mysql-慢查询和索引优化 showfull list
0 mysql cpu 飙高查询
0.1 cpu 飙高查询
mysql是一个多线程的架构,所以从linux主机上观察到的mysqld进程的cpu飙高,通常都是由其下的某个或者某几个线程消耗大量cpu资源。这种情况下,第一步要先确定具体是哪个线程消耗cpu。linux上,最简单的就是用top命令的-H选项:
使用top -d1 -H -p pid命令之后,基本就能显示mysqld进程中按cpu使用率从高到低排序的线程信息,其中最重要的PID列就对应了mysqld中线程的os id,对应在mysql性能视图中是performance_schema.THREAD_OS_ID列。接下来,就可以进入到mysql内部,通过各种性能视图来发现问题。
1,首先,根据如下sql,获取当前cpu高的线程在干啥:
select ts.`THREAD_OS_ID`,esc.*
from performance_schema.threads ts,performance_schema.events_statements_current esc
where ts.`THREAD_OS_ID` in ('')
and esc.`THREAD_ID` = ts.`THREAD_ID`;
这个在大部分情况下就可以了,但是不排除在我们从top中copy出来pid
0.2 方案二
show processlist 史上最全参数详解及解决方案
Mysql占用CPU过高排查过程及可能优化方案
MYSQL最朴素的监控方式 | 京东云技术团队
0.3 使用dms
MySQL CPU 使用率高的原因和解决方法
1.性能工具分析
1.1 统计查询成本
这个查询成本对应的是SQL语句所需要读取的页的数量。
SELECT student_id, class_id, NAME, create_time FROM student_infoWHERE id = 900001;
# 然后再看下查询优化器的成本,实际上我们只需要检索一个页即可:
mysql> SHOW STATUS LIKE 'last_query_cost';
+-----------------+----------+
| Variable_name | Value |
+-----------------+----------+
| Last_query_cost | 1.000000 | #只需要读取1页
+-----------------+----------+
如果我们想要查询 id 在 900001 到 9000100 之间的学生记录呢?
SELECT student_id, class_id, NAME, create_time FROM
student_infoWHERE id BETWEEN 900001 AND 900100;
# 然后再看下查询优化器的成本,这时我们大概需要进行 20 个页的查询。
mysql> SHOW STATUS LIKE 'last_query_cost';
+-----------------+-----------+
| Variable_name | Value |
+-----------------+-----------+
| Last_query_cost | 21.134453 | #需要读取21页
+-----------------+-----------+
你能看到页的数量是刚才的 20 倍,但是查询的效率并没有明显的变化,实际上这两个 SQL 查询的时间基本上一样,就是因为采用了顺序读取的方式将页面一次性加载到缓冲池中,然后再进行查找。虽然 页 数量(last_query_cost)增加了不少 ,但是通过缓冲池的机制,并 没有增加多少查询时间 。
2.慢sql查询
show variable like 'slow_query_log%';

// 配置文件
[mysqld]
slow_query_log=ON # 开启慢查询日志开关
slow_query_log_file=/var/lib/mysql/atguigu-low.log # 慢查询日志的目录和文件名信息
long_query_time=3 # 设置慢查询的阈值为3秒,超出此设定值的SQL即被记录到慢查询日志
log_output=FILE
// 分析慢日志
mysqldumpslow -s -c -t 10 /data/mxxx
-c 表示次数
如果不指定存储路径,慢查询日志默认存储到MySQL数据库的数据文件夹下。如果不指定文件名,默认文件名为hostname_slow.log。
2.1 开启慢查询
# 我们可以看到 `slow_query_log=OFF`,我们可以把慢查询日志打开,
#注意设置变量值的时候需要使用 global,否则会报错:
mysql > set global slow_query_log='ON';
2. 修改 long_query_time 阈值
#测试发现:设置global的方式对当前session的long_query_time失效。对新连接的客户端有效。所以可以一并
执行下述语句
mysql > set global long_query_time = 1;
mysql> show global variables like '%long_query_time%';
mysql> set long_query_time=1;
mysql> show variables like '%long_query_time%';
2.2 查看慢查询数目
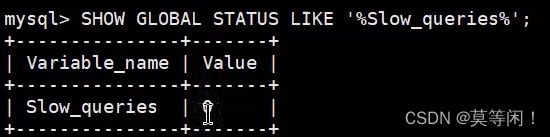
查询当前系统中有多少条慢查询记录
SHOW GLOBAL STATUS LIKE '%Slow_queries%';
2.3 mysqldumpslow 分析工具
- -a: 不将数字抽象成N,字符串抽象成S
- -s: 是表示按照何种方式排序:
- c: 访问次数
- l: 锁定时间
- r: 返回记录
- t: 查询时间
- al:平均锁定时间
- ar:平均返回记录数
- at:平均查询时间 (默认方式)
- ac:平均查询次数
- -t: 即为返回前面多少条的数据;
- -g: 后边搭配一个正则匹配模式,大小写不敏感的;
我们想要按照查询时间排序,查看前五条 SQL 语句,这样写即可:
mysqldumpslow -s t -t 5 /var/lib/mysql/atguigu01-slow.log
[root@bogon ~]# mysqldumpslow -s t -t 5 /var/lib/mysql/atguigu01-slow.log
Reading mysql slow query log from /var/lib/mysql/atguigu01-slow.log
Count: 1 Time=2.39s (2s) Lock=0.00s (0s) Rows=13.0 (13), root[root]@localhost
SELECT * FROM student WHERE name = 'S'
Count: 1 Time=2.09s (2s) Lock=0.00s (0s) Rows=2.0 (2), root[root]@localhost
SELECT * FROM student WHERE stuno = N
Died at /usr/bin/mysqldumpslow line 162, <> chunk 2.
工作中使用参考
#得到返回记录集最多的10个SQL
mysqldumpslow -s r -t 10 /var/lib/mysql/atguigu-slow.log
#得到访问次数最多的10个SQL
mysqldumpslow -s c -t 10 /var/lib/mysql/atguigu-slow.log
#得到按照时间排序的前10条里面含有左连接的查询语句
mysqldumpslow -s t -t 10 -g "left join" /var/lib/mysql/atguigu-slow.log
#另外建议在使用这些命令时结合 | 和more 使用 ,否则有可能出现爆屏情况
mysqldumpslow -s r -t 10 /var/lib/mysql/atguigu-slow.log | more
2.4 show profile
日常开发需注意的结论:
converting HEAP to MyISAM: 查询结果太大,内存不够,数据往磁盘上搬了。creating tmp table:创建临时表。先拷贝数据到临时表,用完后再删除临时表。Copying to tmp table on disk:把内存中临时表复制到磁盘上,警惕!locked。
如果在show profile诊断结果中出现了以上4条结果中的任何一条,则sql语句需要优化。
3.explain
3.1 table
用到多少个表,就会有多少条记录
3.2 id
正常来说一个select 一个id ,也有例外的可能,查询优化器做了优化
3.3. select_type
#对于包含UNION或者UNION ALL或者子查询的大查询来说,它是由几个小查询组成的,其中最左边的那个
#查询的select_type值就是PRIMARY
#对于包含UNION或者UNION ALL的大查询来说,它是由几个小查询组成的,其中除了最左边的那个小查询
#以外,其余的小查询的select_type值就是UNION
#MySQL选择使用临时表来完成UNION查询的去重工作,针对该临时表的查询的select_type就是UNION RESULT
EXPLAIN SELECT * FROM s1 UNION SELECT * FROM s2;

EXPLAIN SELECT * FROM s1 UNION ALL SELECT * FROM s2;

SUBQUERY
非相关子查询
#子查询:
#如果包含子查询的查询语句不能够转为对应的semi-join的形式,并且该子查询是不相关子查询。
#该子查询的第一个SELECT关键字代表的那个查询的select_type就是SUBQUERY
EXPLAIN SELECT * FROM s1 WHERE key1 IN (SELECT key1 FROM s2) OR key3 = 'a';

DEPENDENT SUBQUERY
相关子查询
#如果包含子查询的查询语句不能够转为对应的semi-join的形式,并且该子查询是相关子查询,
#则该子查询的第一个SELECT关键字代表的那个查询的select_type就是DEPENDENT SUBQUERY
EXPLAIN SELECT * FROM s1
WHERE key1 IN (SELECT key1 FROM s2 WHERE s1.key2 = s2.key2) OR key3 = 'a';
#注意的是,select_type为DEPENDENT SUBQUERY的查询可能会被执行多次。

3.4 type **
const
当我们根据主键或者唯一的二级索引(unique index)列与常熟进行等值匹配的时候,对单表的访问就是const
EXPLAIN SELECT * FROM s1 WHERE id = 10005;
EXPLAIN SELECT * FROM s1 WHERE key2 = '10066';
eq_ref
连接查询的时候,被驱动表 是通过 主键或者 唯一索引,进行等值匹配的方式进行访问,则被驱动表的访问方法是 eq_ref
EXPLAIN SELECT * FROM s1 INNER JOIN s2 ON s1.id = s2.id;
mysql> EXPLAIN SELECT * FROM s1 INNER JOIN s2 ON s1.id = s2.id;
+----+------------+------+--------+---------+---------+------------------+------+
| id | select_type| table| type | key | key_len | ref | rows |
+----+------------+------+--------+---------+---------+------------------+------+
| 1 | SIMPLE | s1 | ALL | NULL | NULL | NULL | 9895 |
| 1 | SIMPLE | s2 | eq_ref | PRIMARY | 4 | atguigudb1.s1.id | 1 |
+----+------------+------+--------+---------+---------+------------------+------+
ref
#当通过普通的二级索引列与常量进行等值匹配时来查询某个表,
#那么对该表的访问方法就可能是`ref`
EXPLAIN SELECT * FROM s1 WHERE key1 = 'a';
mysql> EXPLAIN SELECT * FROM s1 WHERE key1 = 'a';
+----+-------+------+---------------+----------+---------+
| id | table | type | possible_keys | key | key_len |
+----+-------+------+---------------+----------+---------+
| 1 | s1 | ref | idx_key1 | idx_key1 | 303 |
+----+-------+------+---------------+----------+---------+
range
索引的范围查询
#如果使用索引获取某些`范围区间`的记录,那么就可能使用到`range`访问方法
EXPLAIN SELECT * FROM s1 WHERE key1 IN ('a', 'b', 'c');
#同上
EXPLAIN SELECT * FROM s1 WHERE key1 > 'a' AND key1 < 'b';
index
全表扫描,只是扫描表的时候按照索引次序进行而不是行。主要优点就是避免了排序, 但是开销仍然非常大。
当我们可以使用索引覆盖,但需要扫描全部的索引记录时,
该表的访问方法就是index(查询的字段也是索引)
EXPLAIN SELECT key_part2 FROM s1 WHERE key_part3 = 'a';
索引覆盖,
INDEX idx_key_part(key_part1, key_part2, key_part3)这3个构成一个复合索引 key_part3 在复合索引里面,,查询的字段也在索引里面,干脆就直接遍历索引查出数据
不需要回表
思考: 好处,索引存的数据少,数据少页就少,这样可以减少io。
all 全表扫描 避免
小结:
结果值从最好到最坏依次是:
system > const > eq_ref > ref >
fulltext > ref_or_null > index_merge >unique_subquery > index_subquery > range >
index > ALL
SQL 性能优化的目标:至少要达到 range 级别,要求是 ref 级别,最好是 consts级别。(阿里巴巴开发手册要求)
3.5 key_len 联合索引 **
-
key_len:实际使用到的索引长度(即:字节数)
-
key_len越小 索引效果越好 这是前面学到的只是,短一点效率更高
-
但是在联合索引里面,命中一次key_len加一次长度。越长代表精度越高,效果越好
EXPLAIN SELECT * FROM s1 WHERE id = 10005;
## 结果key_len =4
mysql> EXPLAIN SELECT * FROM s1 WHERE key2 = 10126;
## 结果key_len = 5
key2 是int 类型 unique 索引。。因为还可能有一个null值,所以 null占一个字段。4+1 = 5
mysql> EXPLAIN SELECT * FROM s1 WHERE key1 = 'a';
## 结果key_len = 303
varchar(100) utf8 1字符=3B
100*3+1(null)+2(记录varchar 长度)=303B
联合索引问题 key_len
mysql> EXPLAIN SELECT * FROM s1 WHERE key_part1 = 'a' AND key_part2 = 'b';
+----+------------+-----+---------------+--------------+---------+------------
| id | select_type|type | possible_keys | key | key_len | ref
+----+------------+-----+---------------+--------------+---------+------------
| 1 | SIMPLE |ref | idx_key_part | idx_key_part | 606 | const,const
+----+------------+-----+---------------+--------------+---------+------------
1 row in set, 1 warning (0.00 sec)
结果key_606
这里命中了两次联合索引,精度更高,效果更好
key_len的长度计算公式:
varchar(10)变长字段且允许NULL =
10 * ( character set:utf8=3,gbk=2,latin1=1)+1(NULL)+2(变长字段)
varchar(10)变长字段且不允许NULL =
10 * ( character set:utf8=3,gbk=2,latin1=1)+2(变长字段)
char(10)固定字段且允许NULL =
10 * ( character set:utf8=3,gbk=2,latin1=1)+1(NULL)
char(10)固定字段且不允许NULL =
10 * ( character set:utf8=3,gbk=2,latin1=1)
3.6 rows *
# 9. rows:预估的需要读取的记录条数
# `值越小越好`
# 通常与filtered 一起使用
EXPLAIN SELECT * FROM s1 WHERE key1 > 'z';
rows 值越小,代表,数据越有可能在一个页里面,这样io就会更小。
3.7 filtered
越大越好
filtered 的值指返回结果的行占需要读到的行(rows 列的值)的百分比。
EXPLAIN SELECT * FROM s1 WHERE
key1 > 'z' AND common_field = 'a';

对于单表查询来说,这个filtered列的值没什么意义,我们更关注在连接查询中驱动表对应的执行计划记录的filtered值,它决定了被驱动表要执行的次数(即:rows * filtered)
EXPLAIN SELECT * FROM s1 INNER JOIN s2
ON s1.key1 = s2.key1 WHERE s1.common_field = 'a';

3.8 extra
更准确的理解MySQL到底将如何执行给定的查询语句
using index 覆盖所有
覆盖索引 不需要回表了
当我们的查询列表以及搜索条件中只包含属于某个索引的列,也就是在可以使用覆盖索引的情况下,在Extra列将会提示该额外信息。
比方说下边这个查询中只需要用到idx_key1而不需要回表操作:
EXPLAIN SELECT key1 FROM s1 WHERE key1 = 'a';

Using index condition 索引下推
索引下推理解
有些搜索条件中虽然出现了索引列,但却不能使用到索引看课件理解索引条件下推
SELECT * FROM s1 WHERE key1 > 'z' AND key1 LIKE '%a';
mysql> EXPLAIN SELECT * FROM s1 WHERE key1 > 'z' AND key1 LIKE '%a';

步骤1. 这里key1 > ‘z’ 走了索引,查出了378条数据。。。
—1—
步骤2. key1 LIKE ‘%b’; 这个条件依然是 key1 索引,,,所以接下来只要在遍历这378个索引。哪些符合 ‘%a’
–2–
步骤3. 通过步骤2 过滤出了有效 索引。。 这就是Using index condition 。
–3–
步骤4. 把符合条件的索引,进行回表查询。
完整的说明:
其中的key1 > 'z'可以使用到索引,但是key1 LIKE '%a '却无法使用到索引,在以前版本的MySQL中,是按照下边步骤来执行这个查询的:
- 先根据key1 > 'z’这个条件,从二级索引
idx_key1中获取到对应的二级索引记录。 - 根据上一步骤得到的二级索引记录中的主键值进行回表,找到完整的用户记录再检测该记录是否符合
key1 LIKE '%a'这个条件,将符合条件的记录加入到最后的结果集。
但是虽然key1 LIKE ‘%a'不能组成范围区间参与range访问方法的执行,但这个条件毕竟只涉及到了key1列,所以MySQL把上边的步骤改进了一下:
-
先根据
key1 > 'z'这个条件,定位到二级索引idx_key1中对应的二级索引记录。 -
对于指定的二级索引记录,先不着急回表,而是先检测一下该记录是否满足
key1 LIKE ‘%a'这个条件,如果这个条件不满足,则该二级索引记录压根儿就没必要回表。 -
对于满足
key1 LIKE '%a'这个条件的二级索引记录执行回表操作。
我们说回表操作其实是一个随机IO,比较耗时,所以上述修改虽然只改进了一点点,但是可以省去好多回表操作的成本。MySQL把他们的这个改进称之为索引条件下推 (英文名: Index Condition Pushdown )。如果在查询语句的执行过程中将要使用索引条件下推这个特性,在Extra列中将会显示Using index condition
using join buffer *
没有索引的字段进行表关联。
在连接查询执行过程中,当被驱动表不能有效的利用索引加快访问速度,MySQL一般会为其分配一块名叫join buffer的内存块来加快查询速度,也就是我们所讲的基于块的嵌套循环算法
mysql> EXPLAIN SELECT * FROM s1 INNER JOIN s2
ON s1.common_field = s2.common_field;

using filesort *
有一些情况下对结果集中的记录进行排序是可以使用到索引的,比如下边这个查询:
EXPLAIN SELECT * FROM s1 ORDER BY key1 LIMIT 10;
这个查询语句可以利用idx_key1索引直接取出key1列的10条记录,然后再进行回表操作就好了。
但是很多情况下排序操作无法使用到索引,只能在内存中(记录较少的时候)或者磁盘中(记录较多的时候)进行排序,MySQL把这种在内存中或者磁盘上进行排序的方式统称为文件排序(英文名: filesort)。如果某个查询需要使用文件排序的方式执行查询,就会在执行计划的Extra列中显示Using filesort提示
EXPLAIN SELECT * FROM s1 ORDER BY common_field LIMIT 10;
Using temporary *
MySQL可能会借助临时表来完成一些功能,比如去重、排序之类的,比如我们在执行许多包含DISTINCT、GROUP BY、UNION等子句的查询过程中,如果不能有效利用索引来完成查询,MySQL很有可能寻求通过建立内部的临时表来执行查询。
EXPLAIN SELECT DISTINCT common_field FROM s1;

使用了索引
EXPLAIN SELECT DISTINCT key1 FROM s1;
那就不会出现 using tempory
4.排序优化
- SQL中,可以在WHERE子句和ORDER BY子句中使用索引,目的是在WHERE子句中
避免全表扫描,在ORDER BY子句避免使用FileSort排序。当然,某些情况下全表扫描,或者FileSort排序不一定比索引慢。但总的来说,我们还是要避免,以提高查询效率。 - 尽量使用Index完成ORDER BY排序。如果WHERE和ORDER BY后面是相同的列就使用单索引列;如果不同
就使用联合索引。 - 无法使用Index时,需要对FileSort方式进行调优。
如果无法避免使用FileSort,.- 尝试提高sort_buffer_size(默认1MB) 单路
从磁盘读取查询需要的所有列,按照order by列在buffer(sort_buffer_size)对他们,但是它会使用更多的空间,因为它把每一效率更快一些,避免了第二次读取数据。并且把随机Io变成了顺序IO,行都保存在内存中了。
- 尝试提高sort_buffer_size(默认1MB) 单路
order by时不limit,索引失效
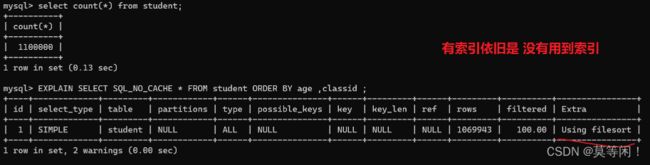
#创建索引
CREATE INDEX idx_age_classid_name ON student (age,classid, NAME);
#不限制,索引失效
EXPLAIN SELECT SQL_NO_CACHE * FROM student ORDER BY age ,classid ;
这里优化器觉得,,还需要回表。会费时间更大,不走索引。
order by 顺序错误 不索引 最左前缀
order by(↑ ↓ 升降序) 错误,不索引
无过滤 不索引

4.1 案例实战
ORDER BY子句,尽量使用Index方式排序,避免使用FileSort方式排序。
DROP INDEX idx_age ON student;
DROP INDEX idx_age_classid_stuno ON student;DROP INDEX idx_age_classid_name ON student;
#或者
call proc_drop_index( 'my_sql' , ' student' ) ;
show index from student;
场景:查询年龄为30岁的,且学生编号小于101000的学生,按用户名称排序
EXPLAIN SELECT SQL_NO_CACHE * FROM student
WHERE age = 30 AND stuno <101000 ORDER BY NAME;

方案1
当【范围条件】和【group by或者order by】的字段出现二选一时,优先观察条件字段的过滤数量
添加where 等值索引 和 排序索引
#创建新索引
CREATE INDEX idx_age_name ON student(age , NAME);
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 30 AND stuno <101000 ORDER BY NAME;

方案二:尽量让where的过滤条件和排序使用上索引
create index idx_age_stuno_name on student(age,stuno,name);
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 30 AND stuno <101000 ORDER BY NAME;

下面这个方案虽然使用了 Using filesort 但是速度反而更快了。
所有的排序都是在条件过滤之后才执行的。所以,如果条件过滤掉大部分数据的话,剩下几百几千条数据进行排序其实并不是很消耗性能,即使索引优化了排序,但实际提升性能很有限。相对的stuno<101000这个条件,如果没有用到索引的话,要对几万条的数据进行扫描,这是非常消耗性能的,所以索引放在这个字段上性价比最高,是最优选择。
结论:
1.两个索引同时存在,mysql自动选择最优的方案。(对于这个例子mysql选择idx_age_stuno_name)。但是,随着数据量的变化,选择的索引也会随之变化的。
2.当【范围条件】和【group by或者order by】的字段出现二选一时,优先观察条件字段的过滤数量,
如果过滤的数据足够多,而需要排序的数据并不多时,优先把索引放在范围字段上。反之,亦然。
4.2 覆盖索引
一个索引包含了满足查询结果的数据就叫覆盖索引。
覆盖索引利弊
好处
避免innodb 回表,
把随机io变成顺序io
弊端
索引字段维护需要代价
4.3 索引条件下推
innodb 表icp 仅用于二级索引,对于主键索引,覆盖索引用不上。
第一个查询字段和第二个查询字段组成联合索引,
但是第二个查询字段用不上索引(比如name=%张%),在索引条件和包含第二个字段,那就先不需要回表,在第一个条件用上索引过滤出来的结果(加入过滤出100条,)里面进行筛选过滤(筛选出10条)。对最后结果(10条)回表。
innodb 5.6新特性
using index condition
减少回表次数,减少io次数。
更多情况针对联合索引
![]()
SELECT *FROM people
WHERE zipcode= '000001'
AND lastname LIKE '%张%'
AND address LIKE '%北京市%';

执行查看SQL的查询计划,Extra中显示了
Using index condition,这表示使用了索引下推。另外,Usingwhere表示条件中包含需要过滤的非索引列的数据,即address LIKE '%北京市%'这个条件并不是索引列,需要在服务端过滤掉。
4.4 optimizer_trace
SET optimizer_trace="enabled=on"; // 打开 optimizer_trace
SELECT * FROM order_info where uid = 5837661 order by id asc limit 1
SELECT * FROM information_schema.OPTIMIZER_TRACE; // 查看执行计划表
SET optimizer_trace="enabled=off"; // 关闭 optimizer_trace
分析 row_estimation 查询全部扫描的cost 代价。
potential_range_index, 列出表中所有的索引并分析其是否可用
analyzing_range_alternatives 查看各个索引使用的代价。
通过 chosen_range_access_summary 选择摘要 ,选择了cost 代价最少的哪个索引。
查看
reconsidering_access_paths_for_index_ordering 考虑排序带来的索引选择。
通过 index_order_summary