【AI Agent】Agent的原理介绍与应用发展思考
文章目录
-
- Agent是什么?
-
- 最直观的公式
- Agent决策流程
- Agent 大爆发
- 人是如何做事的?
- 如何让LLM替代人去做事?
- 来自斯坦福的虚拟小镇
-
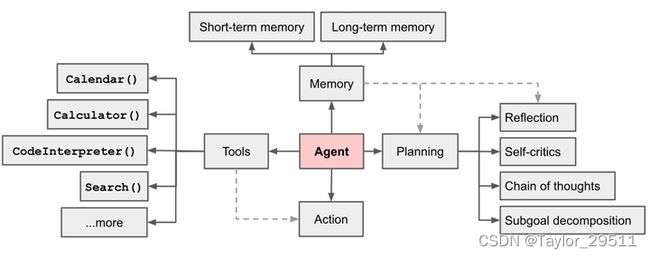
- 架构
- 记忆(Memory)
- 反思(Reflection)
- 计划(Plan)
- 类 LangChain 中的各种概念
- Agent落地的瓶颈
- Agent从专用到通用的实现路径
- 多模态在Agent的发展
- Agent新的共识正在逐渐形成
- 出门问问:希望做通用的Agent
- HF:Transformers Agents 发布
- 参考引用
Agent是什么?
Agent一词起源于拉丁语中的Agere,意思是“to do”。在LLM语境下,Agent可以理解为在某种能自主理解、规划决策、执行复杂任务的智能体。
Agent并非ChatGPT升级版,它不仅告诉你“如何做”,更会帮你去做。如果Copilot是副驾驶,那么Agent就是主驾驶。
自主Agent是由人工智能驱动的程序,当给定目标时,它们能够自己创建任务、完成任务、创建新任务、重新确定任务列表的优先级、完成新的顶级任务,并循环直到达到目标。
最直观的公式
Agent = LLM+Planning+Feedback+Tool use
Agent决策流程
感知(Perception)→ 规划(Planning)→ 行动(Action)
- 感知(Perception)是指Agent从环境中收集信息并从中提取相关知识的能力。
- 规划(Planning)是指Agent为了某一目标而作出的决策过程。
- 行动(Action)是指基于环境和规划做出的动作。
Agent通过感知从环境中收集信息并提取相关知识。然后通过规划为了达到某个目标做出决策。最后,通过行动基于环境和规划做出具体的动作。Policy是Agent做出行动的核心决策,而行动又为进一步感知提供了观察的前提和基础,形成了一个自主的闭环学习过程。
Agent 大爆发
- 3月21日,Camel发布。
- 3月30日,AutoGPT发布。
- 4月3日,BabyAGI发布。
- 4月7日,西部世界小镇发布。
- 5月27日,英伟达AI智能体Voyager接入GPT-4后,直接完胜了AutoGPT。通过自主写代码,它完全独霸了《我的世界》,可以在游戏中进行全场景的终身学习,根本无需人类插手。
- 就在同一时间,商汤、清华等共同提出了通才AI智能体 Ghost in the Minecraft (GITM),它同样能够通过自主学习解决任务,表现优异。这些表现优异的AI智能体,简直让人看到了AGI+智能体的雏形。
Agent 是让 LLM 具备目标实现的能力,并通过自我激励循环来实现这个目标。
它可以是并行的(同时使用多个提示,试图解决同一个目标)和单向的(无需人类参与对话)。
为Agent创建一个目标或主任务后,主要分为以下三个步骤:
- 获取第一个未完成的任务
- 收集中间结果并储存到向量数据库中
- 创建新的任务,并重新设置任务列表的优先级
让我们一起来看一个具体的例子。我们可以从一个任务开始,例如"编写一篇关于ChatGPT以及它能做什么的1500字博客"。
模型接收这个要求,并按照以下步骤执行操作:
sub_tasks = openai.ChatCompletion.create(
model="gpt-4",
messages=[
{"role": "system", "content": "You are an world class assistant designed to help people accomplish tasks"},
{"role": "user", "content": "Create a 1500 word blog post on ChatGPT and what it can do"},
{"role": "user", "content": "Take the users request above and break it down into simple sub-tasks which can be easily done."}
]
)
在这个例子中,我们使用OpenAI API来驱动 Agent。通过 system 字段,你可以在一定程度上定义你的Agent。然后,我们添加 user content Create a 1500 word blog post on ChatGPT and what it can do,以及下一步骤 Take the users request above and break it down into simple sub-tasks which can be easily done.,也就是在此基础上添加任务,将查询分解成子任务。
然后,你可以获取子任务,并在循环中向模型发送更多的调用,执行所有这些子任务,每个子任务都有不同的系统消息(想象成不同的Agent,可能是一个擅长写作的Agent,一个擅长学术研究的Agent等)。
接下来,你可以向模型循环发送更多的调用,执行每个子任务。每个子任务都可以有不同的系统消息,你可以想象这些系统消息代表了不同领域的专家,例如一个擅长写作的专家、一个擅长学术研究的专家等等。这样,你可以让模型在不同的角色下进行思考和响应,从而更好地满足用户的需求。
人是如何做事的?
在工作中,我们通常会用到PDCA思维模型。基于PDCA模型,我们可以将完成一项任务进行拆解,按照作出计划、计划实施、检查实施效果,然后将成功的纳入标准,不成功的留待下一循环去解决。目前,这是人们高效完成一项任务非常成功的经验总结。

如何让LLM替代人去做事?
要让LLM替代人去做事,我们可以基于PDCA模型进行 规划、执行、评估和反思。
- 规划能力(Plan)-> 分解任务:Agent大脑把大的任务拆解为更小的,可管理的子任务,这对有效的、可控的处理好大的复杂的任务效果很好。
- 执行能力(Done)-> 使用工具:Agent能学习到在模型内部知识不够时(比如:在pre-train时不存在,且之后没法改变的模型weights)去调用外部API,比如:获取实时的信息、执行代码的能力、访问专有的信息知识库等等。这是一个典型的平台+工具的场景,我们要有生态意识,即我们构建平台以及一些必要的工具,然后大力吸引其他厂商提供更多的组件工具,形成生态。
- 评估能力(Check)-> 确认执行结果:Agent要能在任务正常执行后判断产出物是否符合目标,在发生异常时要能对异常进行分类(危害等级),对异常进行定位(哪个子任务产生的错误),对异常进行原因分析(什么导致的异常)。这个能力是通用大模型不具备的,需要针对不同场景训练独有的小模型。
- 反思能力(Action)-> 基于评估结果重新规划:Agent要能在产出物符合目标时及时结束任务,是整个流程最核心的部分;同时,进行归因分析总结导致成果的主要因素,另外,Agent要能在发生异常或产出物不符合目标时给出应对措施,并重新进行规划开启再循环过程。
LLM作为一种智能代理,引发了人们对人工智能与人类工作的关系和未来发展的思考。它让我们思考人类如何与智能代理合作,从而实现更高效的工作方式。而这种合作方式也让我们反思人类自身的价值和特长所在。
来自斯坦福的虚拟小镇
- Generative Agents: Interactive Simulacra of Human Behavior, 2023.04, Stanford
- 代码已开源:https://github.com/joonspk-research/generative_agents
虚拟小镇,一个agent就是一个虚拟人物,25个agents之间的故事。
架构
记忆(Memory)
- 短期记忆:在上下文中(prompt)学习。它是短暂且有限的,因为它受到Transformer的上下文窗口长度的限制。
- 长期记忆:代理在查询时可以注意到的外部向量存储,可以通过快速检索访问。
反思(Reflection)
反思是由代理生成的更高级别、更抽象的思考。因为反思也是一种记忆,所以在检索时,它们会与其他观察结果一起被包含在内。反思是周期性生成的;当代理感知到的最新事件的重要性评分之和超过一定阈值时,就会生成反思。
- 让代理确定要反思什么
- 生成的问题作为检索的查询
计划(Plan)
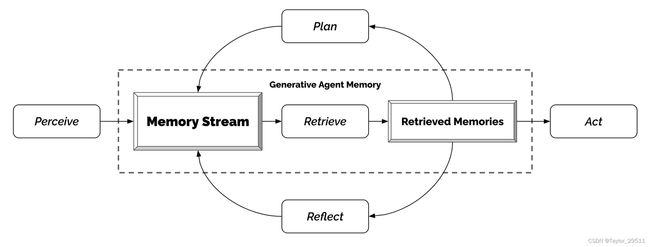
计划是为了做更长时间的规划。像反思一样,计划也被储存在记忆流中(第三种记忆),并被包含在检索过程中。这使得代理能够在决定如何行动时,同时考虑观察、反思和计划。如果需要,代理可能在中途改变他们的计划(即响应,reacting)。
类 LangChain 中的各种概念
- Models:也就是我们熟悉的调用大模型API。
- Prompt Templates:在提示词中引入变量以适应用户输入的提示模版。
- Chains:对模型的链式调用,以上一个输出为下一个输入的一部分。
- Agent:能自主执行链式调用,以及访问外部工具。
- Multi-Agent:多个Agent共享一部分记忆,自主分工相互协作。
Agent落地的瓶颈
Agent本身用到两部分能力,一部分是由LLM作为其“智商”或“大脑”的部分,另一部分是基于LLM,其外部需要有一个控制器,由它去完成各种Prompt,如通过检索增强Memory,从环境获得Feedback,怎样做Reflection等。
Agent既需要大脑,也要外部支撑。
- LLM本身的问题:自身的“智商”不够,可进行LLM升级为GPT-5;Prompt的方式不对,问题要无歧义。
- 外部工具:系统化程度不够,需要调用外部的工具系统,这是一个长期待解决的问题。
现阶段Agent的落地,除了LLM本身足够通用之外,也需要实现一个通用的外部逻辑框架。不只是“智商”问题,还需要如何借助外部工具,从专用抵达通用——而这是更重要的问题。
解决特定场景的特定问题——将LLM作为一个通用大脑,通过Prompt设计为不同的角色,以完成专用的任务,而非普适性的应用。关键问题,即Feedback将成为Agent落地实现的一大制约因素,对于复杂的Tools应用,成功概率会很低。
Agent从专用到通用的实现路径
假设Agent最终将落地于100种不同的环境,在目前连最简单的外部应用都难以实现的前提下,最终能否抽象出一个框架模型来解决所有外部通用性问题?
先将某一场景下的Agent做到极致——足够稳定且鲁棒,再逐步将它变成通用框架,也许这是实现通用Agent的路径之一。
多模态在Agent的发展
- 多模态只能解决Agent感知上的问题,而无法解决认知的问题。
- 多模态是必然趋势,未来的大模型必然是多模态的大模型,未来的Agent也一定是多模态世界中的Agent。
Agent新的共识正在逐渐形成
- Agent需要调用外部工具
- 调用工具的方式就是输出代码
由LLM大脑输出一种可执行的代码,像是一个语义分析器,由它理解每句话的含义,然后将其转换成一种机器指令,再去调用外部的工具来执行或生成答案。尽管现在的 Function Call 形式还有待改进,但是这种调用工具的方式是非常必要的,是解决幻觉问题的最彻底的手段。
出门问问:希望做通用的Agent
在中国的市场环境下,如果做一个与企业深度结合的Agent,最终将成为“外包”,因为它需要私有化部署,集成到企业工作流里。很多公司都会去争抢保险公司、银行、汽车领域的大客户。这将与上一代AI公司的结局非常相似,边际成本很难降低,且没有通用性。出门问问目前的魔音工坊、奇妙文等AIGC产品都属于面向内容创作者的、介于深度和浅度之间的应用,既不完全属于consumer,也不完全属于enterprise,同时还有面向企业用户的CoPilot,其定位也是在企业里找到具体的「场景」,做相对通用的场景应用。

HF:Transformers Agents 发布
通过自然语言控制超过十多万个 HF 模型!

Transformers Agents,并加入到了 Transformers 4.29 之后的版本中。它在 Transformers 的基础上提供了一个自然语言 API,来 “让 Transformers 可以做任何事情”。
这其中有两个概念:一个是 Agent (代理),另一个是 Tools (工具),我们定义了一系列默认的工具,让代理去理解自然语言并使用这些工具。
- 代理:这里指的是大语言模型 (LLM),你可以选择使用 OpenAI 的模型 (需要提供密钥),或者开源的 StarCoder 和 OpenAssistant 的模型,我们会提示让代理去访问一组特定的工具。
- 工具:指的是一个个单一的功能,我们定义了一系列工具,然后使用这些工具的描述来提示代理,并展示它将如何利用工具来执行查询中请求的内容。
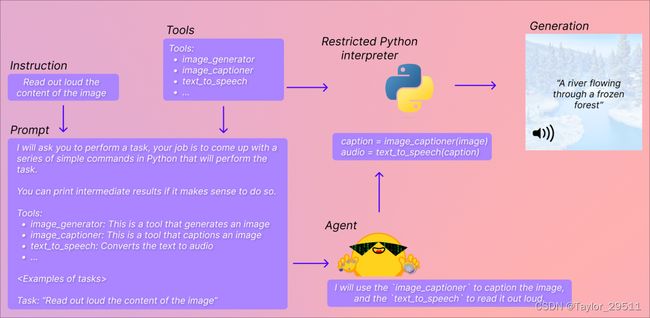
我们在 transformers 中集成的工具 包括:文档问答、文本问答、图片配文、图片问答、图像分割、语音转文本、文本转语音、零样本文本分类、文本摘要、翻译等。不过你也可以扩展这些一些与 transformers 无关的工具,比如从网络读取文本等,查看如何开发自定义工具
未来是Agent的世界,在今天的Agent进程下,依然重复昨天AI的故事,私有化部署将面临挑战。
参考引用
- 大模型下半场,关于Agent的几个疑问
- babyagi
- Agent:OpenAI的下一步,亚马逊云科技站在第5层