背景
在使用 Kafka 消息队列时,申请 Kafka 资源涉及 Topic 名称、分区数、ClientId 等参数。ClientId 在 Kafka 中主要用于标识和管理客户端应用程序,以及为监控、日志记录和资源管理提供支持。通过为每个客户端分配唯一的 ClientId,你可以更好地跟踪和管理 Kafka 集群中的各个客户端连接。然而在某些公司,ClientId 是用于鉴权和限流的,因此在使用 Kafka 时需要确保 ClientId 与申请 Topic 时的 ClientId 保持一致。这与一般的 Kafka 使用方式有所不同。在使用 spring-kafka 包和原生 kafka-clients 包的多线程环境下,固定的 ClientId 并不能满足需求,需要重写 spring-kafka 包的 ProducerFactory 和 ConsumerFactory,或者申请多个 ClientId。本文将讨论在使用 Kafka 时遇到的关于 ClientId 的问题以及建议的解决方法。
过程
大多数 Java 应用程序都集成了 Spring 框架,因此我们可以基于 Spring 定义生产者和消费者。
生产者
@Configuration
public class KafkaProducerConfig {
@Bean
public ProducerFactory producerFactory() {
Map configProps = new HashMap<>();
configProps.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
configProps.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
configProps.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
configProps.put(ProducerConfig.CLIENT_ID_CONFIG, "your-client-id");
return new DefaultKafkaProducerFactory<>(configProps);
}
@Bean
public KafkaTemplate kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
} 在需要发送消息的地方,我们注入 KafkaTemplate:
@Autowired
private KafkaTemplate kafkaTemplate;
void send(String message) {
ProducerRecord record = new ProducerRecord<>("your-topic-name", message);
kafkaTemplate.send(record);
} 然而,当服务启动并尝试发送消息时,发送不成功,出现以下错误:
org.springframework.kafka.KafkaException: Send failed; nested exception is org.apache.kafka.common.errors.TopicAuthorizationException: Not authorized to access topics: [your-topic-name]错误信息提示鉴权失败。通过查看上下文:
INFO [kafka-producer-network-thread | your-client-id-1]我们发现 ClientId 由 your-client-id 变成了 your-client-id-1,很明显这是由于第三方包做了手脚。通过查看源码:
发现在创建 Producer 时,会调用 getProducerConfigs 方法,该方法内部会对 ClientId 添加自增的后缀。为了解决这个问题,我们需要重写 DefaultKafkaProducer 的 getProducerConfigs 方法:
public class FixedClientIdKafkaProducerFactory extends DefaultKafkaProducerFactory {
private final Map configs;
public FixedClientIdKafkaProducerFactory(Map configs) {
super(configs);
this.configs = configs;
}
@Override
protected Map getProducerConfigs() {
final Map newProducerConfigs = new HashMap<>(this.configs);
checkBootstrap(newProducerConfigs);
return newProducerConfigs;
}
} 然后在 KafkaProducerConfig 中使用 FixedClientIdKafkaProducerFactory 替换 DefaultKafkaProducerFactory。
消费者
@Configuration
@EnableKafka
public class KafkaConsumerConfig {
@Bean
public ConsumerFactory consumerFactory() {
Map props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ConsumerConfig.GROUP_ID_CONFIG, "your-consumer-group-id");
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
return new DefaultKafkaConsumerFactory<>(props);
}
@Bean
public ConcurrentKafkaListenerContainerFactory kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
factory.getContainerProperties().setAckMode(ContainerProperties.AckMode.MANUAL_IMMEDIATE);
return factory;
}
}
@Component
public class MyKafkaMessageListener {
@KafkaListener(topics = "your-topic-name", concurrency = "4", clientIdPrefix = "your-client-id")
public void listen(ConsumerRecord record, Acknowledgment acknowledgment) {
// your business logic
//……
acknowledgment.acknowledge();
}
} 同样,我们遇到了鉴权失败的问题。错误信息如下:
ERROR[org.springframework.kafka.KafkaListenerEndpointContainer#0-4-C-1] o.s.k.l.KafkaMessageListenerContainer.error(149): Authentication/Authorization Exception and no authExceptionRetryInterval set
org.apache.kafka.common.errors.TopicAuthorizationException: Not authorized to access topics: [your-topic-name]通过跟踪源码: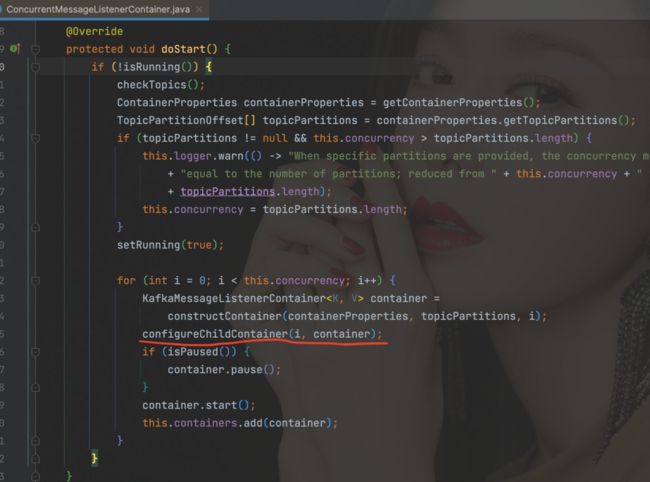

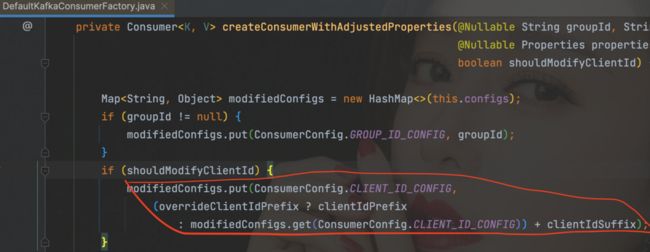
我们发现在容器 ConcurrentMessageListenerContainer 的 doStart 方法中,会根据并行度 concurrency 创建多个 KafkaMessageListenerContainer 子容器,然后调用 configureChildContainer 方法配置子容器,并根据 concurrency 和 alwaysClientIdSuffix 参数对 ClientId 添加后缀。如果并行度设置为 1,那么只需要在 KafkaConsumerConfig 中添加如下代码来设置 alwaysClientIdSuffix:
factory.setContainerCustomizer(container -> container.setAlwaysClientIdSuffix(false));这样就能确保 ClientId 不会被改变,从而完成鉴权操作。但是为了提高消费能力,我们总归需要设置并行度。因此,根据重写生产者的经验,我们重写 DefaultKafkaConsumerFactory 的 createKafkaConsumer 方法:
public class FixedClientIdKafkaConsumerFactory extends DefaultKafkaConsumerFactory {
public FixedClientIdKafkaConsumerFactory(Map configs) {
super(configs);
}
@Override
protected Consumer createKafkaConsumer(String groupId, String clientIdPrefixArg, String clientIdSuffixArg, Properties properties) {
return super.createKafkaConsumer(groupId, clientIdPrefixArg, null, properties);
}
} 然后在 KafkaConsumerConfig 中使用 FixedClientIdKafkaConsumerFactory 替换 DefaultKafkaConsumerFactory。然而,这次却出现了如下错误:
WARN [main] o.a.k.c.u.AppInfoParser.registerAppInfo(68): Error registering AppInfo mbean
javax.management.InstanceAlreadyExistsException: kafka.consumer:type=app-info,id=your-client-id在自定义 ConsumerFactory 以确保在多线程环境下共用相同的 ClientId 时,我们必须考虑到启用 JMX 监控时,MBean 的唯一性问题。JMX MBean 是线程级别的,因此如果出现冲突,可能会影响监控功能。
尽管上述日志只是一个 WARN 级别的记录,不会直接影响消费功能,但如果我们希望通过 JMX 实现精准监控,那么必须要解决这个问题。另外,长期看到一系列的 WARN 日志也会令人不安,因此我们决定继续采用自增后缀的 ClientId 策略。
然而,在申请多个 ClientId 时,需要权衡数量。我们需要考虑 Kafka 集群的鉴权能力,同时也要避免后续扩容时频繁申请 ClientId 的问题。
Kafka 的高级 API 确保在同一个消费者组(consumer group)下,每个分区(partition)只能由一个 Consumer 线程消费(1 个 Consumer 线程可以消费多个 partition)。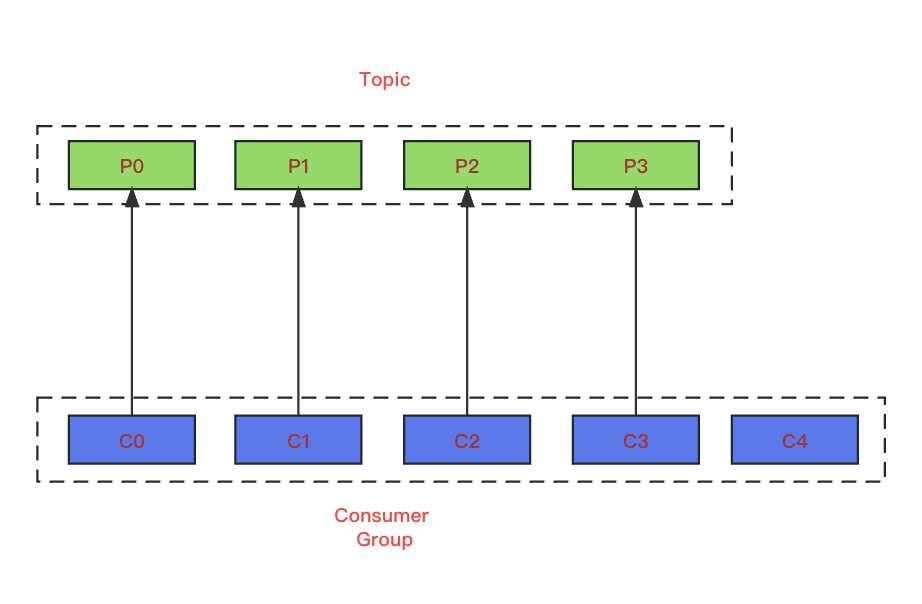
如上,当一个消费者组包含 5 个消费者并且有 4 个分区时,无论这 5 个消费者是以单实例方式部署还是分布式方式部署,都可能出现某个消费者未被分配到分区的情况,这样会造成线程空跑,占据着资源。为了解决这个问题,我们只需确保总消费者数量小于或等于分区数量。
通常情况下,我们的应用中 Kafka Consumer 仅占据一部分流量。因此,我们是否可以约定单个实例的 Kafka Consumer 的最大并发数为某个固定值呢?比如 6 这样一来,在申请 Topic 时,我们可以一并申请 6 个 ClientId,其命名格式为 -0 至 -5。例如,如果我们申请了一个名为 my-topic-test 的 Topic,那么除了默认生成一个 ClientId 为 my-topic-test-GeMp 之外,我们只需再申请 my-topic-test-GeMp-0、my-topic-test-GeMp-1、my-topic-test-GeMp-2、my-topic-test-GeMp-3、my-topic-test-GeMp-4、my-topic-test-GeMp-5 即可。
在后续需要提升消费能力时,我们可以扩展分区数量。根据分区数量进行横向水平扩容,以保证一个消费者组内的总消费者数量等于分区数量。这样,就不需要再担心 ClientId 的鉴权和 JMX 注册问题了。此外,这也确保了在未来需要提升消费能力并进行分区扩容时,无需再次申请 ClientId。
这种做法可以有效地优化 Kafka Consumer 的管理和扩展,以满足我们的需求。
结论
综上所述,我们总结了在使用 ClientId 进行 Kafka 集群环境下的身份验证时,Kafka 生产者和消费者的一种高效使用方式。
申请ClientId
在 Kafka 平台上申请 Topic 时,请根据自动生成的 ClientId 作为前缀,然后使用 "-0" 至 "-5" 作为后缀,额外申请 6 个 ClientId(数量只是建议,可自行根据应用情况设置)。
Maven配置
org.springframework.kafka
spring-kafka
2.8.8
生产者
@Configuration
public class KafkaProducerConfig {
@Bean
public ProducerFactory producerFactory() {
Map configProps = new HashMap<>();
configProps.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
configProps.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
configProps.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
configProps.put(ProducerConfig.CLIENT_ID_CONFIG, "your-client-id");
return new DefaultKafkaProducerFactory<>(configProps);
}
@Bean
public KafkaTemplate kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
}
@Service
public class BusinessServiceImpl implements BusinessService {
@Autowired
private KafkaTemplate kafkaTemplate;
void send(String msg) {
ProducerRecord record = new ProducerRecord<>("your-topic-name", message);
kafkaTemplate.send(record);
}
} 由于 KafkaProducer 是线程安全的,如果要使用多线程的生产者,建议使用单例生产者,然后使用线程池来包装。
消费者
@Configuration
@EnableKafka
public class KafkaConsumerConfig {
@Bean
public ConsumerFactory consumerFactory() {
Map props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ConsumerConfig.GROUP_ID_CONFIG, "your-consumer-group-id");
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
return new DefaultKafkaConsumerFactory<>(props);
}
@Bean
public ConcurrentKafkaListenerContainerFactory kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
factory.getContainerProperties().setAckMode(ContainerProperties.AckMode.MANUAL_IMMEDIATE);
return factory;
}
}
@Component
public class MyKafkaMessageListener {
@KafkaListener(topics = "your-topic-name", concurrency = "6", clientIdPrefix = "your-client-id")
public void listen(ConsumerRecord record, Acknowledgment acknowledgment) {
// 在这儿添加业务逻辑
//……
acknowledgment.acknowledge();
}
} 由于 KafkaConsumer 是非线程安全的,如果要使用多线程的消费者,建议使用 Spring 的 @KafkaListener 注解,并通过配置 concurrency 来实现多线程消费。在单机瓶颈出现时,可以通过横向扩容来进行性能提升。
这里,我们额外提一下,concurrency 要根据实际情况进行设置,单实例的情况下设置的值不要超过分区数量。多实例的情况下,如果实例数量大于等于分区数,就没有必要再去设置 concurrency 了(concurrency 默认是 1)。
请注意上述约定中,ClientId 的数量应根据个人需求进行设定,但强烈建议一次性申请足够数量的 ClientId,以避免后续需要更改。这样,如果需要扩展,只需要横向扩展机器并增加主题分区即可。