早的数据集,数据比较容易获取。样本和类别都较少,研究热度较低。后续还有一个类似的Hollywood Extended数据集,对电影感兴趣的小伙伴可以关注一下。
SOTA:
4. HMDB51 (2011)
Link:http://serre-lab.clps.brown.edu/resource/hmdb-a-large-human-motion-database/#dataset
Size:2G
Class:51类
Brief Description:Brown university大学发布的HMDB51于2011年发布,视频多数来源于电影,还有一部分来自公共数据库以及YouTube等网络视频库。数据库包含有6849段样本,分为51类,每类至少包含有101段样本。和UCF101类似,属于入门级别的数据。数据容易获取且数量较少,容易复现或者验证效果,目前研究热度较高。
SOTA:
5. UCF101(2007-2012)
Link:http://crcv.ucf.edu/data/
Size:6.46G
Class:101类
Brief Description:美国University of central Florida(UCF)自2007年以来发布的一系列数据库:UCF sports action dataset(2008),UCF Youtube(2008),UCF50,UCF101(2012),引起了广泛关注。这些数据库样本来自从 BBC/ESPN的广播电视频道收集的各类运动样本、以及从互联网尤其是视频网站YouTube上下载而来的样本。其中UCF101是目前动作类别数、样本数最多的数据库之一,样本为13320段视频,类别数为101类。属于入门级别的数据。数据容易获取,研究热度较高,但精度已经很高,不好提升。
SOTA:
6. THUMOS(2014)
Link:https://www.crcv.ucf.edu/THUMOS14/download.html
Size:unknow
Class:101类
Brief Description:行为识别任务:它的训练集为UCF101数据集,包括101类动作,共计13320段分割好的视频片段;它的验证集和测试集则分别包括1010和1574个未分割过的视频。时序行为检测任务:只有20类动作的未分割视频是有时序行为片段标注的,包括200个验证集视频(包含3007个行为片段)和213个测试集视频(包含3358个行为片段);这些经过标注的未分割视频可以被用于训练和测试时序行为检测模型。
SOTA:
7. Sports-1M(2014)
Link:https://cs.stanford.edu/people/karpathy/deepvideo/
Size:unknow
Class:487类
Brief Description:Sports-1M来自 YouTube 收集的运动视频数据集,产出时间在2014年,总共包含样本1,133,158个,类别都是体育相关。在Github上提供了youtube的视频ID进行下载。喜欢体育或者从事体育相关项目的朋友可以了解一下,只可惜提供的是youtube的视频ID,国内小伙伴获取较为困难。
SOTA:
8. ActivityNet(2015)
Link:http://activity-net.org/index.html
Size:unknow
Class:200类
Brief Description:ActivityNet是一个大规模行为识别竞赛,自CVPR 2016开始,它侧重于从用户产生的视频中识别出日常生活,面向目标的活动,视频取自互联网视频门户Youtube,类别包括吃东西、做菜、运动等等。注意: 因为ActivityNet是一个比赛,最近几年都会在CVPR上更新challenge(例如近年来的Kinetics-400),我们这里介绍的 是2016年的challenge。后续每年官方还会对版本进行更新。出现较早,逐渐被后续版本所替代;官方提供的是Youtube URL来获取数据,不太容易下载(国内的小伙伴们伤不起);而且样本量也太小了,研究热度一般。
SOTA:
9. Youtube-8M(2016)
Link:https://research.google.com/youtube8m/download.html
Size:约1.5T
Class:4800类
Brief Description:Youtube-8M 从2016年开始出现,刚开始有800万样本,后续逐年更新,样本也越来越少(有可能因为链接失效的原因),2018年的版本训练样本在560万左右,2019还提供了视频片段的标记。官方提供的下载文件格式是tfrecord。这个数据集太大了,做实验的成本太大,学术界近期很少有相关的进展。在Kaggle上面办过比赛,腾讯还拿过名次(上面的第二个方案)。虽然提供的是tfrecord的下载格式,不过下载过程对国内的小伙伴依旧不友好,感兴趣的朋友可以尝试一下。
SOTA:
10. Charades(2016)
Link: https://allenai.org/plato/charades/
Size:多种尺寸13G-76G不等
Class:157类
Brief Description:Charades是2016年通过Amazon Mechanical Turk收集出来的数据,数据集总量在9848个视频片段,主要是一些室内的动作。该数据集既包含video-level的分类,又包含frame-level的分类,近期研究热度较高,数据较容易获取。
SOTA:
12. Kinetics(2017)
Link:https://deepmind.com/research/open-source/kinetics
Kinetics 400:https://opendatalab.org.cn/Kinetics-400/download
Kinetics 600:https://opendatalab.org.cn/Kinetics600/download
Kinetics 700:https://opendatalab.org.cn/Kinetics_700/download
Kinetics-700-2020:https://opendatalab.org.cn/Kinetics_700-2020/download
Size:135G左右(Kinetics 400)
Class:400、600和700类
Brief Description:Kinetics视频来源于YouTube,目前有三个版本,包括400类、600类和700类,分别包含20万、50万和65万个视频。数据集的类别主要分为三大类:人与物互动,比如演奏乐器;人人互动,比如握手、拥抱;运动等。
这个数据集是在2017年的Activity challenge中由DeepMind开始发布出来的数据。当时release出来的时候还搞了个大新闻,被称为是"行为识别领域的ImageNet",顿时感觉又给广大的CV研究者们开了一个新方向。而且同时出现的I3D方法也让3D卷积的研究热度不停拉升,Kinetics数据的预训练确实能够给各类的测试集加成很多,KaiMing大神最近也有几篇相关的工作,足见其影响力。
然而,这里要给国内想要入门的同学一个小提醒,这个数据集真滴是很难拿到(需要科学上网),而且现在还有很多youtube url是失效的,且数量庞大,更难以想象训练一次的成本。hansong 他们团队最近出了一篇文章,说是可以15分钟训练完Kinetics, 看一下论文的inference,发现要1500多个GPU。不过从知乎上看到有人从某鱼上成功获取到了一版数据,好像也不是完整的。
自己做demo训练的话推荐【Tiny-Kinetics-400】Kinetics-400迷你数据集,只有600MB!
SOTA:
13. AVA(2017)
Link: https://research.google.com/ava/
Size:unknow
Class:80个原子动作类别,158多万个动作类别
Brief Description:AVA 数据集包含了80个原子视觉动作,根据动作在空间和时间,产生了158万个动作标签,大约有430个15分钟的视频片段,然后划分clip。标签集合较大,用于Multi-label的行为识别任务,通过提供youtube id来获取数据,研究热度较高。
SOTA:
14. Moments(2018)
Link: http://moments.csail.mit.edu/
Size:unknow
Class: 339类
Brief Description:Moments是由MIT-IBM Watson AI Lab2017年开发的研究项目。该项目致力于构建非常大规模的数据集,以帮助AI系统识别和理解视频中的动作和事件。总共有1million 的视频片段,每个片段3秒钟。包括人、动物、物体或自然现象。专注动作本身,例如opening,张开嘴巴,开门等。研究难度较大,研究热度较低,获取方式需要个人和研究机构的信息,数据大小未知。
SOTA:
15. Something Something v1/v2(2019)
Link: https://20bn.com/datasets/something-something
Size:20G
Class:174类
Brief Description:Something Something数据集是大量带有密集标签的视频剪辑的集合,这些视频剪辑显示人类对日常对象(剪刀、杯子等等)执行预定义的基本动作,视频总量在22万以上,可免费用于学术研究。数据量适中,研究热度较高,但是精度很难做上去,有可能是因为他的视频内容的关系。看了几个视频发现很多动作都很奇怪,比如倒水倒不进杯子里等。
SOTA:
16. HiEve(2021)
Link: http://humaninevents.org 或 https://gas.graviti.cn/dataset/hello-dataset/HiEve
Size:unknow
Class:14类
Brief Description:一个新的大规模数据集,用于理解各种现实事件中的人体动作,姿势和动作,尤其是人群和复杂事件。在YouTube上收集了一些异常场景(如监狱)和异常事件(如打斗、地震) 共32个视频序列,大多超过900帧,总长度33分18秒,分为训练和测试集的19和13个视频精心制作。数据集包含9个不同的场景。
SOTA:
TASK
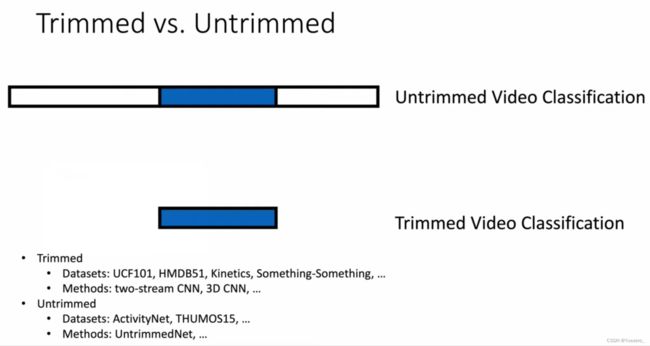
1. Video Action Classfication
What:输出 class_label

裁剪
视频片段是否经过手工裁剪:未经过裁剪的方法需要排除不相干的干扰片段。
人数
多人视频比单人视频多了人与人的交互

2. Temporal Action Dection
What+When:输出 [class_label, start_end_timesteps]

标注困难
收集标注长视频数据是困难的,这启发人们做weakly supervised learning

3. Spatial Temporal Action Detection
What+When+Where:输出 [class_label, bbox, start_end_time]

4. 持续学习
online模型可以从已经看到过的样例中学习

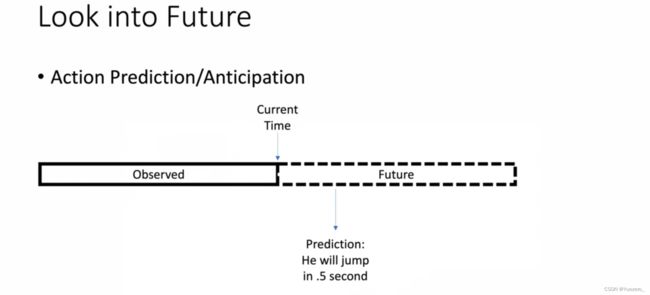
5. 动作预测
根据看过的部分视频片段预测后面的内容