C语言数据结构——带头双向循环链表的实现
文章目录
- 前言
- 双链表的实现
-
- DoubleList.h
- void ListPrint(ListNode* phead)
- ListNode* BuyListNode(LTDataType x)
- void InitList(ListNode** pphead)
- void ListPushBack(ListNode* phead, LTDataType x)
- void ListPopBack(ListNode* phead)
- void ListPushFront(ListNode* phead, LTDataType x)
- void ListPopFront(ListNode* phead)
- ListNode* ListFind(ListNode* phead, LTDataType x)
- void ListInsert(ListNode* pos, LTDataType x)
- void ListErase(ListNode* pos)
- Destroy & Clear
- 结束语
前言
为什么博主只写了双链表的实现,主要是考虑了一下带头双向循环链表的优势远远大于无头单向非循环链表,重点体现在结点的插入与删除这方面上。
另外不知道大家是否了解顺序表,已经它与链表之间的区别呢?
博主在这里先为大家介绍一下它们:
1、顺序表就是在数组的基础上实现增删查改,并且插入时可以动态增长
顺序表的缺陷:
a、可能存在一定的空间浪费(两倍动态增容所致)
b、增容有一些效率损失(realloc可能会拷贝数据)
c、中间或者头部插入删除,时间复杂度为O(N),因为要挪动数据
以上abc的缺点都可以由链表来解决,互补的数据结构
链表的缺陷:
就是顺序表优点的反面
a、不能随机访问
b、由于预加载原因,缓存利用率并不高
双链表的实现
博主先将头文件给大家看看,具体函数的思路与实现会一一介绍,另外头文件上有与之相关的注释给予浏览。
DoubleList.h
#define _CRT_SECURE_NO_WARNINGS 1
#include void ListPrint(ListNode* phead)
在实现各个函数功能之前,我们需要知道带头双向循环链表的形式到底是什么样的,如下:
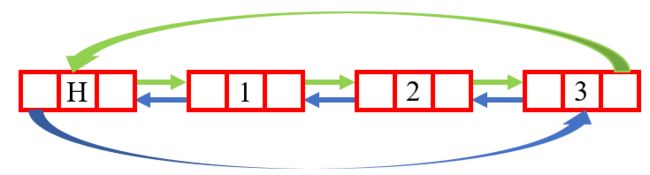
H的意思就是“头”,起到一个哨兵位的效果,里面的数据是随机值,不算做链表的内容,显然仅仅是带头的作用。H的左边是指针prev,右边是next,看英文意思就明白指的是一前一后,从而形成循环,每个结点都保留了前一个结点和后一个结点的地址,方便访问。
但是如果一直循环的话岂不是死循环而无法打印链表了?解决方法也很简单,建立一个新指针cur = phead->next,循环遍历,当cur = phead时停止,如下:
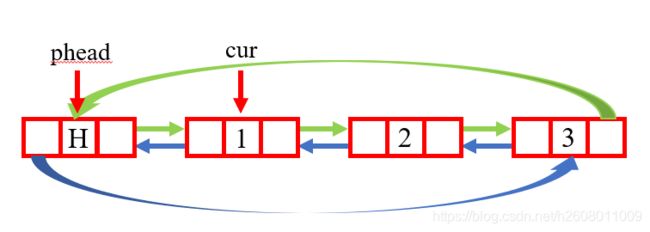
代码:
void ListPrint(ListNode* phead)
{
assert(phead);
ListNode* cur = phead->next;
while (cur != phead)
{
printf("%d ", cur->data);
cur = cur->next;
}
printf("\n");
}
ListNode* BuyListNode(LTDataType x)
建立新结点,代码如下:
ListNode* BuyListNode(LTDataType x)
{
ListNode* newNode = (ListNode*)malloc(sizeof(ListNode));
newNode->data = x;
newNode->next = NULL;
newNode->prev = NULL;
return newNode;
}
是一个很简单的开辟新结点再赋值的写法,不多说。
void InitList(ListNode** pphead)
这里大家有没有发现是一个二级指针,为什么?不着急,我们先看看这个函数的具体内容是什么样的。
void InitList(ListNode** pphead)
{
*pphead = BuyListNode(0);
(*pphead)->next = (*pphead);
(*pphead)->prev = (*pphead);
}
我们再来看看博主主函数的内容。
void main()
{
ListNode* phead = NULL;
InitList(&phead);
}
这样咋一看,是不是清楚很多了二级指针用来存放一级指针的地址,传址调用,这样void InitList(ListNode** pphead)运行完之后phead也同样可以得到改变。为了能让大家更清楚的明白,博主再画一个图供大家理解。
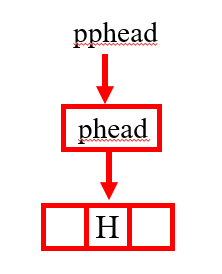
将pphead解引用之后可以得到phead,在函数void InitList(ListNode** pphead)里面如果(*pphead)有任何的变化,主函数的phead都能够与之一起发生改变,如果只是一级指针传过去的话,仅仅只是一份临时拷贝的数据给InitList,但函数运行完之后,会将它释放销毁,毕竟数据是拷贝的,当然不会传给主函数的phead,但是可以用返回的方法实现。
void ListPushBack(ListNode* phead, LTDataType x)
对于双向链表来说,挺方便的,phead-prev就是尾部,这样相当于在头部和尾部插入一个结点,如下:
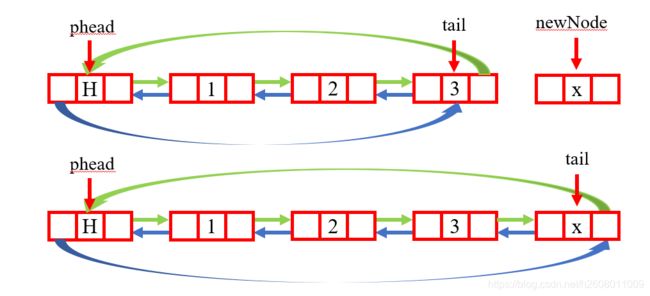
代码的实现如下:
void ListPushBack(ListNode* phead, LTDataType x)
{
//断言,防止空指针的存在
assert(phead);
ListNode* tail = phead->prev;
ListNode* newNode = BuyListNode(x);
newNode->next = phead;
newNode->prev = tail;
tail->next = newNode;
phead->prev = newNode;
}
void ListPopBack(ListNode* phead)
尾删的功能也比较好实现,如下:
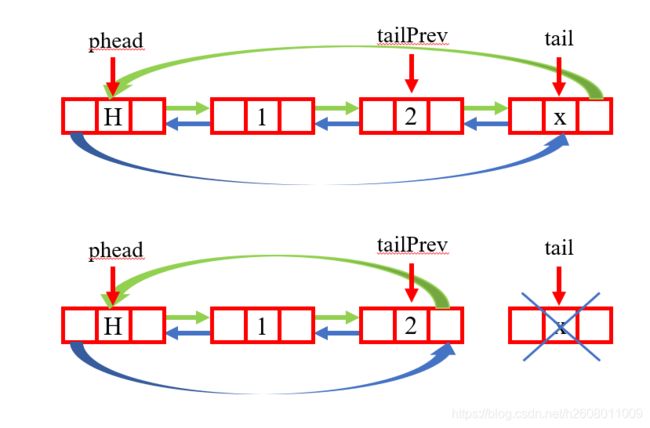
代码如下:
void ListPopBack(ListNode* phead)
{
assert(phead);
//如果是头结点,则报错
assert(phead != phead->next);
ListNode* tail = phead->prev;
ListNode* tailPrev = tail->prev;
tailPrev->next = phead;
phead->prev = tailPrev;
//为什么tail不置空,想想局部变量的生命周期
free(tail);
}
void ListPushFront(ListNode* phead, LTDataType x)
头插的实现也很简单在头结点和头结点的下一个结点的中间插入一个结点,如下:
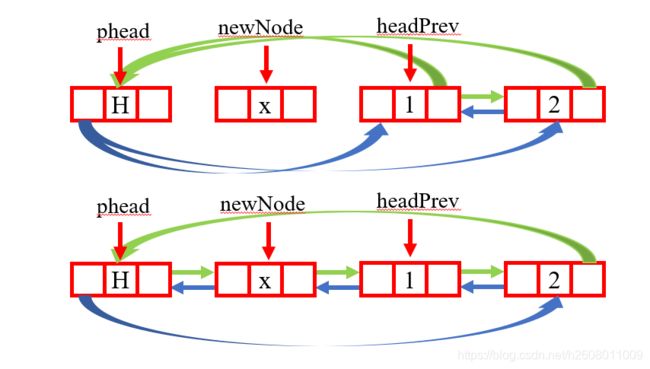
代码如下:
void ListPushFront(ListNode* phead, LTDataType x)
{
assert(phead);
ListNode* headNext = phead->next;
ListNode* newNode = BuyListNode(x);
phead->next = newNode;
newNode->next = headNext;
headNext->prev = newNode;
newNode->prev = phead;
}
void ListPopFront(ListNode* phead)
如下:
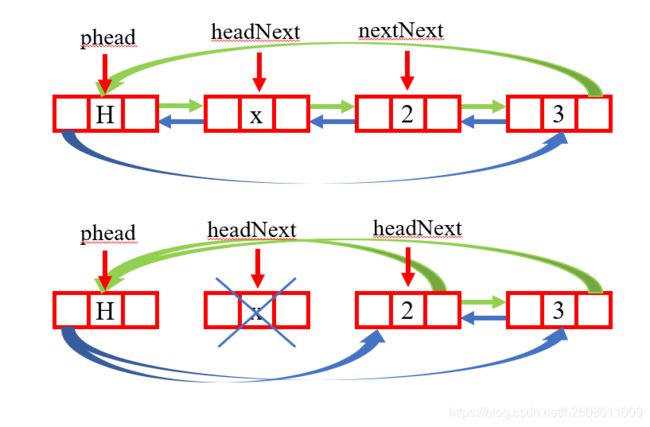
代码:
void ListPopFront(ListNode* phead)
{
assert(phead);
assert(phead != phead->next);
ListNode* headNext = phead->next;
ListNode* nextNext = headNext->next;
phead->next = nextNext;
nextNext->prev = phead;
}
ListNode* ListFind(ListNode* phead, LTDataType x)
访问数据,链表的访问远不如顺序表,最大的原因就是没有下标,需要从头到尾,或者从尾到头依次遍历,时间复杂度为O(N)。本示例是由头到尾依次遍历查询的,最后将查询到的指针地址返回,若无则返回空指针。
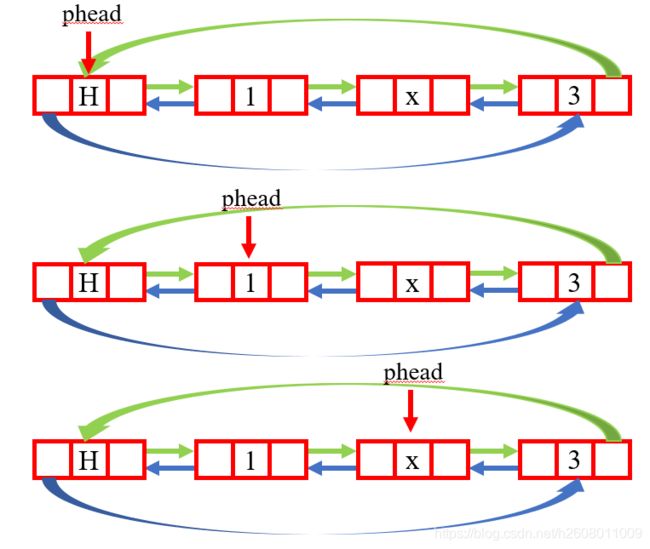
代码:
ListNode* ListFind(ListNode* phead, LTDataType x)
{
assert(phead);
ListNode* cur = phead->next;
while (cur != phead)
{
if (cur->data == x)
return cur;
cur = cur->next;
}
return NULL;
}
void ListInsert(ListNode* pos, LTDataType x)
最开头的.h文件的注释已经告诉大家中间的插入是需要由ListFind函数支撑的,因为我们需要知道要在哪里,哪个位置插入结点(链表是没有下标的)。并且是在指针pos之前插入,如下:
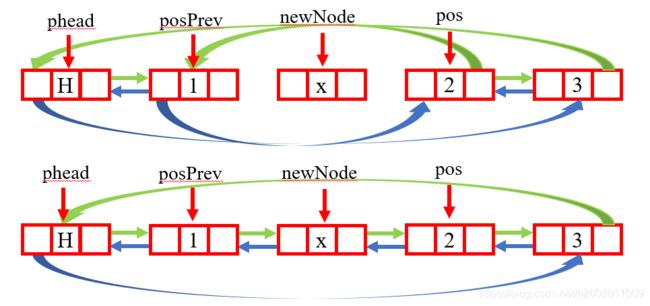
void ListInsert(ListNode* pos, LTDataType x)
{
assert(pos);
ListNode* posPrev = pos->prev;
ListNode* newNode = BuyListNode(x);
posPrev->next = newNode;
newNode->next = pos;
pos->prev = newNode;
newNode->prev = posPrev;
}
其实中间插与尾插头插非常相似,甚至可以合并,这是双向链表强大的地方所在,如下:
void ListPushBack(ListNode* phead, LTDataType x)
{
//在phead与tail之间插入
ListInsert(phead, x);
}
void ListPushFront(ListNode* phead, LTDataType x)
{
//在phead与phead->next之间插入
ListInsert(phead->next, x);
}
哈哈,是不是很神奇的感觉呢?
void ListErase(ListNode* pos)
这个地方就不在画图了,可以参考前面尾删头删的画法。留给大家自己画画,只有多画图才能理解这些抽象的链表,再熟能生巧。
代码如下:
void ListErase(ListNode* pos)
{
assert(pos);
ListNode* posPrev = pos->prev;
ListNode* posNext = pos->next;
posPrev->next = posNext;
posNext->prev = posPrev;
free(pos);
}
同理尾删头删也可以用这个函数所替代。
void ListPopBack(ListNode* phead)
{
//头结点的前一个结点就是尾结点
ListErase(phead->prev);
}
void ListPopFront(ListNode* phead)
{
//头结点的下一个结点就是头删
ListErase(phead->next);
}
Destroy & Clear
这一小部分主要是链表的销毁或者清除,这两唯一不同的区别就是,destroy是把所有结点都删除且没有保留头结点,不能继续使用;而clear保留了头结点,允许继续使用。所以destroy需要将头结点置空,所以需要用二级指针传址调用来改变一级指针从而达到将传递的指针置空的效果。
代码如下:
void ListClear(ListNode* phead)
{
assert(phead);
ListNode* cur = phead->next;
while (cur != phead)
{
ListNode* next = cur->next;
free(cur);
cur = next;
}
}
void ListDestroy(ListNode** phead)
{
assert(*phead);
ListClear(*phead);
free(*phead);
*phead = NULL;
}
结束语
链表的讲述到这里也就告一段落了,还是那句老话,希望大家能够自己独立完成这些代码,实践出真知,光看不写是无用功,边看边敲有一定的好处,但远远不够,因为你没有脱离它,没有把它转换成自己的东西,所以想提升代码能力,一、是要实践,二、在实践的基础上最好能够自己独立完成。博主本身也只是一个小白,但是经过一个多月的学习,深有体会,所以把这个方法告诉大家,我们一起努力~~~