LLMs之Baichuan 2:《Baichuan 2: Open Large-scale Language Models》翻译与解读
LLMs之Baichuan 2:《Baichuan 2: Open Large-scale Language Models》翻译与解读
导读:2023年9月6日,百川智能重磅发布Baichuan 2。科技论文主要介绍了Baichuan 2,一个开源的大规模语言模型,以及其在多个领域的性能表现和安全性措施。论文强调了对开源模型的重要性,特别是对于非英语语言的研究者和应用程序开发者。此外,论文还详细讨论了模型的预训练、微调和安全性方面的技术细节。Baichuan 2包含两个模型—Baichuan 2-7B和Baichuan 2-13B。两个模型都在2.6T的tokens上进行预训练,这是迄今为止规模最大的。Baichuan 2在通用基准测试上表现优于Baichuan 1和其他开源模型。
预训练:数据来源广泛,处理2.6T的tokens。模型架构基于Transformer,对位置编码和训练优化进行了改进。
对齐:采用监督预训练和强化学习从人类反馈中获得的方法对模型进行对齐,获得Baichuan 2-7B-Chat和Baichuan 2-13B-Chat两个会话模型。
安全性:从预训练到对齐各个阶段都采取措施提升模型安全性,比对与LLaMA 2表现出一定优势。
评估:Baichuan 2在通用测评、专业领域、数学编程、多语言等多个维度展现出优异表现。同时提供中间检查点供研究训练动力学。
限制与倡导:论述了Baichuan 2在安全性、偏差、知识滞后等方面存在的困难,并强调合理和负责任的使用。
总体来看,该技术报告系统介绍了Baichuan 2的训练方法及各项性能,在开源与透明度上做出了贡献。
文章总结与解读持续更新中……
目录
相关文章
LLMs之Baichuan:Baichuan-13B模型的简介(包括Baichuan-7B)、安装、使用方法之详细攻略
LLMs之Baichuan 2:Baichuan 2的简介、安装、使用方法之详细攻略
LLMs之Baichuan 2:《Baichuan 2: Open Large-scale Language Models》翻译与解读
《Baichuan 2: Open Large-scale Language Models》翻译与解读
Abstract摘要
指令微调可大幅度降低FE的需求,强模型的闭源性+非英语能力有限性→提出开源Baichuan 2=拥有7B/13B参数+基于2.6T的tokens+公共基准优秀+垂直领域出色
1 Introduction引言
语言模型规模的发展趋势【理解+生成】:参数(数百万【ELMo/GPT-1】→数十~万亿【GPT-3/PaLM/Switch Transformers】)、LM性能的提升(像人类流利+具备多种NLP任务)、ChatGPT带来突破性进展
大多数领先LLMs均都闭源(GPT-4/Claude)→研究人员难以深入研究,而LLaMA等开源模型促进开源的发展→从而加速了该base模型发展(如Alpaca/Vicuna)
当前困境:大多开源LLMs的语料主要是英文,导致对中文不友好
本文提出Baichuan 2=有两个模型(7B/13B参数)+基于2.6T的token数据+通用基准测试提高了30%(其中数学和代码领域翻倍)+专业领域也出色(医学和法律)
本报告还发布了两个聊天模型(Baichuan 2-7B-Chat和Baichuan 2-13B-Chat),并发现7B模型基于2.6T的数据性能依旧会提高
2 Pre-training预训练
Table 1: Overall results of Baichuan 2 compared with other similarly sized LLMs on general benchmarks. * denotes results derived from official websites.
2.1 Pre-training Data预训练数据
数据收集(目标-可扩展性+代表性,多种来源-世界知识系统)
数据处理(构建高效的大规模去重和聚类系统)
Figure 1: The distribution of different categories of Baichuan 2 training data.
Figure 2: The data processing procedure of Baichuan 2’s pre-training data.
Raw corpus→精确去重→启发式方法→逐句质量筛选→逐句、逐段去重→文档级别去重
2.2 Architecture架构:基于主流的Transformer修改而来
2.3 Tokenizer分词器
需要平衡的两个因素:高压缩率、词汇表(6.4W→12.56W,采用BPE+数字数据单独标记+代码数据加空格标记)
Table 2: The vocab size and text compression rate of Baichuan 2’s tokenizer compared with other models. The lower the better.
2.3.1 Positional Embeddings位置嵌入—类似Baichuan 1模型:Baichuan 2-7B采用RoPE(更适合Flash Attention)、Baichuan 2-13B采用ALiBi
2.4 Activations and Normalizations激活函数和标准化:采用SwiGLU+xFormers(注意力和偏差能力结合ALiBi减少内存开销)+RMSNorm(层归一化Transformer块的输入)
2.5 Optimizations
采用AdamW(2000个线性缩放后升温→余弦衰减到最小学习率)
Table 3: Model details of Baichuan 2.
混合精度(BFloat16有更好的动态范围)
NormHead(对输出嵌入归一化)两优点:显著稳定训练动态+减轻计算logits时L2距离的干扰
Max-z loss:规范logits助于稳定训练
Figure 3: The pre-training loss of Baichuan 2.
2.6 Scaling Laws缩放定律(保证高训练成本的高性能):通过逐个训练(10M~3B)小模型拟合缩放定律
Figure 4: The scaling law of Baichuan 2. We trained various models ranging from 10 million to 3 billion parameters with 1 trillion tokens. By fitting a power law term to the losses given training flops, we predicted losses for training Baichuan 2-7B and Baichuan 2-13B on 2.6 trillion tokens. This fitting process precisely predicted the final models’ losses (marked with two stars).
2.7 Infrastructure基础设施:
一种高效利用GPU资源的联合设计(弹性训练框架【张量并行+基于ZeRO共享的数据并行】+智能集群调度策略【任务的资源可根据集群状态动态修改】)、张量分割技术(减少内存峰值消耗)
混合精度训练(BFloat16中前后向计算+Float32中执行优化器更新):
两大技术避免降低通信效率:拓扑感知分布式训练+ ZeRO混合分层分区设计
整合以上策略实现1024个A800来高效训练Baichuan 2
3 Alignment对齐=SFT+RLHF(RM+RL)
3.1 Supervised Fine-Tuning监督微调:基于10万监督微调样本+人工标记器执行注释+交叉验证(权威标注员校验)
Figure 5: An illustration of Baichuan 2’s RLHF process.
3.2 Reward Model奖励模型:三级分类系统(6/30/200)
Table 4: Reward Model test accuracy on different score gaps of two responses. The larger the response gap, the better RM accuracy. The gap 1,2,3,4,5 correspond to unsure, negligibly better, slightly better, better, and significantly better, respectively.
3.3 PPO(训练LM):采用四模型(参与者+参考模型+奖励模型+批评模型)
3.4 Training Details训练细节
4 Safety安全性
4.1 Pre-training Stage预训练阶段:设计了一套规则和模型过滤有害内容+策划了一个中英双语数据集
4.2 Alignment Stage对齐阶段:红队流程(6种和100+粒度),专家标注团队(20万个攻击提示)+多值监督采样方法+DPO+采用有益和无害目标相结合的奖励模型
5 Evaluations评估
5.1 Overall Performance总体性能
5.2 Vertical Domain Evaluations垂直领域评估
5.3 Math and Code数学和代码
5.4 Multilingual多语言
5.5 Safety Evaluations
Table 5: The result of Baichuan 2 compared with other models on law and medical filed.
Table 6: The result of Baichuan 2 compared with other models on mathematics and coding.
Table 7: The result of Baichuan 2 compared with other models on multilingual field.
5.6 Intermediate Checkpoints中间检查点
6 Related Work相关工作
Table 9: The result of different chat models on our safety evaluation benchmarks.
Figure 7: The results of intermediary checkpoints of Baichuan 2-7B which will be released to the public.
7 Limitations and Ethical Considerations限制和道德考虑
References
相关文章
LLMs之Baichuan:Baichuan-13B模型的简介(包括Baichuan-7B)、安装、使用方法之详细攻略
LLMs之Baichuan:Baichuan-13B模型的简介(包括Baichuan-7B)、安装、使用方法之详细攻略_一个处女座的程序猿的博客-CSDN博客
LLMs之Baichuan 2:Baichuan 2的简介、安装、使用方法之详细攻略
https://yunyaniu.blog.csdn.net/article/details/132748260
LLMs之Baichuan 2:《Baichuan 2: Open Large-scale Language Models》翻译与解读
LLMs之Baichuan 2:《Baichuan 2: Open Large-scale Language Models》翻译与解读_一个处女座的程序猿的博客-CSDN博客
《Baichuan 2: Open Large-scale Language Models》翻译与解读
| 地址 |
技术报告:https://cdn.baichuan-ai.com/paper/Baichuan2-technical-report.pdf GitHub官网:GitHub - baichuan-inc/Baichuan2: A series of large language models developed by Baichuan Intelligent Technology |
| 时间 |
2023年9月6日 |
| 作者 |
百川智能 |
Abstract摘要
指令微调可大幅度降低FE的需求,强模型的闭源性+非英语能力有限性→提出开源Baichuan 2=拥有7B/13B参数+基于2.6T的tokens+公共基准优秀+垂直领域出色
| Large language models (LLMs) have demonstrated remarkable performance on a variety of natural language tasks based on just a few examples of natural language instructions, reducing the need for extensive feature engineering. However, most powerful LLMs are closed-source or limited in their capability for languages other than English. In this technical report, we present Baichuan 2, a series of large-scale multilingual language models containing 7 billion and 13 billion parameters, trained from scratch, on 2.6 trillion tokens. Baichuan 2 matches or outperforms other open-source models of similar size on public benchmarks like MMLU, CMMLU, GSM8K, and HumanEval. Furthermore, Baichuan 2 excels in vertical domains such as medicine and law. We will release all pre-training model checkpoints to benefit the research community in better understanding the training dynamics of Baichuan 2. |
大型语言模型(LLMs)已经在各种自然语言任务上展现出卓越的性能,仅凭自然语言指令的少数示例,减少了对广泛特征工程的需求。然而,大多数强大的LLMs都是闭源或在英语以外的其他语言上的能力有限。在这份技术报告中,我们介绍了Baichuan 2,一个包含70亿和130亿参数的大规模多语言语言模型系列,从零开始训练,使用了2.6万亿个token。Baichuan 2在公共基准测试如MMLU、CMMLU、GSM8K和HumanEval上与其他开源模型相当或表现更好。此外,Baichuan 2在医学和法律等垂直领域也表现出色。我们将发布所有的预训练模型检查点,以有助于研究社区更好地理解Baichuan 2的训练动态。 |
1 Introduction引言
语言模型规模的发展趋势【理解+生成】:参数(数百万【ELMo/GPT-1】→数十~万亿【GPT-3/PaLM/Switch Transformers】)、LM性能的提升(像人类流利+具备多种NLP任务)、ChatGPT带来突破性进展
| The field of large language models has witnessed promising and remarkable progress in recent years. The size of language models has grown from millions of parameters, such as ELMo (Peters et al., 1802), GPT-1 (Radford et al., 2018), to billions or even trillions of parameters such as GPT- 3 (Brown et al., 2020), PaLM (Chowdhery et al., 2022; Anil et al., 2023) and Switch Transformers (Fedus et al., 2022). This increase in scale has led to significant improvements in the capabilities of language models, enabling more human-like fluency and the ability to perform a diverse range of natural language tasks. With the introduction of ChatGPT (OpenAI, 2022) from OpenAI, the power of these models to generate human-like text has captured widespread public attention. ChatGPT demonstrates strong language proficiency across a variety of domains, from conversing casually to explaining complex concepts. This breakthrough highlights the potential for large language models to automate tasks involving natural language generation and comprehension. |
大型语言模型领域近年来取得了令人兴奋和显著的进展。语言模型的规模从数百万参数,如ELMo(Peters等,1802年)、GPT-1(Radford等,2018年),扩展到了数十亿甚至数万亿参数,如GPT-3(Brown等,2020年)、PaLM(Chowdhery等,2022年;Anil等,2023年)和Switch Transformers(Fedus等,2022年)。这种规模的增加带来了语言模型性能的显著提升,使其能够更像人类一样流利,并具备执行多种自然语言任务的能力。随着OpenAI推出的ChatGPT(OpenAI,2022年),这些模型生成类似人类的文本的能力引起了广泛的公众关注。ChatGPT在各种领域表现出了强大的语言能力,从随意交谈到解释复杂概念都游刃有余。这一突破突显出大型语言模型自动化处理涉及自然语言生成和理解的任务的潜力。 |
大多数领先LLMs均都闭源(GPT-4/Claude)→研究人员难以深入研究,而LLaMA等开源模型促进开源的发展→从而加速了该base模型发展(如Alpaca/Vicuna)
| While there have been exciting breakthroughs and applications of LLMs, most leading LLMs like GPT-4 (OpenAI, 2023), PaLM-2 (Anil et al., 2023), and Claude (Claude, 2023) remain closed-sourced. Developers and researchers have limited access to the full model parameters, making it difficult for the community to deeply study or fine-tune these systems. More openness and transparency around LLMs could accelerate research and responsible development within this rapidly advancing field. LLaMA (Touvron et al., 2023a), a series of large language models developed by Meta containing up to 65 billion parameters, has significantly benefited the LLM research community by being fully open- sourced. The open nature of LLaMA, along with other open-source LLMs such as OPT (Zhang et al., 2022), Bloom (Scao et al., 2022), MPT (MosaicML, 2023) and Falcon (Penedo et al., 2023), enables researchers to freely access the models for examination, experimentation, and further development. This transparency and access distinguishes LLaMA from other proprietary LLMs. By providing full access, the open-source LLMs have accelerated research and advances in the field, leading to new models like Alpaca (Taori et al., 2023), Vicuna (Chiang et al., 2023), and others (Wang et al., 2022; Zhu et al., 2023; Anand et al., 2023). |
尽管LLMs取得了令人兴奋的突破和应用,但大多数领先的LLMs,如GPT-4(OpenAI,2023年)、PaLM-2(Anil等,2023年)和Claude(Claude,2023年)仍是闭源的。开发人员和研究人员无法完全访问完整的模型参数,使得研究社区难以深入研究或微调这些系统。在这个快速发展的领域,更多关于LLMs的开放性和透明性可能会加速研究和负责任的发展。LLaMA (Touvron et al., 2023a)是Meta开发的一系列包含多达650亿个参数的大型语言模型,其完全开源为LLM研究社区带来了显著的好处。LLaMA的开放性质,以及其他开源LLMs如OPT(Zhang等,2022年)、Bloom(Scao等,2022年)、MPT(MosaicML,2023年)和Falcon(Penedo等,2023年)使研究人员可以自由访问这些模型进行检查、实验和进一步的开发。这种透明度和访问性将LLaMA与其他专有LLMs区分开来。通过提供完全访问,开源LLMs已经加速了该领域的研究和进展,导致了新模型如Alpaca(Taori等,2023年)、Vicuna(Chiang等,2023年)以及其他模型的出现(Wang等,2022年;Zhu等,2023年;Anand等,2023年)。 |
当前困境:大多开源LLMs的语料主要是英文,导致对中文不友好
| However, most open-source large language models have focused primarily on English. For instance, the main data source for LLaMA is Common Crawl1, which comprises 67% of LLaMA’s pre-training data but is filtered to English content only. Other open source LLMs such as MPT (MosaicML, 2023) and Falcon (Penedo et al.,2023) are also focused on English and have limited capabilities in other languages. This hinders the development and application of LLMs in specific languages, such as Chinese. |
然而,大多数开源的大型语言模型主要集中在英语上。例如,LLaMA的主要数据来源是Common Crawl1,占据了LLaMA预训练数据的67%,但只过滤到英语内容。其他开源LLMs,如MPT(MosaicML,2023年)和Falcon(Penedo等人,2023年),也专注于英语,对其他语言的支持能力有限。这制约了在特定语言(如中文)中开发和应用LLMs的发展。 |
本文提出Baichuan 2=有两个模型(7B/13B参数)+基于2.6T的token数据+通用基准测试提高了30%(其中数学和代码领域翻倍)+专业领域也出色(医学和法律)
| In this technical report, we introduce Baichuan 2, a series of large-scale multilingual language models. Baichuan 2 has two separate models, Baichuan 2-7B with 7 billion parameters and Baichuan 2-13B with 13 billion parameters. Both models were trained on 2.6 trillion tokens, which to our knowledge is the largest to date, more than double that of Baichuan 1 (Baichuan, 2023b,a). With such a massive amount of training data, Baichuan 2 achieves significant improvements over Baichuan 1. On general benchmarks like MMLU (Hendrycks et al., 2021a), CMMLU (Li et al., 2023), and C-Eval (Huang et al., 2023), Baichuan 2-7B achieves nearly 30% higher performance compared to Baichuan 1-7B. Specifically, Baichuan 2 is optimized to improve performance on math and code problems. On the GSM8K (Cobbe et al., 2021) and HumanEval (Chen et al., 2021) evaluations, Baichuan 2 nearly doubles the results of the Baichuan 1. In addition, Baichuan 2 also demonstrates strong performance on medical and legal domain tasks. On benchmarks such as MedQA (Jin et al., 2021) and JEC-QA (Zhong et al., 2020), Baichuan 2 outperforms other open- source models, making it a suitable foundation model for domain-specific optimization. |
在本技术报告中,我们介绍了Baichuan 2,这是一系列大规模多语言语言模型。Baichuan 2有两个独立的模型,Baichuan 2-7B具有70亿参数,Baichuan 2-13B具有130亿参数。这两个模型都经过了2.6万亿令牌的训练,据我们所知,这是迄今为止最大规模的训练数据,是Baichuan 1(Baichuan,2023b,a)的两倍多。由于这么大规模的训练数据,Baichuan 2在Baichuan 1的基础上取得了显著的改进。在像MMLU(Hendrycks等人,2021a)、CMMLU(Li等人,2023年)和C-Eval(Huang等人,2023年)这样的通用基准测试中,Baichuan 2-7B的性能几乎比Baichuan 1-7B提高了30%。具体而言,Baichuan 2经过优化,以提高数学和代码问题的性能。在GSM8K(Cobbe等人,2021年)和HumanEval(Chen等人,2021年)评估中,Baichuan 2几乎使Baichuan 1的结果翻倍。此外,Baichuan 2在医学和法律领域的任务中也表现出色。在MedQA(Jin等人,2021年)和JEC-QA(Zhong等人,2020年)等基准测试上,Baichuan 2胜过其他开源模型,使其成为适合领域特定优化的基础模型。 |
本报告还发布了两个聊天模型(Baichuan 2-7B-Chat和Baichuan 2-13B-Chat),并发现7B模型基于2.6T的数据性能依旧会提高
| Additionally, we also released two chat models, Baichuan 2-7B-Chat and Baichuan 2- 13B-Chat, optimized to follow human instructions. These models excel at dialogue and context understanding. We will elaborate on our approaches to improve the safety of Baichuan 2. By open-sourcing these models, we hope to enable the community to further improve the safety of large language models, facilitating more research on responsible LLMs development. Furthermore, in spirit of research collaboration and continuous improvement, we are also releasing the checkpoints of Baichuan 2 at various stages of training from 200 billion tokens up to the full 2.6 trillion tokens. We found that even for the 7 billion parameter model, performance continued to improve after training on more than 2.6 trillion tokens. By sharing these intermediary results, we hope to provide the community with greater insight into the training dynamics of Baichuan 2. Understanding these dynamics is key to unraveling the inner working mechanism of large language models (Biderman et al., 2023a; Tirumala et al., 2022). We believe the release of these checkpoints will pave the way for further advances in this rapidly developing field. |
此外,我们还发布了两个聊天模型,Baichuan 2-7B-Chat和Baichuan 2-13B-Chat,经过优化以遵循人类指令。这些模型擅长对话和上下文理解。我们将详细介绍改进Baichuan 2安全性的方法。通过开源这些模型,我们希望能够使社区进一步改进大型语言模型的安全性,促进更多负责任的LLMs开发的研究。 此外,为了促进研究合作和持续改进,我们还发布了Baichuan 2在从2000亿token到完整的2.6万亿token的各个训练阶段的检查点。我们发现,即使对于70亿参数模型,训练超过2.6万亿令牌后,性能仍然会持续提高。通过分享这些中间结果,我们希望为社区提供更深入了解Baichuan 2训练动态的见解。了解这些动态对于揭示大型语言模型的内部工作机制(Biderman等人,2023a;Tirumala等人,2022年)至关重要。我们相信这些检查点的发布将为这个快速发展的领域带来更进一步的进展。 |
| In this technical report, we will also share some of the trials, errors, and lessons learned through training Baichuan 2. In the following sections, we will present detailed modifications made to the vanilla Transformer architecture and our training methodology. We will then describe our fine-tuning methods to align the foundation model with human preferences. Finally, we will benchmark the performance of our models against other LLMs on a set of standard tests. Throughout the report, we aim to provide transparency into our process, including unsuccessful experiments, to advance collective knowledge in developing LLMs. Baichuan 2’s foundation models and chat models are available for both research and commercial use at https://github.com/ baichuan-inc/Baichuan2. |
在本技术报告中,我们还将分享训练Baichuan 2时的一些尝试、错误和经验教训。在接下来的章节中,我们将介绍对基础Transformer架构进行的详细修改以及我们的训练方法。然后,我们将描述与人类偏好对齐的微调方法。最后,我们将在一组标准测试上对我们的模型的性能进行基准测试。在整个报告中,我们旨在提供关于我们的过程的透明度,包括不成功的实验,以推动LLMs的开发方面的集体知识。Baichuan 2的基础模型和聊天模型可供研究和商业用途使用,网址为https://github.com/baichuan-inc/Baichuan2。 |
2 Pre-training预训练
| This section introduces the training procedure for the Baichuan 2 foundation models. Before diving into the model details, we first show the overall performance of the Baichuan 2 base models compared to other open or closed-sourced models in Table 1. We then describe our pre-training data and data processing methods. Next, we elaborate on the Baichuan 2 architecture and scaling results. Finally, we describe the distributed training system. |
本节介绍了Baichuan 2基础模型的训练过程。在深入介绍模型细节之前,我们首先在表1中展示了Baichuan 2基础模型与其他开源或封闭源模型的整体性能比较。然后,我们描述了我们的预训练数据和数据处理方法。接下来,我们详细介绍了Baichuan 2的架构和扩展结果。最后,我们描述了分布式训练系统。 |
Table 1: Overall results of Baichuan 2 compared with other similarly sized LLMs on general benchmarks. * denotes results derived from official websites.
表1:Baichuan 2与其他类似规模的LLMs在通用基准测试上的整体结果。*表示来自官方网站的结果。

2.1 Pre-training Data预训练数据
数据收集(目标-可扩展性+代表性,多种来源-世界知识系统)
数据处理(构建高效的大规模去重和聚类系统)
| Data sourcing: During data acquisition, our objective is to pursue comprehensive data scalability and representativeness. We gather data from diverse sources including general internet webpages, books, research papers, codebases, and more to build an extensive world knowledge system. The composition of the training corpus is shown in Figure 1. Data processing: For data processing, we focus on data frequency and quality. Data frequency relies on clustering and deduplication. We built a large-scale deduplication and clustering system supporting both LSH-like features and dense embedding features. This system can cluster and deduplicate trillion-scale data within hours. Based on the clustering, individual documents,paragraphs, and sentences are deduplicated and scored. Those scores are then used for data sampling in pre-training. The size of the training data at different stages of data processing is shown in Figure 2. |
数据收集:在数据采集过程中,我们的目标是追求全面的数据可扩展性和代表性。我们从各种来源收集数据,包括互联网网页、书籍、研究论文、代码库等,以构建一个广泛的世界知识系统。训练语料库的组成如图1所示。 数据处理:对于数据处理,我们关注数据的频率和质量。数据频率依赖于聚类和去重。我们建立了一个支持LSH-like特征和密集嵌入特征的大规模去重和聚类系统。这个系统可以在几小时内对万亿级别的数据进行聚类和去重。在聚类的基础上,单个文档、段落和句子被去重复并打分。然后将这些分数用于预训练中的数据采样。不同数据处理阶段的训练数据规模如图2所示。 |
Figure 1: The distribution of different categories of Baichuan 2 training data.
图1:Baichuan 2训练数据的不同类别分布。

Figure 2: The data processing procedure of Baichuan 2’s pre-training data.
图2:Baichuan 2预训练数据的数据处理过程。

Raw corpus→精确去重→启发式方法→逐句质量筛选→逐句、逐段去重→文档级别去重
Raw corpus→Exact deduplication精确去重→Heuristic approach启发式方法→Sent-wise quality filter逐句质量筛选→Sent-wise,paragraph-wise deduplication逐句、逐段去重→Document-wise deduplication文档级别去重
2.2 Architecture架构:基于主流的Transformer修改而来
| The model architecture of Baichuan 2 is based on the prevailing Transformer (Vaswani et al., 2017). Nevertheless, we made several modifications which we detailed below. |
Baichuan 2的模型架构基于主流的Transformer(Vaswani等人,2017)。然而,我们进行了一些详细的修改,如下所述。 |
2.3 Tokenizer分词器
需要平衡的两个因素:高压缩率、词汇表(6.4W→12.56W,采用BPE+数字数据单独标记+代码数据加空格标记)
| A tokenizer needs to balance two critical factors: a high compression rate for efficient inference, and an appropriately sized vocabulary to ensure adequate training of each word embedding. We have taken both these aspects into account. We have expanded the vocabulary size from 64,000 in Baichuan 1 to 125,696, aiming to strike a balance between computational efficiency and model performance. We use byte-pair encoding (BPE) (Shibata et al., 1999) from SentencePiece (Kudo and Richardson, 2018) to tokenize the data. Specifically, we do not apply any normalization to the input text and we do not add a dummy prefix as in Baichuan 1. We split numbers into individual digits to better encode numeric data. To handle code data containing extra whitespaces, we add whitespace-only tokens to the tokenizer. The character coverage is set to 0.9999, with rare characters falling back to UTF-8 bytes. We set the maximum token length to 32 to account for long Chinese phrases. The training data for the Baichuan 2 tokenizer comes from the Baichuan 2 pre-training corpus, with more sampled code examples and academic papers to improve coverage (Taylor et al., 2022). Table 2 shows a detailed comparison of Baichuan 2’s tokenizer with others. |
分词器需要平衡两个关键因素:高效推理的高压缩率和适当大小的词汇表,以确保对每个词嵌入进行充分的训练。我们考虑了这两个方面。入进行充分的训练。这两个方面我们都考虑到了。为了在计算效率和模型性能之间取得平衡,我们将词汇表大小从Baichuan 1的64,000扩展到125,696。 我们使用了来自SentencePiece的字节对编码(BPE)(Shibata等人,1999年)对数据进行分词。具体来说,我们没有对输入文本应用任何归一化,并且不像Baichuan 1那样添加虚拟前缀。我为了更好地编码数字数据,我们将数字分成单独的数字。为了处理包含额外空格的代码数据,我们向分词器添加了仅包含空格的标记。字符覆盖率设置为0.9999,罕见字符返回到UTF-8字节。 我们将最大令牌长度设置为32,以考虑长的中文短语。Baichuan 2分词器的训练数据来自Baichuan 2预训练语料库,其中包含更多的样本代码示例和学术论文以提高覆盖率(Taylor等人,2022年)。表2显示了Baichuan 2的分词器与其他模型的详细比较。 |
Table 2: The vocab size and text compression rate of Baichuan 2’s tokenizer compared with other models. The lower the better.
表2:Baichuan 2的分词器的词汇大小和文本压缩率与其他模型的比较。数字越小越好。

2.3.1 Positional Embeddings位置嵌入—类似Baichuan 1模型:Baichuan 2-7B采用RoPE(更适合Flash Attention)、Baichuan 2-13B采用ALiBi
| Building on Baichuan 1, we adopt Rotary Positional Embedding (RoPE) (Su et al., 2021) for Baichuan 2-7B and ALiBi (Press et al., 2021) for Baichuan 2-13B. ALiBi is a more recent positional encoding technique that has shown improved extrapolation performance. However, most open-sourced models use RoPE for positional embeddings, and optimized attention implementations like Flash Attention (Dao et al., 2022; Dao, 2023) are currently better suited to RoPE since it is multiplication-based, bypassing the need for passing attention_mask to the attention operation. Nevertheless, in preliminary experiments, the choice of positional embedding did not significantly impact model performance. To enable further research on bias-based and multiplication-based attention, we apply RoPE on Baichuan 2-7B and ALiBi on Baichuan 2-13B, consistent with Baichuan 1. |
在Baichuan 1的基础上,我们为Baichuan 2-7B采用了旋转位置嵌入 (RoPE)(Su等人,2021年),而对于Baichuan 2-13B,采用了ALiBi(Press等人,2021年)。ALiBi是一种较新的位置编码技术,已经显示出了改进的外推性能。然而,大多数开源模型使用RoPE来进行位置嵌入,并且像Flash Attention(Dao等人,2022年;Dao,2023年)这样的优化的注意力实现目前更适合RoPE,因为它是基于乘法的,无需将attention_mask传递给attention操作。然而,在初步实验中,位置嵌入的选择并没有显著影响模型性能。为了进一步研究基于偏差的和基于乘法的注意力,我们在Baichuan 2-7B上应用RoPE,在Baichuan 2-13B上应用ALiBi,与Baichuan 1保持一致。 |
2.4 Activations and Normalizations激活函数和标准化:采用SwiGLU+xFormers(注意力和偏差能力结合ALiBi减少内存开销)+RMSNorm(层归一化Transformer块的输入)
| We use SwiGLU (Shazeer, 2020) activation function, a switch-activated variant of GLU (Dauphin et al., 2017) which shows improved results. However, SwiGLU has a “bilinear” layer and contains three parameter matrices, differing from the vanilla Transformer’s feed-forward layer that has two matrices, so we reduce the hidden size from 4 times the hidden size to 8 hidden size and rounded to the multiply of 128. For the attention layer of Baichuan 2, we adopt the memory efficient attention (Rabe and Staats, 2021) implemented by xFormers2. By leveraging xFormers’ optimized attention with biasing capabilities, we can efficiently incorporate ALiBi’s bias-based positional encoding while reducing memory overhead. This provides performance and efficiency benefits for Baichuan 2’s large-scale training. We apply Layer Normalization (Ba et al., 2016) to the input of the Transformer block which is more robust to the warm-up schedule (Xiong et al., 2020). In addition, we use the RMSNorm implementation introduced by (Zhang and Sennrich, 2019), which only calculates the variance of input features to improve efficiency. |
我们使用SwiGLU(Shazeer,2020年)激活函数,这是GLU(Dauphin等人,2017年)的一种开关激活变体,显示出改进的结果。然而,SwiGLU具有“双线性”层,并包含三个参数矩阵,与传统的包含两个矩阵的Transformer前馈层不同,因此我们将隐藏大小从隐藏大小的4倍减少到隐藏大小的8倍,并四舍五入到128的乘法。 对于Baichuan 2的注意力层,我们采用了xFormers2实现的内存高效的注意力(Rabe和Staats,2021年)。通过利用xFormers的优化注意力和偏差能力,我们可以高效地将ALiBi的基于偏差的位置编码整合到模型中,同时减少内存开销。这为Baichuan 2的大规模训练提供了性能和效率上的优势。 我们对Transformer块的输入应用层归一化(Ba等人,2016年),这对于预热计划(Xiong等人,2020年)更加稳健。此外,我们使用了Zhang和Sennrich(2019年)引入的RMSNorm实现,它只计算输入特征的方差,以提高效率。 |
2.5 Optimizations
采用AdamW(2000个线性缩放后升温→余弦衰减到最小学习率)
Table 3: Model details of Baichuan 2.
表3:Baichuan 2的模型详细信息。

混合精度(BFloat16有更好的动态范围)
| The whole models are trained using BFloat16 mixed precision. Compared to Float16, BFloat16 has a better dynamic range, making it more robust to large values that are critical in training large language models. However, BFloat16’s low precision causes issues in some settings. For instance, in some public RoPE and ALibi implementations, the torch.arange operation fails due to collisions when the integer exceeds 256, preventing differentiation of nearby positions. Therefore, we use full precision for some value-sensitive operations such as positional embeddings. |
整个模型使用BFloat16混合精度进行训练。与Float16相比,BFloat16具有更好的动态范围,使其对大值更具鲁棒性,这对于训练大型语言模型至关重要(更稳定)。然而,BFloat16的低精度在某些情况下会引发问题。例如,在一些公共的RoPE和ALibi实现中,当整数超过256时,torch.arange操作会失败,导致附近位置的差异化无法进行。因此,对于一些敏感于数值的操作,如位置嵌入,我们使用全精度。 |
NormHead(对输出嵌入归一化)两优点:显著稳定训练动态+减轻计算logits时L2距离的干扰
| NormHead: To stabilize training and improve the model performance, we normalize the output embeddings (which are also referred as ‘head’). There are two advantages of NormHead in our experiment. First, in our preliminary experiments we found that the norm of the head are prone to be unstable. The norm of the rare token’s embedding becomes smaller during training which disturb the training dynamics. NormHead can stabilize the dynamics significantly. Second, we found that the semantic information is mainly encoded by the cosine similarity of Embedding rather than L2 distance. Since the current linear classifier computes logits by dot product, which is a mixture of L2 distance and cosine similarity. NormHead alleviates the distraction of L2 distance in computing logits. For more details, please refer appendix C. |
NormHead:为了稳定训练并提高模型性能,我们对输出嵌入(也称为“head”)进行了归一化。NormHead在我们的实验中具有两个优点。首先,在我们的初步实验中,我们发现头部的范数容易不稳定。在训练过程中,稀有token的嵌入范数变小,扰乱了训练动态。NormHead可以显著稳定动态。其次,我们发现语义信息主要通过嵌入的余弦相似性而不是L2距离进行编码。由于当前的线性分类器通过点积计算logits,这是L2距离和余弦相似性的混合。NormHead减轻了在计算logits时L2距离的干扰。有关更多详细信息,请参阅附录C。 |
Max-z loss:规范logits助于稳定训练
| Max-z loss: During training, we found that the logits of LLMs could become very large. While the softmax function is agnostic to the absolute logit values, as it depends only on their relative values. Large logits caused issues during inference because common implementations of repetition penalty (such as the Hugging Face implementation3 in model.generate) apply a scalar (e.g. 1.1or 1.2) directly to the logits. Contracting very large logits in this way can significantly alter the probabilities after softmax, making the model sensitive to the choice of repetition penalty hyper-parameter. Inspired by NormSoftmax (Jiang et al., 2023b) and the auxiliary z-loss from PaLM (Chowdhery et al., 2022), we added a max-z loss to normalize the logits:
where z is the maximum logit value. This helped stabilize training and made the inference more robust to hyper-parameters. The final training loss of Baichuan 2-7B and Baichuan 2-13B are shown in Figure 3. |
Max-z loss:在训练过程中,我们发现LLMs的logits可能变得非常大。虽然softmax函数不关心logits的绝对值,因为它仅依赖于它们的相对值。但大的logits在推理过程中会引发问题,因为常见的重复惩罚实现(例如model.generate中的Hugging Face实现)会直接将标量(例如1.1或1.2)应用于logits。以这种方式收缩非常大的logits可以显著改变softmax后的概率,使模型对重复惩罚超参数的选择敏感。受NormSoftmax(Jiang等人,2023b)和PaLM(Chowdhery等人,2022年)的辅助z-loss的启发,我们添加了一个max-z loss来规范logits: 其中z是最大的logit值。这有助于稳定训练,并使推理更加稳健,不受超参数的影响。 Baichuan 2-7B和Baichuan 2-13B的最终训练损失如图3所示。 |
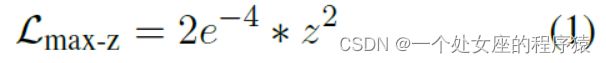
Figure 3: The pre-training loss of Baichuan 2.
图3:Baichuan 2的预训练损失。

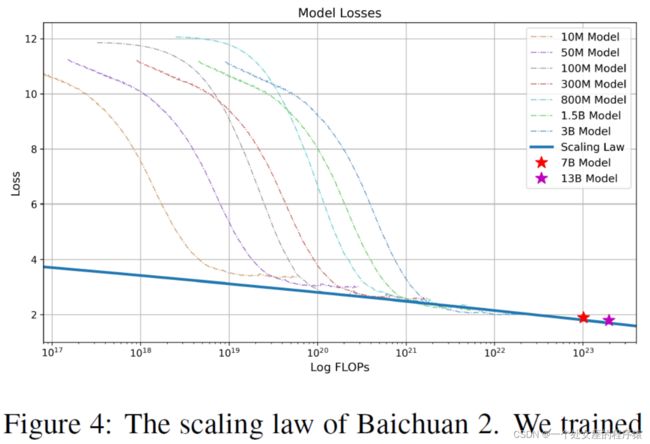
2.6 Scaling Laws缩放定律(保证高训练成本的高性能):通过逐个训练(10M~3B)小模型拟合缩放定律
| Neural scaling laws, where the error decreases as a power function of training set size, model size, or both, have enabled an assuring performance when training became more and more expensive in deep learning and large language models. Before training the large language models of billions of parameters, we first train some small-sized models and fit a scaling law for training larger models. We launched a range of model sizes going from 10M to 3B, ranging from 1 to 1 the size of the final model, and each of the model is trained for up to 1 trillion tokens, using consistent hyper-parameters and the same data set sourced from Baichuan 2. Based on the final loss of different models, we can obtain a mapping from the training flops to the target loss. |
当深度学习和大型语言模型的训练成本越来越高时,神经缩放定律(其中误差作为训练集大小、模型大小或两者的幂函数而减小)能够保证性能。在训练数十亿参数的大型语言模型之前,我们首先训练了一些小型模型,并为训练更大型号的模型拟合了缩放定律。 我们启动了一系列模型尺寸,从10M到3B,范围从最终模型大小的1到1,每个模型都使用一致的超参数和来自Baichuan 2的相同数据集训练了多达1万亿个令牌。根据不同模型的最终损失,我们可以获得从训练flops到目标损失的映射。 |
| To fit the scaling law of the model, we employed the formula given by Henighan et al. (2020):
where L∞ is the irreducible loss and the first term is the reducible loss which is formulated as a power-law scaling term. C are training flops and the LC are final loss of the model in that flops. We used the curve_fit function from the SciPy4 library to fit the parameters. The final fitted scaling curve and the predicted 7 billion and 13 billion parameters model’s final loss are shown in Figure 4.We can see that the fitted scaling law predicted Baichuan 2’s final loss with high accuracy. |
为了拟合模型的缩放定律,我们采用了Henighan等人(2020年)给出的公式: 其中L∞是不可减小的损失,第一项是可减小的损失,其被公式化为幂律缩放项。C是训练flops,LC是该flops中模型的最终损失。我们使用SciPy4库中的curve_fit函数来拟合参数。图4显示了最终拟合的缩放曲线以及预测的7亿和13亿参数模型的最终损失。 |

Figure 4: The scaling law of Baichuan 2. We trained various models ranging from 10 million to 3 billion parameters with 1 trillion tokens. By fitting a power law term to the losses given training flops, we predicted losses for training Baichuan 2-7B and Baichuan 2-13B on 2.6 trillion tokens. This fitting process precisely predicted the final models’ losses (marked with two stars).
图4:Baichuan 2的缩放定律。我们训练了各种模型,从1000万到30亿参数,使用1万亿令牌。通过将幂律项拟合到不同训练flops给出的损失,我们预测了在2.6万亿令牌上训练Baichuan 2-7B和Baichuan 2-13B的损失。这个拟合过程精确地预测了最终模型的损失(用两颗星标记)。
2.7 Infrastructure基础设施:
一种高效利用GPU资源的联合设计(弹性训练框架【张量并行+基于ZeRO共享的数据并行】+智能集群调度策略【任务的资源可根据集群状态动态修改】)、张量分割技术(减少内存峰值消耗)
| Efficiently leveraging existing GPU resources plays a critically important role in training and developing large language models today. To accomplish this, we develop a co-design approach for an elastic training framework and a smart cluster scheduling policy. Since our GPUs are shared among multiple users and tasks, the specific behavior of each task is unpredictable, often leading to idle GPU nodes within the cluster. Considering that a single machine equipped with eight A800 GPUs could adequately meet the memory requirements for our Baichuan 7B and Baichuan 13B models, the primary design criterion for our training framework is the machine-level elasticity, which supports that resources for tasks can be dynamically modified according to the cluster status and thereby serves as the foundation for our smart scheduling algorithm. To meet the requirement of the machine-level elasticity, our training framework integrates tensor parallelism (Narayanan et al., 2021) and ZeRO-powered data parallelism (Rajbhandari et al., 2020), where we set tensor parallelism inside each machine and employ ZeRO shared data parallelism for elastic scaling across machines. In addition, we employ a tensor-splitting technique (Nie et al., 2022) where we split certain calculations to reduce peak memory consumption, such as the cross-entropy calculations with large vocabularies. This approach enables us to meet memory needs without extra computing and communication, making the system more efficient. |
在今天训练和开发大型语言模型时,高效地利用现有的GPU资源在训练和开发大型语言模型中发挥着至关重要的作用。为了实现这一目标,我们开发了一种弹性训练框架和智能集群调度策略的联合设计方法。 由于我们的GPU被多个用户和任务共享,每个任务的具体行为是不可预测的,这经常导致集群中存在空闲的GPU节点。考虑到一台配备8个A800 GPU的机器可以满足Baichuan 7B和Baichuan 13B模型的内存需求,我们的训练框架的主要设计标准是机器级弹性,支持任务的资源可以根据集群状态动态修改,从而作为我们智能调度算法的基础。 为了满足机器级弹性的要求,我们的训练框架集成了张量并行性(Narayanan等人,2021年)和ZeRO驱动的数据并行性(Rajbhandari等人,2020年),其中我们在每台机器内设置了张量并行性,并采用ZeRO共享数据并行性来跨机器进行弹性扩展。 此外,我们采用了张量分割技术(Nie等人,2022年),其中我们分割了某些计算以减少内存峰值消耗,例如具有大词汇表的交叉熵计算。这种方法使我们能够在无需额外计算和通信的情况下满足内存需求,使系统更加高效。 |
混合精度训练(BFloat16中前后向计算+Float32中执行优化器更新):
| To further accelerate training without compromising model accuracy, we implement mixed-precision training, where we perform forward and backward computations in BFloat16, while performing optimizer updating in Float32. |
为了在不影响模型精度的情况下进一步加速训练,我们实现了混合精度训练,在BFloat16中执行前向和后向计算,同时在Float32中执行优化器更新。 |
两大技术避免降低通信效率:拓扑感知分布式训练+ ZeRO混合分层分区设计
| Furthermore, in order to efficiently scale our training cluster to thousands of GPUs, we integrate the following techniques to avoid the degradation of communication efficiency: >>Topology-aware distributed training. In large-scale clusters, network connections frequently span multiple layers of switches. We strategically arrange the ranks for distributed training to minimize frequent access across different switches, which reduces latency and thereby enhances overall training efficiency. >>Hybrid and hierarchical partition for ZeRO. By partitioning parameters across GPUs, ZeRO3 reduces memory consumption at the expense of additional all-gather communications. This approach would lead to a significant communication bottleneck when scaling to thousands of GPUs (Jiang et al., 2023a). To address this issue, we propose a hybrid and hierarchical partitioning scheme. Specifically, our framework first partitions the optimizer states across all GPUs, and then adaptively decides which layers need to activate ZeRO3, and whether partitioning parameters hierarchically. |
此外,为了有效地将我们的训练集群扩展到数千个GPU,我们集成了以下技术来避免通信效率的降低:: >>拓扑感知分布式训练。在大规模集群中,网络连接经常跨越多层交换机。我们策略性地排列分布式训练的队列,以减少跨不同交换机的频繁访问,从而减少延迟,从而提高整体训练效率。 >> ZeRO混合分层分区设计。通过跨GPU划分参数,ZeRO3以额外的全采集通信为代价减少了内存消耗。当扩展到数千个GPU时,这种方法会导致严重的通信瓶颈(Jiang等人,2023a)。为了解决这个问题,我们提出了一种混合分层分区方案。具体来说,我们的框架首先对所有GPU上的优化器状态进行分区,然后自适应地决定哪些层需要激活ZeRO3,以及是否分层划分参数。 |
整合以上策略实现1024个A800来高效训练Baichuan 2
| By integrating these strategies, our system is capable of training Baichuan 2-7B and Baichuan 2-13B models efficiently on 1,024 NVIDIA A800 GPUs, achieving a computational efficiency that exceeds 180 TFLOPS. |
通过整合这些策略,我们的系统能够在1024个NVIDIA A800 GPU上高效训练Baichuan 2-7B和Baichuan 2-13B模型,实现计算效率超过180 TFLOPS。 |
3 Alignment对齐=SFT+RLHF(RM+RL)
| Baichuan 2 also introduces the alignment procedure resulting in two chat models: Baichuan 2-7B-Chat and Baichuan 2-13B-Chat. The alignment process of the Baichuan 2 encompasses two main components: Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF). |
Baichuan 2还引入了对齐过程,产生了两个聊天模型:Baichuan 2-7B-Chat和Baichuan 2-13B-Chat。Baichuan 2的对齐过程包括两个主要组成部分:监督微调(SFT)和从人类反馈中强化学习(RLHF)。 |
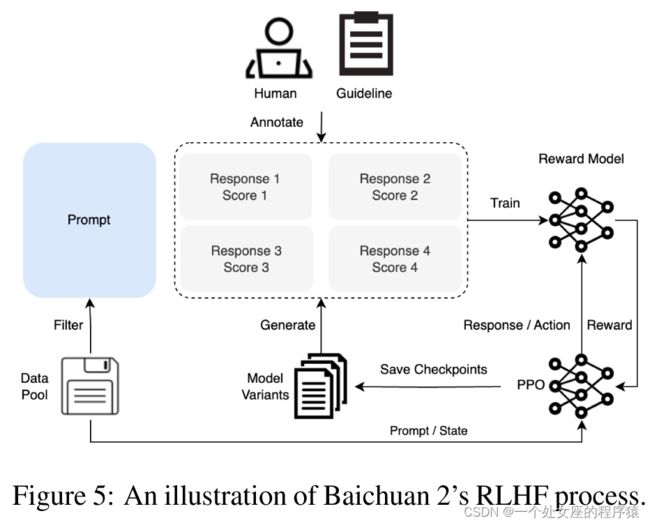
3.1 Supervised Fine-Tuning监督微调:基于10万监督微调样本+人工标记器执行注释+交叉验证(权威标注员校验)
| During the supervised fine-tuning phase, we use human labelers to annotate prompts gathered from various data sources. Each prompt is labeled as being helpful or harmless based on key principles similar to Claude (2023). To validate data quality, we use cross-validation—an authoritative annotator checks the quality of a sample batch annotated by a specific crowd worker group, rejecting any batches that do not meet our quality standards. We collected over 100k supervised fine-tuning samples and trained our base model on them. Next, we delineated the reinforcement learning process via the RLHF method to further improve results. The whole process of RLHF, including RM and RL training, is shown in Figure 5. |
在监督微调阶段,我们使用人工标记器对来自各种数据源收集的提示进行注释。每个提示都根据类似于Claude(2023年)的关键原则标记为有帮助或无害。为了验证数据质量,我们使用交叉验证——一个权威标注员检查了由特定群体的众包工作者组注释的样本批次的质量,拒绝不符合我们质量标准的任何批次。 我们收集了超过10万个监督微调样本,并在基础模型上进行了训练。接下来,我们通过RLHF方法进一步改进结果,确定了强化学习过程。RLHF的整个过程,包括RM和RL训练,如图5所示。 |
Figure 5: An illustration of Baichuan 2’s RLHF process.
图5:Baichuan 2的RLHF过程的示意图。
3.2 Reward Model奖励模型:三级分类系统(6/30/200)
| We devised a three-tiered classification system for all prompts, consisting of 6 primary categories, 30 secondary categories, and over 200 tertiary categories. From the user’s perspective, we aim for the classification system to comprehensively cover all types of user needs. From the standpoint of reward model training, prompts within each category should have sufficient diversity to ensure the reward model can generalize well. Given a prompt, responses are generated by Baichuan 2 models of different sizes and stages (SFT, PPO) to enhance response diversity. Only responses generated by the Baichuan 2 model family are used in the RM training. Responses from other open-source datasets and proprietary models do not improve the reward model’s accuracy. This also underscores the intrinsic consistency of the Baichuan model series from another perspective. The loss function used for training the reward model is consistent with that in InstructGPT (Ouyang et al., 2022). The reward model derived from training exhibits a performance consistent with that of LLaMA 2 (Touvron et al., 2023b), indicating that the greater the score difference between two responses, the higher the discriminative accuracy of the reward model, as shown in Table 4. |
我们为所有提示设计了一个三级分类系统,包括6个一级类别,30个二级类别和200多个三级类别。从用户的角度来看,我们的分类系统旨在全面涵盖所有类型的用户需求。从奖励模型训练的角度来看,每个类别内的提示应具有足够的多样性,以确保奖励模型能够很好地泛化。 在提示条件下,采用不同规模、不同阶段的Baichuan 2模型(SFT、PPO)生成响应,增强响应的多样性。在RM训练中只使用由Baichuan 2模型族生成的响应。来自其他开源数据集和专有模型的响应并不能提高奖励模型的准确性。这也从另一个角度强调了Baichuan 2模型系列的内在一致性。 用于训练奖励模型的损失函数与InstructGPT(Ouyang等人,2022年)中的损失函数一致。从训练中得到的奖励模型表现出与LLaMA 2(Touvron等人,2023b年)一致的性能,表明两个响应之间的得分差异越大,奖励模型的判别准确性越高,如表4所示。 |
Table 4: Reward Model test accuracy on different score gaps of two responses. The larger the response gap, the better RM accuracy. The gap 1,2,3,4,5 correspond to unsure, negligibly better, slightly better, better, and significantly better, respectively.
表4:不同响应得分差距下的奖励模型测试准确性。响应差距越大,RM准确性越高。差距1、2、3、4、5分别对应于unsure、negligibly better、slightly better、better和significantly better。

3.3 PPO(训练LM):采用四模型(参与者+参考模型+奖励模型+批评模型)
| After obtaining the reward model, we employ the PPO (Schulman et al., 2017) algorithm to train our language model. We employ four models: the actor model (responsible for generating responses), the reference model (used to compute the KL penalty with fixed parameters), the reward model (providing an overarching reward for the entire response with fixed parameters), and the critic model (designed to learn per-token values). |
在获得奖励模型后,我们采用PPO(Schulman等人,2017年)算法来训练我们的语言模型。我们使用了四个模型:参与者模型(负责生成响应)、参考模型(用于计算具有固定参数的KL惩罚)、奖励模型(为整个响应提供总体奖励,具有固定参数)和批评模型(设计用于学习每个标记值)。 |
3.4 Training Details训练细节
| During the RLHF training process, the critic model is warmed up with an initial 20 training steps ahead. Subsequently, both the critic and actor models are updated via the standard PPO algorithm. For all models, we use gradient clipping of 0.5, a constant learning rate of 5e-6, and a PPO clip threshold ϵ = 0.1. We set the KL penalty coefficient β = 0.2, decaying to 0.005 over steps. We train for 350 iterations for all our chat models, resulting in Baichuan 2-7B-Chat and Baichuan 2-13B-Chat. |
在RLHF训练过程中,批评家模型在前面的20个训练步骤中进行了热身。随后,批评家模型和参与者模型都通过标准PPO算法进行更新。对于所有模型,我们使用了0.5的梯度剪裁、恒定的学习率5e-6和PPO剪裁阈值ϵ = 0.1。我们将KL惩罚系数β设置为0.2,并在步骤上逐渐减小到0.005。我们为所有的聊天模型训练了350次迭代,得到了Baichuan 2-7B-Chat和Baichuan 2-13B-Chat。 |
4 Safety安全性
| We believe that model safety improvements stem not only from constraints during data cleansing or alignment stages but also from harnessing positive knowledge and identifying negative knowledge during all training stages. Guided by this concept, we have enhanced model safety throughout the Baichuan 2 training process. |
我们认为,模型安全性的提高不仅来自于数据清洗或对齐阶段的约束,还源于在所有训练阶段利用积极知识和识别负面知识。在这一理念的指导下,我们在整个Baichuan 2的训练过程中提高了模型的安全性。 |
4.1 Pre-training Stage预训练阶段:设计了一套规则和模型过滤有害内容+策划了一个中英双语数据集
| In the pre-training stage, we pay close attention to data safety. The entire pre-training dataset underwent a rigorous data filtering process aimed at enhancing safety. We devised a system of rules and models to eliminate harmful content such as violence, pornography, racial discrimination, hate speech, and more. Furthermore, we curated a Chinese-English bilingual dataset comprising several million webpages from hundreds of reputable websites that represent various positive value domains, encompassing areas such as policy, law, vulnerable groups, general values, traditional virtues, and more. We also heightened the sampling probability for this dataset. |
在预训练阶段,我们密切关注数据安全性。整个预训练数据集经历了严格的数据过滤过程,旨在提高安全性。我们设计了一套规则和模型,以消除暴力、色情、种族歧视、仇恨言论等有害内容。 此外,我们策划了一个中英双语数据集,包括数百个知名网站的数百万个网页,代表了各种积极价值领域,涵盖了政策、法律、弱势群体、一般价值观、传统美德等领域。我们还提高了该数据集的抽样概率。 |
4.2 Alignment Stage对齐阶段:红队流程(6种和100+粒度),专家标注团队(20万个攻击提示)+多值监督采样方法+DPO+采用有益和无害目标相结合的奖励模型
| We build a red-teaming procedure consisting of 6 types of attacks and 100+ granular safety value categories, an expert annotation team of 10 with traditional internet security experience initialized safe alignment prompts. The relevant snippets from the pre-training dataset were retrieved to create responses, resulting in approximately 1K annotated data for initialization. >>The expert annotation team guided a 50-person outsourced annotation team through red-blue confrontation with the initialized alignment model, resulting in the generation of 200K attack prompts. >>By employing a specialized multi-value supervised sampling method, we maximized the utilization of attack data to generate responses at varying safety levels. During the RL optimization stage, we also take safety into the first account: >>At the onset of safety reinforcement, DPO (Rafailov et al., 2023) methods efficiently employed limited amounts of annotated data to enhance performance concerning specific vulnerability issues. >>By employing a Reward Model that integrates Helpful and Harmless objectives, PPO safety reinforcement training was conducted. |
我们构建了由6种攻击类型和100+粒度安全价值类别组成的红队流程,由10人组成的具有传统互联网安全经验的专家标注团队初始化安全对齐提示。从预训练数据集中检索相关片段来创建响应,产生大约1K的带注释的数据用于初始化。 >>专家标注团队通过与初始化的对齐模型进行红蓝对抗,引导了一个由50名外包注释团队组成的团队,生成了20万个攻击提示。 >>通过采用专门的多值监督采样方法,我们最大程度地利用攻击数据来生成不同安全级别的响应。 在RL优化阶段,我们还首先考虑了安全性: >>在安全性增强的初期,DPO(Rafailov等人,2023年)方法高效地使用有限数量的注释数据来增强特定的漏洞问题。 >>采用有益和无害目标相结合的奖励模型,对PPO进行安全强化训练。 |
5 Evaluations评估
| In this section, we report the zero-shot or few-shot results of the pre-trained base models on standard benchmarks. We evaluate Baichuan 2 on free-form generation tasks and multiple-choice tasks. >>Free-form generation: Models are given some sample inputs (shots) and then generate continuations to obtain results, like for question answering, translation, and other tasks. >>Multiple-choice: Models are given a question and multiple choices, and the task is to select the most appropriate candidates. |
本节中,我们报告了预训练基础模型在标准基准上的零射击或少射击结果。我们评估了Baichuan 2在自由形式生成任务和多选任务上的性能。 >>自由形式生成:模型提供一些示例输入(射击),然后生成继续以获得结果,例如问题回答、翻译和其他任务。 >>多选:模型提供一个问题和多个选项,任务是选择最合适的候选项。 |
| Given the variety of tasks and examples, we incorporated open-source evaluation frameworks like lm-evaluation-harness (Gao et al., 2021) and OpenCompass (OpenCompass, 2023) into our in-house implementations for fair benchmarking against other models. The models we choose to compare have similar sizes to Baichuan 2 and are open-sourced that the results can reproduced: >>LLaMA (Touvron et al., 2023b): The language models trained by Meta on 1 trillion tokens. The context length is 2,048 and we evaluate both LLaMA 7B and LLaMA 13B. >>LLaMA 2 (Touvron et al., 2023c): A successor model to LLaMA 1 trained on 2 trillion tokens and better data mixture. >>Baichuan 1 (Baichuan, 2023b): The Baichuan 7B is trained on 1.2 trillion tokens and Baichuan 13B is trained on 1.4 trillion tokens. Both of them focus on English and Chinese. >>ChatGLM 2-6B (Zeng et al., 2022): A chat language model that has strong performance on several benchmarks5. >>MPT-7B (MosaicML, 2023): An open-source LLMs trained 1 trillion tokens of English text and code. >>Falcon-7B (Penedo et al., 2023): A series of LLMs trained on 1 trillion tokens enhanced with curated corpora. It is made available under the Apache 2.0 license. >>Vicuna-13B (Chiang et al., 2023): A language model trained by fine-tuning LLaMA-13B on the conversational dataset generated by ChatGPT. >>Chinese-Alpaca-Plus-13B (Cui et al., 2023): A language model trained by fine-tuning LLaMA- 13B on the conversational dataset generated by ChatGPT. >>XVERSE-13B: A 13B multilingual large language model trained on more than 1.4 trillion tokens. |
考虑到任务和示例的多样性,我们在内部实施中引入了开源评估框架,如lm-evaluation-harness(Gao等人,2021年)和OpenCompass(OpenCompass,2023年),以便与其他模型进行公平的基准比较。 我们选择了与Baichuan 2大小相似且开源的模型进行比较,其结果可以被复制: >>LLaMA(Touvron等人,2023b):由Meta在1万亿标记上训练的语言模型。上下文长度为2,048,我们评估LLaMA 7B和LLaMA 13B。 >>LLaMA 2(Touvron等人,2023c):LLaMA 1的后续模型,训练在2万亿标记上,数据混合更好。 >>Baichuan 1(Baichuan,2023b):Baichuan 7B训练在1.2万亿标记上,Baichuan 13B训练在1.4万亿标记上。它们都侧重于英语和中文。 >>ChatGLM 2-6B(Zeng等人,2022年):在几个基准上表现出色的聊天语言模型。 >>MPT-7B(MosaicML,2023):一个开源的LLMs,训练了1万亿标记的英文文本和代码。 >>Falcon-7B(Penedo等人,2023):一系列经过策划的1万亿标记的LLMs。它在Apache 2.0许可下提供。 >>Vicuna-13B(Chiang等人,2023):通过对LLaMA-13B进行微调而训练的语言模型,该模型使用ChatGPT生成的对话数据集。 >>Chinese-Alpaca-Plus-13B(Cui等人,2023):通过对LLaMA-13B进行微调而训练的语言模型,该模型使用ChatGPT生成的对话数据集。 >>XVERSE-13B:一个13B多语言大型语言模型,训练了超过1.4万亿标记。 |
5.1 Overall Performance总体性能
| This section introduces the overall performance of Baichuan 2 base models compared with other similar-sized models. We choose 8 benchmarks for comparison: MMLU (Hendrycks et al., 2021a) The Massive Multitask Language Understanding consists of a range of multiple-choice questions on academic subjects. C-Eval (Huang et al., 2023) is a comprehensive Chinese evaluation benchmark consists of more than 10k multi-choice questions. CMMLU (Li et al., 2023) is also a general evaluation benchmark specifically designed to evaluate the knowledge and reasoning abilities of LLMs within the context of the Chinese language and culture. AGIEval (Zhong et al., 2023) is a human-centric benchmark specifically designed to evaluate general abilities like human cognition and problem-solving. Gaokao (Zhang et al., 2023) is an evaluation framework that utilizes Chinese high school entrance examination questions. BBH (Suzgun et al., 2022) is a suite of challenging BIG-Bench (Srivastava et al., 2022) tasks that the language model evaluations did not outperform the average human-rater. GSM8K (Cobbe et al., 2021) is an evaluation benchmarks that focused on math. HumanEval (Chen et al., 2021) is a docstring-to-code dataset consisting of 164 coding problems that test various aspects of programming logic. |
本节介绍了Baichuan 2基础模型的总体性能,与其他类似大小的模型进行了比较。我们选择了8个基准进行比较:MMLU(Hendrycks等人,2021a)Massive Multitask Language Understanding包括一系列关于学术科目的多项选择题。C-Eval(Huang等人,2023)是一个综合性的中文评估基准,包括10,000多个多选题。CMMLU(Li等人,2023)也是一个通用评估基准,专门设计用于在中文语境和文化中评估LLMs的知识和推理能力。AGIEval(Zhong等人,2023)是一个以人为中心的基准,专门设计用于评估人类认知和问题解决等一般能力。Gaokao(Zhang等人,2023)是一个评估框架,利用了中国高中入学考试的问题。BBH(Suzgun等人,2022)是一套具有挑战性的BIG-Bench(Srivastava等人,2022)任务,语言模型的评估没有超过人类评分的平均水平。GSM8K(Cobbe等人,2021)是一个关注数学的评估基准。HumanEval(Chen等人,2021)是一个由164个编程问题组成的docstring-to-code数据集,测试编程逻辑的各个方面。 |
| For CMMLU and MMLU, we adopt the official implementations and adopt 5-shot for evaluation. For BBH we adopt 3-shot evaluations. For C-Eval, Gaokao, and AGIEval we only select the multiple-choice with four candidates for better evaluations. For GSM8K, we adopt 4-shot testing derived from OpenCompass (OpenCompass, 2023). We also incorporate the result of GPT-46 and GPT-3.5-Turbo7. Unless stated otherwise, the results in this paper were obtained using our internal evaluation tools. The overall result is shown in Table 1. Compared with other similar-sized open-sourced models, our model has a clear performance advantage. Especially in math and code problems, our model achieves significant improvement over Baichuan 1. |
对于CMMLU和MMLU,我们采用了官方实现,并采用了5次射击进行评估。对于BBH,我们采用了3次射击评估。对于C-Eval、Gaokao和AGIEval,我们仅选择了具有四个候选项的多选题进行更好的评估。对于GSM8K,我们采用了从OpenCompass(OpenCompass,2023)派生的4次射击测试。我们还包括了GPT-46和GPT-3.5-Turbo7的结果。除非另有说明,本文中的结果是使用我们的内部评估工具获得的。 总体结果如表1所示。与其他类似大小的开源模型相比,我们的模型具有明显的性能优势。特别是在数学和代码问题上,我们的模型相对于Baichuan 1取得了显著的改进。 |
5.2 Vertical Domain Evaluations垂直领域评估
| We also evaluate Baichuan 2 in vertical domains, where we choose the law and medical field as they has been widely studied in recent years. In the law field, we report scores of JEC-QA (Zhong et al., 2020), which is collected from the National Judicial Examination of China. It contains multiple-choice and multiple-answer questions. For compatibility with our evaluation suite, we only test the multiple-choice questions. In the medical field, we report scores from two medical benchmarks, MedQA (Jin et al., 2021) and MedMCQA (Pal et al., 2022), as well as average scores from medical-related disciplines in C-Eval (val), MMLU, and CMMLU (abbreviated as CMC). Specifically, MedMCQA is collected from the professional medical board exams in the USA and China, including three subsets, i.e., USMLE, MCMLE and TWMLE, and we report the results of USMLE and MCMLE with five candidates; MedMCQA is collected from from Indian medical entrance exams, and we evaluate multiple-choice questions and report the scores in the dev set. The detail of MedMCQA includes (1) clinical medicine, basic medicine of C-Eval (val), (2) clinical knowledge, anatomy, college medicine, college biology, nutrition, virology, medical genetics, professional medicine of MMLU,(3) anatomy, clinical knowledge, college medicine, genetics, nutrition, traditional chinese medicine, virology of CMMLU. Moreover, all these datasets are evaluated in 5-shot. |
我们还评估了Baichuan 2在垂直领域中的表现,选择了法律和医学领域,因为它们近年来得到了广泛研究。 在法律领域,我们报告了来自中国国家司法考试的JEC-QA(Zhong等人,2020)的分数,该数据集包含多项选择和多答案问题。出于与我们评估套件的兼容性考虑,我们只测试多项选择问题。 在医学领域,我们报告了两个医学基准的分数,MedQA(Jin等人,2021)和MedMCQA(Pal等人,2022),以及C-Eval(val)中与医学相关学科的平均分数,以及MMLU和CMMLU(简称CMC)中的医学相关学科的平均分数。具体来说,MedMCQA是从美国和中国的专业医学委员会考试中收集的,包括三个子集,即USMLE、MCMLE和TWMLE,我们报告了USMLE和MCMLE的结果,包括五个候选项;MedMCQA是从印度医学入学考试中收集的,我们评估多项选择问题,并报告dev集的分数。MedMCQA的详细信息包括(1)C-Eval(val)的临床医学、基础医学,(2)MMLU的临床知识、解剖学、大学医学、大学生物学、营养学、病毒学、医学遗传学、专业医学,(3)CMMLU的解剖学、临床知识、大学医学、遗传学、营养学、中药学、病毒学。此外,所有这些数据集都是在5次射击下评估的。 |
| As shown in Table 5 Baichuan 2-7B-Base surpasses models such as GPT-3.5 Turbo, ChatGLM 2-6B, and LLaMA 2-7B in the field of Chinese law, second only to GPT-4. Compared to Baichuan 1-7B, Baichuan 2-7B-Base shows an improvement of nearly 10 points. In the medical field, Baichuan 2-7B-Base outperforms models like ChatGLM 2-6B and LLaMA 2-7B, showing significant improvement over Baichuan 1-7B as well. Similarly, Baichuan 2-13B-Base surpasses models other than GPT-4 in the field of Chinese law. In the medical domain, Baichuan 2-13B-Base outperforms models such as XVERSE-13B and LLaMA 2-13B. Compared to Baichuan 1- 13B-Base, Baichuan 2-13B-Base also exhibits remarkable improvement. |
如表5所示,Baichuan 2-7B-Base在中国法律领域超越了GPT-3.5 Turbo、ChatGLM 2-6B和LLaMA 2-7B等模型,仅次于GPT-4。在医学领域,Baichuan 2-7B-Base超越了ChatGLM 2-6B和LLaMA 2-7B等模型,在Baichuan 1-7B上也取得了近10点的改进。 同样,Baichuan 2-13B-Base在中国法律领域超越了除GPT-4以外的其他模型。在医学领域,Baichuan 2-13B-Base超越了XVERSE-13B和LLaMA 2-13B等模型,相对于Baichuan 1-13B-Base,Baichuan 2-13B-Base也取得了显著的改进。 |
5.3 Math and Code数学和代码
| This section introduces the performance in mathematics and coding. |
本节介绍了数学和编程的性能。 |
| We use GSM8K (Cobbe et al., 2021) (4-shot) and MATH (Hendrycks et al., 2021b) (4-shot) to evaluate the mathematical ability. MATH contains 12,500 mathematical questions that are harder to be solved. To evaluate the model’s code ability, we report the scores in HumanEval (Chen et al., 2021)(0-shot) and MBPP (Austin et al., 2021) (3-shot). >>HumanEval is a series of programming tasks including model language comprehension, reasoning, algorithms, and simple mathematics to evaluate the correctness of the model and measure the model’s problem-solving ability. >>MBPP. It consists of a dataset of 974 Python short functions and program textual descriptions, along with test cases used to verify the correctness of their functionality. |
我们使用GSM8K(Cobbe等人,2021)(4次射击)和MATH(Hendrycks等人,2021b)(4次射击)来评估数学能力。MATH包含12,500个更难解决的数学问题。为了评估模型的代码能力,我们报告了HumanEval(Chen等人,2021)(0次射击)和MBPP(Austin等人,2021)(3次射击)的分数。 HumanEval是一系列编程任务,包括模型语言理解、推理、算法和简单数学,旨在评估模型的正确性和问题解决能力。 MBPP。它包含974个Python短函数和程序文本描述的数据集,以及用于验证其功能正确性的测试用例。 |
| We use OpenCompass to evaluate the ability of models in math and code. As shown in Table 6, in the field of mathematics, Baichuan 2-7B-Base surpasses models like LLaMA 2-7B. In the code domain, it outperforms models of the same size such as ChatGLM 2-6B. Baichuan 2-7B-Base exhibits significant improvement compared to the Baichuan 1-7B model. In mathematics, Baichuan 2-13B-Base surpasses all models of the same size, approaching the level of GPT-3.5 Turbo. In the code domain, Baichuan 2-13B-Base outperforms models like LLaMA 2- 13B and XVERSE-13B. Baichuan 2-13B-Base demonstrates significant improvement compared to Baichuan 1-13B-Base. |
我们使用OpenCompass来评估模型在数学和代码方面的能力。如表6所示,在数学领域,Baichuan 2-7B-Base超越了LLaMA 2-7B等大小相似的模型。在代码领域,它超越了ChatGLM 2-6B等大小相似的模型。Baichuan 2-7B-Base相对于Baichuan 1-7B模型也取得了显著的改进。 在数学领域,Baichuan 2-13B-Base超越了所有相同大小的模型,接近了GPT-3.5 Turbo的水平。在代码领域,Baichuan 2-13B-Base超越了LLaMA 2-13B和XVERSE-13B等模型。Baichuan 2-13B-Base相对于Baichuan 1-13B-Base模型也取得了显著的改进。 |
5.4 Multilingual多语言
| Figure 6: Helpfulness and harmlessness before and after safety alignment of Baichuan 2. The x-axis shows the metric before safety alignment and the y-axis shows the result after. We see that helpfulness remains largely unchanged after this procedure, while harmlessness improved substantially (more mass in upper triangle) with safety efforts. We use Flores-101 (NLLB Team, 2022; Goyal et al., 2021; Guzmán et al., 2019) to evaluate multilingual ability. Flores-101 covers 101 languages from around the world. Its data is sourced from various domains such as news, travel guides, and books. We selected the official languages of the United Nations (Arabic (ar), Chinese (zh), English (en), French (fr), Russian (ru), and Spanish (es)), as well as German (de) and Japanese (ja), as the test languages. We conducted 8-shot tests on seven subtasks in Flores-101 , including zh-en, zh-fr, zh-es, zh-ar, zh-ru, zh-ja and zh-de. The evaluation is conducted with OpenCompass. |
我们使用Flores-101(NLLB团队,2022年;Goyal等人,2021年;Guzmán等人,2019年)来评估多语言能力。Flores-101涵盖了来自世界各地的101种语言。其数据来自各个领域,如新闻、旅游指南和书籍。我们选择了联合国的官方语言(阿拉伯语(ar)、中文(zh)、英语(en)、法语(fr)、俄语(ru)和西班牙语(es)),以及德语(de)和日语(ja)作为测试语言。我们在Flores-101的七个子任务中进行了8次射击测试,包括zh-en、zh-fr、zh-es、zh-ar、zh-ru、zh-ja和zh-de。评估是通过OpenCompass进行的。 在多语言领域,如表7所示,Baichuan 2-7B-Base在所有七个任务中都超越了所有相同大小的模型,并相对于Baichuan 1-7B取得了显著的改进。 |
| In the multilingual domain, as shown in Table 7, Baichuan 2-7B-Base surpasses all models of the same size in all seven tasks and shows significant improvement compared to Baichuan 1-7B. Baichuan 2-13B-Base outperforms models of the same size in four out of the seven tasks. In the zh-en and zh-ja tasks, it surpasses GPT3.5 Turbo and reaches the level of GPT-4. Compared to Baichuan 1-13B-Base, Baichuan 2-13B-Base exhibits significant improvement in the zh-ar, zh-ru, and zh-ja tasks. Although GPT-4 still dominates in the field of multilingualism, open-source models are catching up closely. In zh-en tasks, Baichuan 2-13B-Base has slightly surpassed GPT-4. |
Baichuan 2-13B-Base在七个任务中的四个任务中超越了相同大小的模型。在zh-en和zh-ja任务中,它超越了GPT3.5 Turbo,达到了GPT-4的水平。相对于Baichuan 1-13B-Base,Baichuan 2-13B-Base在zh-ar、zh-ru和zh-ja任务中表现出了显著的改进。 虽然GPT-4仍然在多语言领域占据主导地位,但开源模型正逐渐迎头赶上。在zh-en任务中,Baichuan 2-13B-Base稍微超越了GPT-4。 |
5.5 Safety Evaluations
| In Sec. 4, we describe the efforts made to improve the safety of Baichuan 2. However, some prior work indicates that helpfulness and harmlessness are two sides of a seesaw - when harmlessness increases, helpfulness could lead to a bit decrease (Bai et al., 2022a). So we evaluate these two factors before and after safety alignments. Figure 6 shows the helpfulness and harmlessness before and after the safety alignment of Baichuan 2.We can see that our safety alignment process did not hurt the helpfulness while significantly improving the harmlessness. Then we evaluate the safety of our pre-trained models using the Toxigen (Hartvigsen et al., 2022) dataset. Same as LLaMA 2, we use the cleaned version from the SafeNLP project8, distinguishing neutral and hate types for the 13 minority groups, forming a 6-shot dataset consistent with the original Toxigen prompt format. Our decoding parameters use temperature 0.1 and top-p 0.9 nucleus sampling. |
安全性评估 在第4节中,我们描述了改善Baichuan 2安全性的努力。然而,一些先前的工作指出,帮助和无害性是一把双刃剑的两面——当无害性增加时,帮助可能会稍微减少(Bai等人,2022a)。因此,我们在安全调整之前和之后评估了这两个因素。 图6显示了Baichuan 2安全调整之前和之后的帮助和无害性。我们可以看到,我们的安全调整过程并没有损害帮助性,而在很大程度上提高了无害性。 然后,我们使用Toxigen(Hartvigsen等人,2022)数据集来评估我们的预训练模型的安全性。与LLaMA 2一样,我们使用SafeNLP项目的清理版本,区分了13个少数民族群体中的中性和仇恨类型,形成了一个6次射击的数据集,与原始的Toxigen提示格式一致。我们的解码参数使用温度0.1和top-p 0.9核心抽样。 |
| We use the fine-tuned HateBert version optimized in the Toxigen (Hartvigsen et al., 2022) for model evaluation. Table 8 shows that compared to LLaMA 2, the Baichuan 2-7B and Baichuan 2-13B model has some safety advantages. Inspired by BeaverTails Ji et al. (2023)9, we constructed the Baichuan Harmless Evaluation Dataset (BHED), covering 7 major safety categories of bias/discrimination, insults/profanity, illegal/unethical content, physical health, mental health, financial privacy, and sensitive topics to evaluate the safety of our chat models. To ensure comprehensive coverage within each category, We ask human annotators to generate 1,400 data samples. This was further expanded through self-instruction and cleaned by humans for fluency, resulting in 70,000 total samples with 10,000 per category. Examples of those safety prompts and principles are shown in the Appendix E. We use those samples to evaluate different models and the result is shown in Table 9. We can see that Baichuan 2 is on par or outperforms other chat models in our safety evaluations. |
我们使用在Toxigen(Hartvigsen等人,2022)中优化的HateBert版本来评估模型。表8显示,与LLaMA 2相比,Baichuan 2-7B和Baichuan 2-13B模型在某些安全方面具有一定的优势。 受到BeaverTails Ji等人(2023)的启发,我们构建了Baichuan Harmless Evaluation Dataset(BHED),涵盖了7个主要的安全类别,包括偏见/歧视、侮辱/亵渎、非法/不道德内容、身体健康、心理健康、金融隐私和敏感话题,以评估我们聊天模型的安全性。 为了确保每个类别内部具有全面的覆盖范围,我们请人工标记者生成1,400个数据样本。这些样本通过自我学习进一步扩展,并由人工清理以获得流畅性,总共有70,000个样本,每个类别有10,000个。这些安全提示和原则的示例显示在附录E中。 我们使用这些样本来评估不同的模型,结果如表9所示。我们可以看到,在我们的安全评估中,Baichuan 2与其他聊天模型不相上下,甚至表现更好。 |
Table 5: The result of Baichuan 2 compared with other models on law and medical filed.
表5:Baichuan 2在法律和医学领域与其他模型的结果比较。

Table 6: The result of Baichuan 2 compared with other models on mathematics and coding.
表6:Baichuan 2在数学和编程方面与其他模型的结果比较。
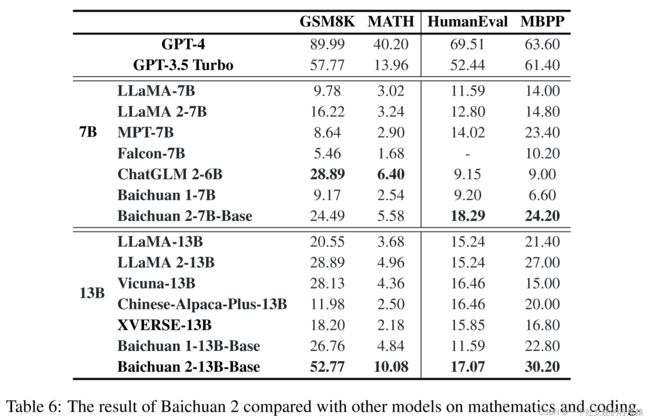
Table 7: The result of Baichuan 2 compared with other models on multilingual field.
表7:Baichuan 2在多语言领域与其他模型的结果比较。

5.6 Intermediate Checkpoints中间检查点
| We will also release the intermediate checkpoints of 7B models, from 220 billion tokens checkpoint to 2,640 billion tokens checkpoint, which is the final output of Baichuan 2-7B-Base. We examine their performance on several benchmarks and the result is shown in Figure 7. As shown in the figure, Baichuan 2 demonstrates consistent improvement as training proceeds. Even after 2.6 trillion tokens, there appears to be ample room for further gains. This aligns with previous work on scaling LLMs indicating that data size is a critical factor (Hoffmann et al., 2022). In the Appendix D, we provide more detailed training dynamics for both the 7B and 13B models. |
我们还将发布7B模型的中间检查点,从2200亿标记的检查点到2640亿标记的检查点,这是Baichuan 2-7B-Base的最终输出。我们对它们在几个基准上的性能进行了检查,结果如图7所示。 正如图中所示,Baichuan 2在训练过程中表现出了一致的改进。即使在2.6万亿标记之后,似乎仍然有足够的提升空间。这与以前关于扩展LLMs的工作表明数据大小是一个关键因素的研究一致(Hoffmann等人,2022)。在附录D中,我们提供了7B和13B模型的更详细的训练动态。 |
6 Related Work相关工作
| The field of language models has undergone a renaissance in recent years, sparked largely by the development of deep neural networks and Transformers (Vaswani et al., 2017). Kaplan et al.(2020) proposed the scaling laws for large model pre-training. By systematically analyzing model performance as parameters and data size increased, they provided a blueprint for the current era of massive models with hundreds of or even billions of parameters. Seizing upon these scaling laws, organizations like OpenAI, Google, Meta, and Anthropic have engaged in a computing arms race to create ever-larger LLMs. Spurred by the OpenAI’s 175 billion parameters proprietary language model GPT-3 (Brown et al., 2020). The few-shot or even zero-shot ability of LLMs has revolved most natural language understanding tasks. From code generation to math-solving problems or even open-world scenarios. Specialized scientific LLMs like Galactica (Taylor et al., 2022) have also emerged to showcase the potential for large models to assimilate technical knowledge. However, raw parameter count alone does not determine model capability - Chinchilla (Hoffmann et al., 2022) demonstrated that scaling model capacity according to the number of tokens, rather than just parameters, can yield better sample efficiency. |
近年来,语言模型领域经历了一次复兴,主要是由于深度神经网络和Transformer(Vaswani等人,2017)的发展所引发的。Kaplan等人(2020)提出了用于大型模型预训练的缩放定律。通过系统分析模型性能随参数和数据大小增加的情况,他们为当前具有数百亿甚至数千亿参数的大型模型时代提供了蓝图。 利用这些缩放定律,OpenAI、Google、Meta和Anthropic等组织已经卷入了一场计算的竞赛,以创建规模更大的LLMs。受OpenAI的1750亿参数专有语言模型GPT-3(Brown等人,2020)的推动,LLMs的零射击甚至零射击能力已经围绕着大多数自然语言理解任务展开。从代码生成到数学问题甚至开放世界的情景。专门的科学LLMs,如Galactica(Taylor等人,2022),也已经出现,展示了大型模型吸收技术知识的潜力。然而,仅凭原始参数数量无法确定模型的能力——Chinchilla(Hoffmann等人,2022)表明,根据标记数量而不仅仅是参数来扩展模型容量,可以提高样本效率。 |
| Concurrent with the development of private LLMs, academic and non-profit efforts have worked to develop open-source alternatives like Bloom (Scao et al., 2022), OPT (Zhang et al., 2022) and Pythia (Biderman et al., 2023b). Although some open-source large language models contain up to 175 billion parameters, most are trained on only 500 billion tokens or less. This is relatively small considering that 7 billion parameter models can still significantly improve after being trained on trillions of tokens. Among those open-sourced models, LLaMA (Touvron et al., 2023b) and its successor LLaMA 2 (Touvron et al., 2023c) stands out for its performance and transparency. Which was quickly optimized by the community for better inference speed and various applications. In addition to those foundation models, a lot of chat models have also been proposed to follow human instructions. Most of them fine-tune the foundation models to align with human (OpenAI, 2022; Wang et al., 2023). Those chat models have demonstrated a marked improvement in understanding human instructions and solving complex tasks (Chiang et al., 2023; Xu et al., 2023; Sun et al., 2023). To further improve alignment, (Ouyang et al., 2022) incorporates the Reinforcement Learning from Human Feedback (RLHF) approach. This involves learning from human preferences by training a reward model on human-rated outputs. Other methods such as direct preference optimization (DPO) (Rafailov et al., 2023) and reinforcement learning from AI feedback (RLAIF) (Bai et al., 2022b) have also been proposed to improve the RLHF both in terms of efficiency and effectiveness. |
与私有LLMs的发展同时,学术和非营利性机构一直致力于开发像Bloom(Scao等人,2022)、OPT(Zhang等人,2022)和Pythia(Biderman等人,2023b)这样的开源替代品。尽管一些开源的大型语言模型包含多达1750亿参数,但大多数仅在5000亿标记或更少的数据上训练。考虑到70亿参数模型在训练数万亿标记后仍然可以显着改进,这相对较小。在那些开源的模型中,LLaMA(Touvron等人,2023b)及其后继模型LLaMA 2(Touvron等人,2023c)以其性能和透明度脱颖而出。社区迅速对其进行了优化,以提高推理速度和各种应用。 除了这些基础模型,还提出了许多聊天模型,以遵循人类的指令。它们大多数是对基础模型进行微调,以与人类一致(OpenAI,2022;Wang等人,2023)。这些聊天模型已经在理解人类指令和解决复杂任务方面取得了显著的改进(Chiang等人,2023;Xu等人,2023;Sun等人,2023)。为了进一步改善对齐,Ouyang等人(2022)融入了来自人类反馈的强化学习(RLHF)方法。这涉及到通过在人类评定的输出上训练奖励模型来学习人类偏好。其他方法,如直接偏好优化(DPO)(Rafailov等人,2023)和来自AI反馈的强化学习(RLAIF)(Bai等人,2022b),也已经提出,以提高RLHF的效率和效果。 |
Table 9: The result of different chat models on our safety evaluation benchmarks.
表9:不同聊天模型在我们的安全评估基准上的结果。

Figure 7: The results of intermediary checkpoints of Baichuan 2-7B which will be released to the public.
图7:Baichuan 2-7B的中间检查点结果,将向公众发布。

7 Limitations and Ethical Considerations限制和道德考虑
| Like other large language models, Baichuan 2 also faces ethical challenges. It’s prone to biases and toxicity, especially given that much of its training data originates from the internet. Despite our best efforts to mitigate these issues using benchmarks like Toxigen (Hartvigsen et al., 2022), the risks cannot be eliminated, and toxicity tends to increase with model size. Moreover, the knowledge of Baichuan 2 models is static and can be outdated or incorrect, posing challenges in fields that require up-to-date information like medicine or law. While optimized for Chinese and English for safety, the model has limitations in other languages and may not fully capture biases relevant to non-Chinese cultures. There’s also the potential for misuse, as the model could be used to generate harmful or misleading content. Although we try our best efforts to balance safety and utility, some safety measures may appear as over-cautions, affecting the model’s usability for certain tasks. We encourage users to make responsible and ethical use of Baichuan 2 models. Meanwhile, we will continue to optimize these issues and release updated versions in the future. |
与其他大型语言模型一样,Baichuan 2也面临着伦理挑战。它容易受到偏见和毒性的影响,特别是考虑到它的训练数据很大程度上来自互联网。尽管我们尽最大努力通过使用Toxigen(Hartvigsen等人,2022)等基准来减轻这些问题,但风险无法完全消除,而且随着模型大小的增加,毒性往往会增加。此外,Baichuan 2模型的知识是静态的,可能会过时或不正确,这在需要最新信息的领域,如医学或法律,会带来挑战。虽然为了安全性而进行了中文和英文的优化,但该模型在其他语言方面存在局限性,并且可能无法充分捕捉与非中国文化相关的偏见。 还存在滥用的潜力,因为该模型可能被用来生成有害或误导性的内容。尽管我们尽最大努力平衡安全性和效用,但一些安全措施可能会显得过于谨慎,影响模型在某些任务中的可用性。我们鼓励用户负责任地和道德地使用Baichuan 2模型。与此同时,我们将继续优化这些问题,并在未来发布更新版本。 |
References
更新中……