Elasticsearch实现词云效果Demo
文章目录
- 前言
- 前期准备
-
- springboot+Elasticsearch依赖
- 思路
-
- 准备数据
- 查询数据
- 处理文本
- 样式处理
- 具体实施
-
- 数据准备
- 创建索引
- 数据存储
- 进行查询
- 踩坑记录
-
- 聚合查询不生效问题
- demo地址
- 总结
前言
最近项目中使用Elasticsearch在做快速查询的功能,然后就想到了之前的一个项目中有一个词云的功能,就想用Elasticsearch实现一下词云的效果,实现思路很简单,目前这个demo已经写完了,透露一下很简陋,如何想要在项目中实际应用还需要改进。
前期准备
springboot+Elasticsearch依赖
版本我用的springboot 2.3.12.RELEASE对应的Elasticsearch是7.6.2
<dependency>
<groupId>org.elasticsearchgroupId>
<artifactId>elasticsearchartifactId>
dependency>
<dependency>
<groupId>org.elasticsearch.clientgroupId>
<artifactId>elasticsearch-rest-high-level-clientartifactId>
dependency>
<dependency>
<groupId>com.janeluogroupId>
<artifactId>ikanalyzerartifactId>
<version>2012_u6version>
dependency>
思路
准备数据
将需要生成词云的文本数据存储到ES中。可以将文本拆分为单个词语,并将其作为文档的字段保存到ES中。
查询数据
使用ES的查询功能检索文档数据。可以根据业务需求编写查询语句,以获取需要的文本数据。
处理文本
将查询到的文本数据进行处理,例如去除停用词、统计词频等。
样式处理
这个不在本文章的范畴内,在上面的步骤就已经简单的实现一部分高频词的内容了,所以下面的这些是属于具体业务了,本文只提供一个思路和demo
-
选择关键词:根据需求,可以根据词频进行排序,选择一定数量的高频词作为关键词。
-
生成词云:使用词云生成工具库(如WordCloud)来生成词云图像。根据关键词的频率和重要性,在画布上布局词语,并设置相应的颜色、字体等样式。
-
展示词云:将生成的词云图像展示在前端页面或保存为图片文件。如果在网页中展示,可以使用HTML和CSS来控制布局和样式。
具体实施
数据准备
就是单纯的准备数据阶段,使用下面这个数据中的数据随机生成一些句子,然后再使用Ik的工具包进行分词,分词以后存储到ES中
static final String[] CHINESE_WORDS = {
"我", "你", "他", "她", "它",
"是", "的", "在", "这", "那",
"很", "真", "爱", "喜欢",
"美丽", "快乐", "拥抱", "友情", "理解",
"幸福", "梦想", "努力", "成功", "明天",
"希望", "勇气", "坚定", "自信", "感恩",
"热爱", "青春", "成长", "智慧", "创新",
"开心", "失落", "放弃", "挑战", "困难",
"奋斗", "拼搏", "汗水", "收获", "感动",
"祝福", "寂寞", "无聊", "闲暇", "旅游",
"信任", "包容", "尊重", "宽容", "耐心"
};
/**
* @description: 使用IK对这些句子进行分词
* @author: gepengjun
* @date: 2023/9/8 10:09
* @param: []
* @return: java.util.List
**/
List<String> fenci() throws IOException {
String text = "我喜欢使用IK分词器进行中文分词。";
List<String> strings = generateRandomChineseSentences(20);
String context="";
for (String string : strings) {
context+=string;
}
List<String> lists=new ArrayList<>();
try (StringReader reader = new StringReader(context)) {
IKSegmenter segmenter = new IKSegmenter(reader, true);
Lexeme lexeme;
while ((lexeme = segmenter.next()) != null) {
System.out.println(lexeme.getLexemeText());
lists.add(lexeme.getLexemeText());
}
} catch (IOException e) {
e.printStackTrace();
}
return lists;
}
/**
* @description: 生成句子的
* @author: gepengjun
* @date: 2023/9/8 10:09
* @param: [numSentences]生成多少条
* @return: java.util.List
**/
private static List<String> generateRandomChineseSentences(int numSentences) {
List<String> sentences = new ArrayList<>();
Random random = new Random();
for (int i = 0; i < numSentences; i++) {
int numWords = random.nextInt(10) + 5; // 每个句子包含的词语数量范围为 5-14
StringBuilder sb = new StringBuilder();
for (int j = 0; j < numWords; j++) {
int index = random.nextInt(CHINESE_WORDS.length);
sb.append(CHINESE_WORDS[index]);
}
String sentence = sb.toString();
sentences.add(sentence);
}
return sentences;
}
创建索引
存储数据前要先创建索引,在ES中索引你可以理解为数据库中的表
@Test
void createIndex(){
// 创建ES连接
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(new HttpHost("116.204.118.226", 9200, "http")));
try {
// 创建索引请求
CreateIndexRequest request = new CreateIndexRequest("wordcloud");//简单理解就是建表
// 设置索引的设置
request.settings(Settings.builder()
.put("index.number_of_shards", 1)
.put("index.number_of_replicas", 1));
// 设置索引的映射
XContentBuilder mapping = XContentFactory.jsonBuilder()
.startObject()
.startObject("properties")
.startObject("context") //建表字段的过程
.field("type", "text")
.startObject("keyword") // 添加一个名为 "keyword" 的子字段
.field("type", "keyword") // 子字段类型为 keyword
.endObject()
.endObject()
.endObject()
.endObject();
request.mapping("_doc",mapping);
// 发送创建索引请求
client.indices().create(request, RequestOptions.DEFAULT);
System.out.println("索引创建成功!");
} catch (IOException e) {
e.printStackTrace();
} finally {
// 关闭ES连接
try {
client.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
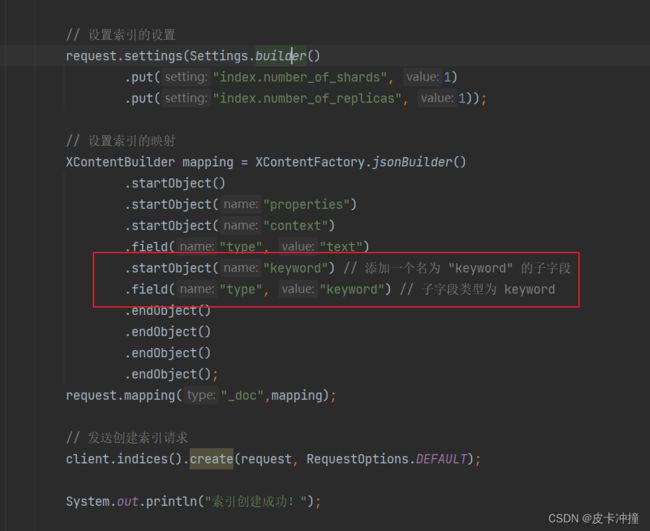
注意这里,后面会用到
数据存储
注意我这些操作都是在单元测试中进行的
@Test
void insertData() throws IOException {
// 创建一个 RestHighLevelClient 对象,用于与 Elasticsearch 进行通信
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(new HttpHost("localhost", 9200, "http")));
// 创建一个 BulkRequest 对象,用于批量操作请求
BulkRequest request = new BulkRequest();
// 调用 fenci() 方法获取分词结果列表
List<String> strings = fenci();
// 遍历分词结果列表,将每个分词作为一个文档添加到 BulkRequest 中
for (String word: strings) {
// 创建一个 IndexRequest 对象,并指定要添加到的索引名称和文档内容
request.add(new IndexRequest("wordcloud").source("context", word));
}
// 执行批量操作请求,并获取响应
BulkResponse response = client.bulk(request, RequestOptions.DEFAULT);
if (response.hasFailures()) {
// 处理错误情况
System.out.println("添加失败---------------------");
} else {
// 处理成功情况
System.out.println("添加成功");
}
}
进行查询
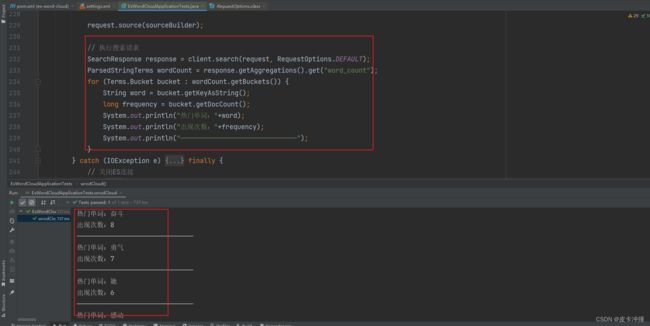
这里使用了es的聚合查询,查询该索引下出现频率最高的前20个单词
@Test
void wrodCloud(){
// 创建ES连接
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(new HttpHost("localhost", 9200, "http")));
try {
// 构建搜索请求
SearchRequest request = new SearchRequest("wordcloud");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.query(QueryBuilders.matchAllQuery());
sourceBuilder.size(0); // 设置为0以仅返回聚合结果
sourceBuilder.timeout(TimeValue.timeValueMinutes(1));
// 添加词频统计的聚合
sourceBuilder.aggregation(
AggregationBuilders.terms("word_count")
.field("context.keyword")
.size(20)); // 返回频率最高的 20 个词语
request.source(sourceBuilder);
// 执行搜索请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
ParsedStringTerms wordCount = response.getAggregations().get("word_count");
for (Terms.Bucket bucket : wordCount.getBuckets()) {
String word = bucket.getKeyAsString();
long frequency = bucket.getDocCount();
System.out.println("热门单词:"+word);
System.out.println("出现次数:"+frequency);
System.out.println("——————————————————————————————");
}
} catch (IOException e) {
e.printStackTrace();
} finally {
// 关闭ES连接
try {
client.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
可以看到查询出来了20个单词,以及出现的频率,这样我们将这些单词以及频率进行一些简单的处理就能获得它们的占比,然后返回到前端展示,至于前端要使用什么用的控件或者框架是另一回事了,因为这些数据是准备好的。
踩坑记录
聚合查询不生效问题
这个问题就是上面创建索引中截图圈出来的部分,就是当我们对文本类型的数据进行聚合查询是需要设置它的子字段有一个keywrod类型的,然后在查询的时候指定这个(字段名.子字段名),这种方式就能正常的使用es的聚合查询了。
在 Elasticsearch 中,当需要对文本类型的字段进行聚合查询时,需要使用额外的 “keyword” 类型的子字段。这样做的目的是为了将文本数据转换为可进行聚合操作的结构。
设置 “keyword” 子字段的步骤如下:
- 创建索引时,在字段的映射中为文本字段添加一个子字段。
- 子字段的类型设置为 “keyword”,表示它是一个非分词的字符串类型。
- 可以为子字段指定任意的名称,不一定非得叫 “keyword”。
通过将字段的类型设置为 “keyword”,Elasticsearch 将保存原始文本数据,并允许对该子字段进行精确的分组统计操作,实现对文本字段的聚合查询。
demo地址
Demo地址
总结
关于使用这个es实现的这个效果,个人认为这只是一种方案,还有其它的,这里是直接使用的分词工具包,es上还可以安装分词插件,所以我的这种不一定是最好的,这是一种简单的方案希望大家不要被我的这种给迷惑了