再见MYSQL - 06 - 查询性能优化
查询优化 索引优化 表库结构优化 三架马车
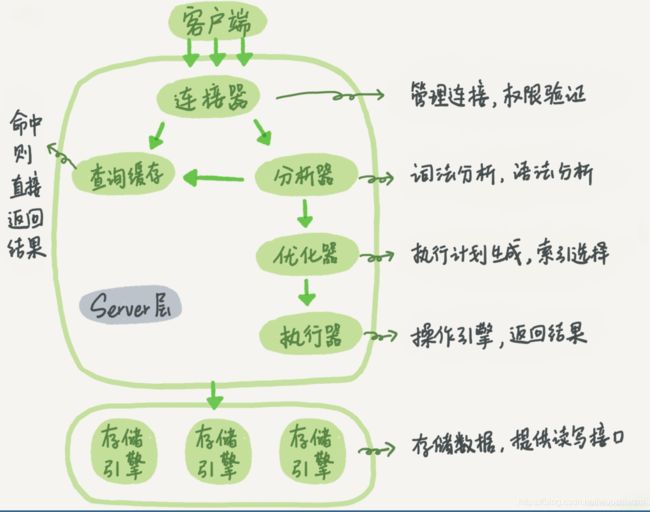
6.1 查询为什么会慢 ?
真正重要的是响应时间
把查询看做一个任务,则他由多个子任务组成
- 优化子任务
- 消除一部分子任务
- 减少子任务的执行次数
- 让子任务运行的更快

查询 会消耗 网络, CPU计算, 生成统计信息,执行计划,锁等待(互斥等待)
尤其是向底层存储引擎检索数据的调用操作, 会在内存操作,CPU操作 和 内存不足时导致I/O操作上消耗时间。
上下文切换, 系统 调用
一个很慢的查询,往往存在
- 额外操作
- 某些操作被额外重复了很多次
- 某些操作执行太慢
6.2 慢查询基础:优化数据访问
最基本原因:访问数据太多 而大部分情况下都不必这样
- 确认是否检索超过需要的数据 , 访问了太多的行 或 列
- 确认Mysql是否分析大量超过需要的数据行
6.2.1 是否请求了不需要的数据
你以为Mysql只会返回需要的数据,实际上它是先返回全部结果集,再进行计算。
-
加上LIMIT ,可以使MYSQL 只查到指定数量的结果就停止,没有LIMIT, 会一次查出所有,再丢弃大量不需要的结果
-
多表关联时返回全部列

-
总是取出全部列 SELECT * 一定要避免
-
重复查询相同的数据
6.2.2 是否在扫描额外的记录
- 响应时间
- 扫描的行数
- 返回的行数
响应时间 = 服务时间 + 排除时间
扫描的行数和返回的行数
- 较短的行访问较快
- 内存的行比磁盘的行访问更快
一般扫描行数与结果在 10:1 ~ 1:1 之前比较合适
扫描的行数和访问类型
返回一行结果, 访问方式 有可能要扫描多行, 也有可能不扫描就返回结果。
EXPLAIN 语句中的type列反应了访问类型。
速度递进顺序:
- 全表扫描
- 索引扫描
- 范围扫描
- 唯一索引查询
- 常数引用
增加索引是提升速度的好办法,怎么增加索引看前一章
以下面查询为例
mysql> EXPLAIN
mysql> SELECT * FROM sakila.film_actor WHERE film_id =1 ;
这个查询将返回10行数据, 在索引 idx_fk_film_id 上使用了 ref 访问类型 进行查询

如果删除索引 就变成全文查询,查了 5073行, Using where 表示 通过WHERE 条件筛选这5073条记录,差别是不是很大呢?

最好是index+where, 然后是index , 最坏就是只有where

很遗憾,Mysql不会告诉我们实际上需要扫描多少行数据,而只会告诉我们它已经扫描了多少行。这其中可能大部分已经被 WHERE 过滤了,但它还是会扫描。
**理解一个查询需要扫描多少行和实际 需要使用的行数 **就需要理解 这背后的逻辑和思想。
如果出现要扫描大量数据但只返回少数的行,可以使用下面的技巧。(虽然看起来都挺麻烦)

6.3 重构查询的方式
最终是要获取一样的结果,而不是一样的结果集。同时是要性能更好 更快。
有时候将查询转换一种写法,有时用另一种方式查询。 重构查询
6.3.1 一个复杂查询还是多个简单查询
MySQL 在设计上让连接和断开连接都很轻量级,在返回一个小的查询结果方面很高效。每秒运行超过10万个小查询也不是大问题。
但是 响应数据给客户端就慢得多了,所以尽可能使用少的查询当然更好,但是有时候也有这样做的必要。 需要好好衡量。
6.3.2 切分查询
比如删除旧数据,定期清理大量数据时,如果用大的语句一次性完成 会锁住很多表。
把一个大的DELETE拆分成多个小的DELETE, 这样就可以提升性能,减少mysql复制的延迟。
例如下面的每月都要进行的查询:
一次删除10000 行是比较合理的量。高效对服务器影响也最小。
而且每次删除后都暂停一下再做下一次删除,这就可以执行已经在排除的其他查询 。可以大大减少删除时锁的持有时间。

6.3.2 分解关联查询

这样改的好处如下:

6.4 查询执行的基础
注意 查询优化器是其中最复杂 最难理解的部分
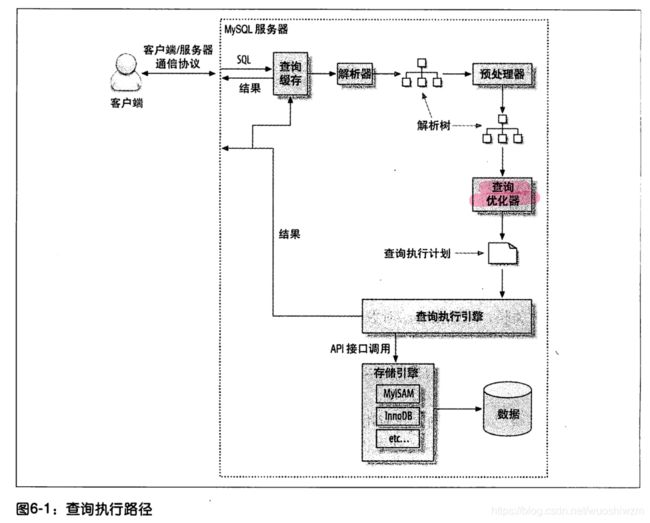
6.4.1 mySQL 客户端 / 服务器通信协议
半双工: 要么服务器向客户发数据,要么客户端向服务器发数据
这种方式 简单快速,也有限制:

max_allow_packet 一旦客户端 发送了请求,它能做的事情就只有等待结果了。
如果查询太大,服务 端会拒绝接收更多的数据并抛出相应的错误 。
相反,一般服务器响应给用户的数据通常很多,有多个数据包。客户端不应该只取前面几条结果,然后让服务器停止发送数据。(你也没法这样做,因为“半双工”)。这也是为什么要在查询中加上LIMIT 限制的原因。
客户端 从服务器端 “拉数据”的过程 ,其实是服务器给客户端发数据,客户端接收。“从消防水管喝水”
结果集是缓存在内存中,直到结果全部返回给客户端了,才会清除。
这就是说整个查询越早完成,服务 器端越早轻松。

查询状态
SHOW FULL PROCESSLIST
mysql> SHOW FULL PROCESSLIST;
+----+------+-----------+------+---------+------+----------+-----------------------+-----------+---------------+
| Id | User | Host | db | Command | Time | State | Info | Rows_sent | Rows_examined |
+----+------+-----------+------+---------+------+----------+-----------------------+-----------+---------------+
| 2 | root | localhost | NULL | Query | 0 | starting | SHOW FULL PROCESSLIST | 0 | 0 |
+----+------+-----------+------+---------+------+----------+-----------------------+-----------+---------------+
1 row in set (0.00 sec)
了解这些状态可以知道当前 “谁正在持球”
在一个繁忙的服务器上,可能会看到大量不正常的状态,例如 statistics 占用大量的时间。
通常表示某个地方有异常了。


6.4.2 查询缓存
MySQL 优先查询缓存,大小写敏感,即使只有一个字节不同,也不会匹配。
如果命中,查询结果之前MySQL 会检查一次用户权限,这一步也不做SQL解析 。
6.4.3 查询优化处理
查询生命周期下一步是将一个SQL 转换成一个执行计划。
三步:,任何一步出错都会终断SQL的执行
- 解析 SQL
- 预处理
- 优化SQL 执行计划
语法解析器和预处理
关键字 解析树 验证语法
查询优化器
基于成本的优化器: 预测成本 , -> 再选择一个成本最小的
成本公式变的复杂了
可能通过查询当前会话的 last_query_cost 的值来得知当前查询的成本
mysql> SELECT COUNT(1) FROM mbook.md_books;
+----------+
| COUNT(1) |
+----------+
| 1 |
+----------+
1 row in set (0.00 sec)
mysql> SHOW STATUS LIKE 'last_query_cost';
+-----------------+----------+
| Variable_name | Value |
+-----------------+----------+
| Last_query_cost | 1.199000 |
+-----------------+----------+
1 row in set (0.00 sec)

这里表示 优化器认为大概需要做1040个数据页的随机查找才能完成上面的查询
** 有很多原因导致 优化器会选择错误的执行计划**
- 统计信息不准确。 innodb 不能维护一个数据表的行数的精确统计信息
- 计划中的成本不等于实际执行的成本。 MySQL不知道哪些页面在内存中,哪些在磁盘上。
- MySQL的最优可能和你想的最优不一样,不一定是最快的
- MySQL不考虑并发的其他查询
- MySQL不是任何时候都是基本成本优化。 如果存在全文搜索的MATCH()子句,会优先用全文索引,即使这不一定是最快的。
- MySQL不会考虑不受其控制的操作成本,如存储过程或用户自定义函数的成本
- 优化器有时候无法估算所有可能的执行计算,有可能错过最优的
静态优化
解析树,只做一次,参数变化不影响,“编译时优化”
动态优化
和查询,上下文有关, “运行时优化”
MySQL能够处理的优化类型
- 重新定义关联表的顺序
- 外连接转内连接
- 等价变换 如(5 = 5 AND a>5 转换为 a>5)
- 优化 COUNT() MIN() MAX()
索引和列是否是 NOT NULL可以帮助MySQL优化这类表达式。 - 预估并转化为常数表达式
有时一个查询也能够转化为一个常数。
例如在索引上执行MIN(), 主键或者唯一键查找语句也可以转换为常数表达式。
如果WHERE使用了这类索引的常数条件,可以在查询开始阶段就先查找到这些值,使用常数表达式。


-
覆盖索引扫描
索引包含所有查询字段 -
子查询优化
MySQL有时将子查询转换一种效率更高的形式 -
提前终止查询
当发现满足查询时,MySQL 总是 能立刻终止查询。
如使用LIMIT
发现一个不成立条件


-
等值传播

- 列表 IN() 的比较
其他数据库中,IN() 完全等于多个OR条件子句,但是MySQL不是。
MySQL先将IN()中的数据排序, 再按 二分法进行查找,这个过程的复杂度是O(log n), 而转化为 OR 的复杂度是 O(n), 数据量大时效果更好。
数据索引和统计信息
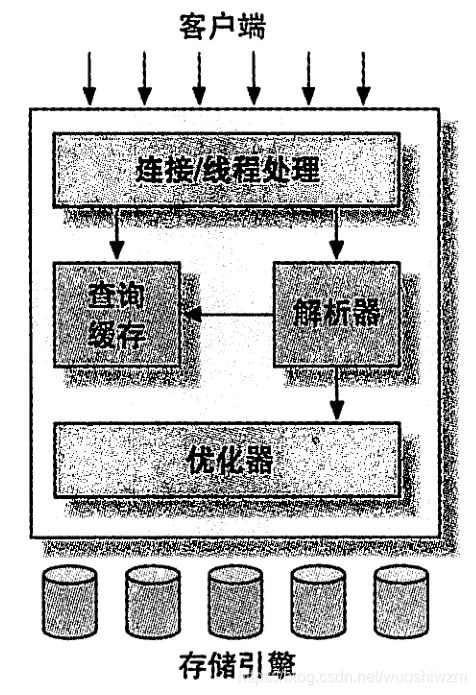
服务器层有查询优化器, 却没有保存数据和索引的统计信息
统计信息由存储引擎实现 ,服务器层不实现 ,而是找引擎层要
MySQL 如何执行关联查询
MySQL认为任何一次查询都是一次关联,所以理解MySQL如何执行关联查询 很有必要
- UNION 查询
先将一系列的单独查询放到一个临时表中,然后再重新读出临时表数据完成 UNION 操作。 读取临时表也是一次关联。
MySQL对任何关联都执行嵌套循环关联操作, 即先在一个表中循环取出单条数据,然后再嵌套循环到下一个表中寻找匹配的行,直到找到所有的,表中匹配的行为止,再后在返回需要的各个列。
例子:

下面的伪代码表示这个过程就非常清楚了
外面循环,然后里面循环

对于单表查询,只需要外层的循环就行了
也可以用泳道图来表示 (这个更清楚一些)

MySQL对所有的查询都按这个套路,例如FROM, 子句中有子查询,先执行子查询,放到临时表中,然后当成一个普通表
MySQL不支持全外连接,可以也是因为全外连接存在完全不关联的表,无法用这种方式走下去。
执行计划
和其他的数据库不同,MySQL的执行计划是一颗指定树
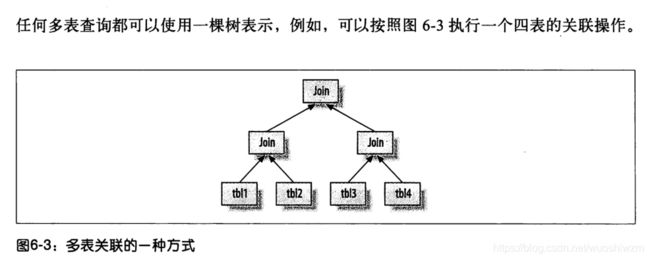
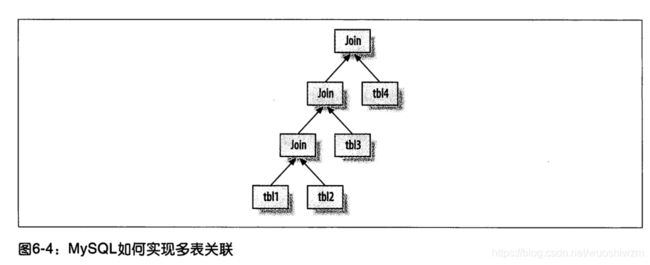
关联查询优化器
决定关联顺序
当优化器给出的不是最优的方式, 可以使用 STRAIGHT_JOIN 重写查询
![]()
当表太多, 比如有n个表关联,就有n! 种关联顺序,这时MySQL会进入“贪婪”模式,
当关联表的数量超过optimizer_search_depth时就会进入 “贪婪”模式了
而使用左连接而不是inner join时, 顺序一般不能换,这时就会进少 MySQL参与的可能
排序优化
文件排序(filesort): 不使用索引,内存, 硬盘
-
两次传输排序:
读取行指针和需要排序的字段,进行排序, 然后再根据排序结果读取所需要的数据行。 第二次读取的成本比较高。 -
单次传输排序
先读所有列,再对指定列排序,最后直接返回结果。一次搞定,如果列非常多,非常大,会占用大量空间。
MySQL会坟每一个记录分配一个足够长的** 定长 **来存放。
-
关联排序
如果ORDER BY 都来自一个表,在之前就会排好, EXPLAIN 结果就会有 “Using filesort", 其他情况,会把关联结果存在一个临时表中,关联结束后再进行排序,这时就会有 “Using temporary; Using filesort” -
LIMIT 会在排序之后应用 ,所以即使有LIMIT, 排序也会耗费大量资源
6.4.4 查询查询引擎
是一个数据结构,不是生成字节码。
执行过程中,大量操作调用** 存储引擎接口 handleer API **。
每一个表由一个handler的实例表示 。
存储引擎接口功能丰富,但是底层的接口只有几十个。
所有引擎共有的特性则有服务器层实现
6.5 MySQL 查询优化器的局限性
“嵌套循环”不是对每种查询都是最优的。
不过还好只对少部分查询不适用。5.6 以后会更好
6.5.1 关联子查询
子查询实现的不好。最糟的一类查询是WHERE 条件中包含IN()的子查询。
如下面的查询

MySQL不是先查括号里面的方式。而是:
将相关的外层表压到子查询中(它认为这样更高效):

这时,子查询就要根据 film_id 来关联外部表 film (因为 AND 后面 那一段)
相关子查询
这时的子查询需要根据film_id来关联外部表film,因为需要film_id字段,所以MySQL认为无法先执行这个子查询。通过EXPLAIN我们可以看到子查询是相关子查询(DEPENDENT SUBQUERY), 可以通过 EXPLAIN EXTENDED 来查看这个查询被改写成什么样子。

可以看到 MySQL先进行了全表扫描,然后根据返回的 film_id再进行子查询。
试想,如果film表非常大,这个全表扫描就要命了。
我们可以很容易的重写: INNER JOIN

**GROUP_CONTACT()**优化, 在 IN()中构造一个由逗号分隔的列表。
IN() 加子查询,性能不好,所以建议用EXISTS()等效的改写查询来获取更好的效率。

如何用好相关子查询
关联子查询实际上是一种非常合理,自然, 甚至性能最好的写法。
下面例子建议使用左外连接(LEFT OUTER JOIN)重写该查询,以代替子查询。理论上执行计划不变。

修改为:

有以下几点不同:

现实中,我们建议通过一些测试来判断使用哪种写法更快。可以看到 LEFT JOIN 好一些。
