- WPF中的ComboBox控件几种数据绑定的方式
互联网打工人no1
wpfc#
一、用字典给ItemsSource赋值(此绑定用的地方很多,建议熟练掌握)在XMAL中:在CS文件中privatevoidBindData(){DictionarydicItem=newDictionary();dicItem.add(1,"北京");dicItem.add(2,"上海");dicItem.add(3,"广州");cmb_list.ItemsSource=dicItem;cmb_l
- git常用命令笔记
咩酱-小羊
git笔记
###用习惯了idea总是不记得git的一些常见命令,需要用到的时候总是担心旁边站了人~~~记个笔记@_@,告诉自己看笔记不丢人初始化初始化一个新的Git仓库gitinit配置配置用户信息gitconfig--globaluser.name"YourName"gitconfig--globaluser.email"
[email protected]"基本操作克隆远程仓库gitclone查看
- 将cmd中命令输出保存为txt文本文件
落难Coder
Windowscmdwindow
最近深度学习本地的训练中我们常常要在命令行中运行自己的代码,无可厚非,我们有必要保存我们的炼丹结果,但是复制命令行输出到txt是非常麻烦的,其实Windows下的命令行为我们提供了相应的操作。其基本的调用格式就是:运行指令>输出到的文件名称或者具体保存路径测试下,我打开cmd并且ping一下百度:pingwww.baidu.com>./data.txt看下相同目录下data.txt的输出:如果你再
- PHP环境搭建详细教程
好看资源平台
前端php
PHP是一个流行的服务器端脚本语言,广泛用于Web开发。为了使PHP能够在本地或服务器上运行,我们需要搭建一个合适的PHP环境。本教程将结合最新资料,介绍在不同操作系统上搭建PHP开发环境的多种方法,包括Windows、macOS和Linux系统的安装步骤,以及本地和Docker环境的配置。1.PHP环境搭建概述PHP环境的搭建主要分为以下几类:集成开发环境:例如XAMPP、WAMP、MAMP,这
- 四章-32-点要素的聚合
彩云飘过
本文基于腾讯课堂老胡的课《跟我学Openlayers--基础实例详解》做的学习笔记,使用的openlayers5.3.xapi。源码见1032.html,对应的官网示例https://openlayers.org/en/latest/examples/cluster.htmlhttps://openlayers.org/en/latest/examples/earthquake-clusters.
- 数据仓库——维度表一致性
墨染丶eye
背诵数据仓库
数据仓库基础笔记思维导图已经整理完毕,完整连接为:数据仓库基础知识笔记思维导图维度一致性问题从逻辑层面来看,当一系列星型模型共享一组公共维度时,所涉及的维度称为一致性维度。当维度表存在不一致时,短期的成功难以弥补长期的错误。维度时确保不同过程中信息集成起来实现横向钻取货活动的关键。造成横向钻取失败的原因维度结构的差别,因为维度的差别,分析工作涉及的领域从简单到复杂,但是都是通过复杂的报表来弥补设计
- 展现思维导图魅力,不断挖掘人生宝藏
思维导图讲师Mandy
第13期最强思维导图训练营已经结束一周了,但是我依旧是感觉所有学员还在努力的学习,这些学员中有教师、学生、白领、公务员、宝妈等等,只要你努力,只要你想改变自己,任何行业,任何岗位都可以参与进来,28天足以让你见成效,在这28天中,我们的学员不仅仅是收获了一枚毕业证,最重要的是让自己的思维方式得到升级,今天的你为自己投资,明天的你就会感谢你今天的付出,我们来听一听来自13期最强思维导图训练营优秀学员
- nosql数据库技术与应用知识点
皆过客,揽星河
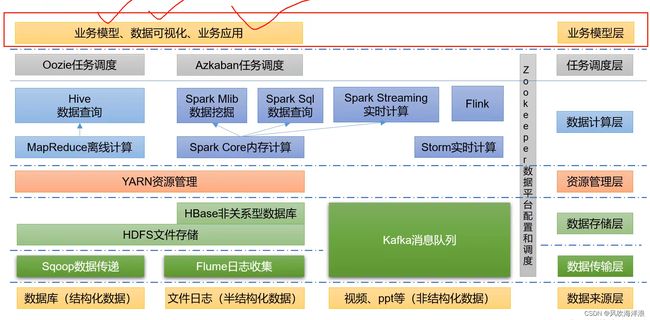
NoSQLnosql数据库大数据数据分析数据结构非关系型数据库
Nosql知识回顾大数据处理流程数据采集(flume、爬虫、传感器)数据存储(本门课程NoSQL所处的阶段)Hdfs、MongoDB、HBase等数据清洗(入仓)Hive等数据处理、分析(Spark、Flink等)数据可视化数据挖掘、机器学习应用(Python、SparkMLlib等)大数据时代存储的挑战(三高)高并发(同一时间很多人访问)高扩展(要求随时根据需求扩展存储)高效率(要求读写速度快)
- 在Ubuntu中编译含有JSON的文件出现报错
芝麻糊76
Linuxkill_buglinuxubuntujson
在ubuntu中进行JSON相关学习的时候,我发现了一些小问题,决定与大家进行分享,减少踩坑时候出现不必要的时间耗费截取部分含有JSON部分的代码进行展示char*str="{\"title\":\"JSONExample\",\"author\":{\"name\":\"JohnDoe\",\"age\":35,\"isVerified\":true},\"tags\":[\"json\",\"
- Linux MariaDB使用OpenSSL安装SSL证书
Meta39
MySQLOracleMariaDBLinuxWindowsssllinuxmariadb
进入到证书存放目录,批量删除.pem证书警告:确保已经进入到证书存放目录find.-typef-iname\*.pem-delete查看是否安装OpenSSLopensslversion没有则安装yuminstallopensslopenssl-devel开启SSL编辑/etc/my.cnf文件(没有的话就创建,但是要注意,在/etc/my.cnf.d/server.cnf配置了datadir的,
- 网络编程基础
记得开心一点啊
网络
目录♫什么是网络编程♫Socket套接字♪什么是Socket套接字♪数据报套接字♪流套接字♫数据报套接字通信模型♪数据报套接字通讯模型♪DatagramSocket♪DatagramPacket♪实现UDP的服务端代码♪实现UDP的客户端代码♫流套接字通信模型♪流套接字通讯模型♪ServerSocket♪Socket♪实现TCP的服务端代码♪实现TCP的客户端代码♫什么是网络编程网络编程,指网络上
- K近邻算法_分类鸢尾花数据集
_feivirus_
算法机器学习和数学分类机器学习K近邻
importnumpyasnpimportpandasaspdfromsklearn.datasetsimportload_irisfromsklearn.model_selectionimporttrain_test_splitfromsklearn.metricsimportaccuracy_score1.数据预处理iris=load_iris()df=pd.DataFrame(data=ir
- 4.C_数据结构_队列
荣世蓥
数据结构数据结构
概述什么是队列:队列是限定在两端进行插入操作和删除操作的线性表。具有先入先出(FIFO)的特点相关名词:队尾:写入数据的一段队头:读取数据的一段空队:队列中没有数据,队头指针=队尾指针满队:队列中存满了数据,队尾指针+1=队头指针循环队列1、基本内容循环队列是以数组形式构成的队列数据结构。循环队列的结构体如下:typedefintdata_t;//队列数据类型#defineN64//队列容量typ
- vue项目element-ui的table表格单元格合并
酋长哈哈
vue.jselementuijavascript前端
一、合并效果二全部代码exportdefault{name:'CellMerge',data(){return{tableData:[{id:'1',name:'王小虎',amount1:'165',amount2:'3.2',amount3:10},{id:'1',name:'王小虎',amount1:'162',amount2:'4.43',amount3:12},{id:'1',name:'
- python tif转png
Python与遥感
python开发语言
importosfromosgeoimportgdalimportnumpyasnpfromPILimportImage#提取432三波段fromspectralimport*#输入文件夹路径defget_img(dataset_img):width=dataset_img.RasterXSize#获取行列数height=dataset_img.RasterYSizebands=dataset_i
- MongoDB知识概括
GeorgeLin98
持久层mongodb
MongoDB知识概括MongoDB相关概念单机部署基本常用命令索引-IndexSpirngDataMongoDB集成副本集分片集群安全认证MongoDB相关概念业务应用场景:传统的关系型数据库(如MySQL),在数据操作的“三高”需求以及应对Web2.0的网站需求面前,显得力不从心。解释:“三高”需求:①Highperformance-对数据库高并发读写的需求。②HugeStorage-对海量数
- Vue中table合并单元格用法
weixin_30613343
javascriptViewUI
地名结果人名性别{{item.name}}已完成未完成{{item.groups[0].name}}{{item.groups[0].sex}}{{item.groups[son].name}}{{item.groups[son].sex}}exportdefault{data(){return{list:[{name:'地名1',result:'1',groups:[{name:'张三',sex
- uniapp map组件自定义markers标记点
以对_
uni-app学习记录uni-appjavascript前端
需求是根据后端返回数据在地图上显示标记点,并且根据数据状态控制标记点颜色,标记点背景通过两张图片实现控制{{item.options.labelName}}exportdefault{data(){return{storeIndex:0,locaInfo:{longitude:120.445172,latitude:36.111387},markers:[//标点列表{id:1,//标记点idin
- 阅读《别说你懂思维导图》21~23章day27
Ling宝尔
合理期待——思维导图的应用效果很多人问我,思维导图真的有用么?我常常回答,如果你觉得是它“没用”,一定是因为你没“用”,有“用”才“有用”。实际上,学习思维导图和学习木工、驾驶等技能型学习一样,都要经历从了解到应用、从应用到受益的过程。在使用前,我们很多人的思维处于“无意识的低效”状态,经过一段时间的学习,虽然掌握了思维导图的基本使用方法,但可能并没有太好的效果,这个阶段可称为“有意识的低效”状态
- 放松的一天
4da9b7687fa0
20190325总结起床07:20图片发自App睡觉:23:00天气:晴今日任务清单学习·信息·阅读•水滴阅读Day40Alice’sAdventuresinWonderlandChapter6.2图片发自App•BBC跟读训练营Day24图片发自App图片发自App图片发自App•潘多拉口语训练营Day6Wow.Whatabigboy!•文化知识学习今日无•阅读时间地狱健康·饮食·锻炼•饮食目标
- 博客网站制作教程
2401_85194651
javamaven
首先就是技术框架:后端:Java+SpringBoot数据库:MySQL前端:Vue.js数据库连接:JPA(JavaPersistenceAPI)1.项目结构blog-app/├──backend/│├──src/main/java/com/example/blogapp/││├──BlogApplication.java││├──config/│││└──DatabaseConfig.java
- vue + Element UI table动态合并单元格
我家媳妇儿萌哒哒
elementUIvue.js前端javascript
一、功能需求1、根据名称相同的合并工作阶段和主要任务合并这两列,但主要任务内容一样,但要考虑主要任务一样,但工作阶段不一样的情况。(枞向合并)2、落实情况里的定量内容和定性内容值一样则合并。(横向合并)二、功能实现exportdefault{data(){return{tableData:[{name:'a',address:'1',age:'1',six:'2'},{name:'a',addre
- Python实现TIFF 文件转换为 PNG 和 JPG 格式
sand&wich
python开发语言
在日常的图像处理工作中,可能会遇到需要将TIFF格式的图像转换为其他格式的情况,例如PNG和JPG。下面,本文将介绍如何使用Python和GDAL库实现这一功能。准备工作在开始之前,请确保已经安装了必要的库:GDAL(GeospatialDataAbstractionLibrary)可以使用以下命令安装GDAL:pipinstallgdal代码实现以下是一个将TIFF文件转换为PNG文件的示例代码
- 浅谈MapReduce
Android路上的人
Hadoop分布式计算mapreduce分布式框架hadoop
从今天开始,本人将会开始对另一项技术的学习,就是当下炙手可热的Hadoop分布式就算技术。目前国内外的诸多公司因为业务发展的需要,都纷纷用了此平台。国内的比如BAT啦,国外的在这方面走的更加的前面,就不一一列举了。但是Hadoop作为Apache的一个开源项目,在下面有非常多的子项目,比如HDFS,HBase,Hive,Pig,等等,要先彻底学习整个Hadoop,仅仅凭借一个的力量,是远远不够的。
- LeetCode 53. Maximum Subarray
枯萎的海风
算法与OJC/C++leetcode
1.题目描述Findthecontiguoussubarraywithinanarray(containingatleastonenumber)whichhasthelargestsum.Forexample,giventhearray[−2,1,−3,4,−1,2,1,−5,4],thecontiguoussubarray[4,−1,2,1]hasthelargestsum=6.clicktos
- 使用datepicker和uploadify的冲突解决(IE双击才能打开附件上传对话框)
zhanglb12
在开发的过程当中,IE的兼容无疑是我们的一块绊脚石,在我们使用的如期的datepicker插件和使用上传附件的uploadify插件的时候,两者就产生冲突,只要点击过时间的插件,uploadify上传框要双才能打开ie浏览器提示错误Missinginstancedataforthisdatepicker解决方案//if(.browser.msie&&'9.0'===.browser.version
- golang获取用户输入的几种方式
余生逆风飞翔
golang开发语言后端
一、定义结构体typeUserInfostruct{Namestring`json:"name"`Ageint`json:"age"`Addstring`json:"add"`}typeReturnDatastruct{Messagestring`json:"message"`Statusstring`json:"status"`DataUserInfo`json:"data"`}二、get请求的
- 【LeetCode】53. Maximum Subarray
墨染百城
LeetCodeleetcode
问题描述问题链接:https://leetcode.com/problems/maximum-subarray/#/descriptionFindthecontiguoussubarraywithinanarray(containingatleastonenumber)whichhasthelargestsum.Forexample,giventhearray[-2,1,-3,4,-1,2,1,-
- LeetCode 673. Number of Longest Increasing Subsequence (Java版; Meidum)
littlehaes
字符串动态规划算法leetcode数据结构
welcometomyblogLeetCode673.NumberofLongestIncreasingSubsequence(Java版;Meidum)题目描述Givenanunsortedarrayofintegers,findthenumberoflongestincreasingsubsequence.Example1:Input:[1,3,5,4,7]Output:2Explanatio
- 【Java】已解决:org.springframework.jdbc.datasource.lookup.DataSourceLookupFailureException
屿小夏
java开发语言
文章目录一、分析问题背景问题背景描述出现问题的场景二、可能出错的原因三、错误代码示例四、正确代码示例五、注意事项已解决:org.springframework.jdbc.datasource.lookup.DataSourceLookupFailureException在使用Spring框架进行开发时,数据源的配置和使用是非常关键的一环。然而,有时候我们可能会遇到org.springframewo
- 关于旗正规则引擎规则中的上传和下载问题
何必如此
文件下载压缩jsp文件上传
文件的上传下载都是数据流的输入输出,大致流程都是一样的。
一、文件打包下载
1.文件写入压缩包
string mainPath="D:\upload\"; 下载路径
string tmpfileName=jar.zip; &n
- 【Spark九十九】Spark Streaming的batch interval时间内的数据流转源码分析
bit1129
Stream
以如下代码为例(SocketInputDStream):
Spark Streaming从Socket读取数据的代码是在SocketReceiver的receive方法中,撇开异常情况不谈(Receiver有重连机制,restart方法,默认情况下在Receiver挂了之后,间隔两秒钟重新建立Socket连接),读取到的数据通过调用store(textRead)方法进行存储。数据
- spark master web ui 端口8080被占用解决方法
daizj
8080端口占用sparkmaster web ui
spark master web ui 默认端口为8080,当系统有其它程序也在使用该接口时,启动master时也不会报错,spark自己会改用其它端口,自动端口号加1,但为了可以控制到指定的端口,我们可以自行设置,修改方法:
1、cd SPARK_HOME/sbin
2、vi start-master.sh
3、定位到下面部分
- oracle_执行计划_谓词信息和数据获取
周凡杨
oracle执行计划
oracle_执行计划_谓词信息和数据获取(上)
一:简要说明
在查看执行计划的信息中,经常会看到两个谓词filter和access,它们的区别是什么,理解了这两个词对我们解读Oracle的执行计划信息会有所帮助。
简单说,执行计划如果显示是access,就表示这个谓词条件的值将会影响数据的访问路径(表还是索引),而filter表示谓词条件的值并不会影响数据访问路径,只起到
- spring中datasource配置
g21121
dataSource
datasource配置有很多种,我介绍的一种是采用c3p0的,它的百科地址是:
http://baike.baidu.com/view/920062.htm
<!-- spring加载资源文件 -->
<bean name="propertiesConfig"
class="org.springframework.b
- web报表工具FineReport使用中遇到的常见报错及解决办法(三)
老A不折腾
finereportFAQ报表软件
这里写点抛砖引玉,希望大家能把自己整理的问题及解决方法晾出来,Mark一下,利人利己。
出现问题先搜一下文档上有没有,再看看度娘有没有,再看看论坛有没有。有报错要看日志。下面简单罗列下常见的问题,大多文档上都有提到的。
1、repeated column width is largerthan paper width:
这个看这段话应该是很好理解的。比如做的模板页面宽度只能放
- mysql 用户管理
墙头上一根草
linuxmysqluser
1.新建用户 //登录MYSQL@>mysql -u root -p@>密码//创建用户mysql> insert into mysql.user(Host,User,Password) values(‘localhost’,'jeecn’,password(‘jeecn’));//刷新系统权限表mysql>flush privileges;这样就创建了一个名为:
- 关于使用Spring导致c3p0数据库死锁问题
aijuans
springSpring 入门Spring 实例Spring3Spring 教程
这个问题我实在是为整个 springsource 的员工蒙羞
如果大家使用 spring 控制事务,使用 Open Session In View 模式,
com.mchange.v2.resourcepool.TimeoutException: A client timed out while waiting to acquire a resource from com.mchange.
- 百度词库联想
annan211
百度
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>RunJS</title&g
- int数据与byte之间的相互转换实现代码
百合不是茶
位移int转bytebyte转int基本数据类型的实现
在BMP文件和文件压缩时需要用到的int与byte转换,现将理解的贴出来;
主要是要理解;位移等概念 http://baihe747.iteye.com/blog/2078029
int转byte;
byte转int;
/**
* 字节转成int,int转成字节
* @author Administrator
*
- 简单模拟实现数据库连接池
bijian1013
javathreadjava多线程简单模拟实现数据库连接池
简单模拟实现数据库连接池
实例1:
package com.bijian.thread;
public class DB {
//private static final int MAX_COUNT = 10;
private static final DB instance = new DB();
private int count = 0;
private i
- 一种基于Weblogic容器的鉴权设计
bijian1013
javaweblogic
服务器对请求的鉴权可以在请求头中加Authorization之类的key,将用户名、密码保存到此key对应的value中,当然对于用户名、密码这种高机密的信息,应该对其进行加砂加密等,最简单的方法如下:
String vuser_id = "weblogic";
String vuse
- 【RPC框架Hessian二】Hessian 对象序列化和反序列化
bit1129
hessian
任何一个对象从一个JVM传输到另一个JVM,都要经过序列化为二进制数据(或者字符串等其他格式,比如JSON),然后在反序列化为Java对象,这最后都是通过二进制的数据在不同的JVM之间传输(一般是通过Socket和二进制的数据传输),本文定义一个比较符合工作中。
1. 定义三个POJO
Person类
package com.tom.hes
- 【Hadoop十四】Hadoop提供的脚本的功能
bit1129
hadoop
1. hadoop-daemon.sh
1.1 启动HDFS
./hadoop-daemon.sh start namenode
./hadoop-daemon.sh start datanode
通过这种逐步启动的方式,比start-all.sh方式少了一个SecondaryNameNode进程,这不影响Hadoop的使用,其实在 Hadoop2.0中,SecondaryNa
- 中国互联网走在“灰度”上
ronin47
管理 灰度
中国互联网走在“灰度”上(转)
文/孕峰
第一次听说灰度这个词,是任正非说新型管理者所需要的素质。第二次听说是来自马化腾。似乎其他人包括马云也用不同的语言说过类似的意思。
灰度这个词所包含的意义和视野是广远的。要理解这个词,可能同样要用“灰度”的心态。灰度的反面,是规规矩矩,清清楚楚,泾渭分明,严谨条理,是决不妥协,不转弯,认死理。黑白分明不是灰度,像彩虹那样
- java-51-输入一个矩阵,按照从外向里以顺时针的顺序依次打印出每一个数字。
bylijinnan
java
public class PrintMatrixClockwisely {
/**
* Q51.输入一个矩阵,按照从外向里以顺时针的顺序依次打印出每一个数字。
例如:如果输入如下矩阵:
1 2 3 4
5 6 7 8
9
- mongoDB 用户管理
开窍的石头
mongoDB用户管理
1:添加用户
第一次设置用户需要进入admin数据库下设置超级用户(use admin)
db.addUsr({user:'useName',pwd:'111111',roles:[readWrite,dbAdmin]});
第一个参数用户的名字
第二个参数
- [游戏与生活]玩暗黑破坏神3的一些问题
comsci
生活
暗黑破坏神3是有史以来最让人激动的游戏。。。。但是有几个问题需要我们注意
玩这个游戏的时间,每天不要超过一个小时,且每次玩游戏最好在白天
结束游戏之后,最好在太阳下面来晒一下身上的暗黑气息,让自己恢复人的生气
&nb
- java 二维数组如何存入数据库
cuiyadll
java
using System;
using System.Linq;
using System.Text;
using System.Windows.Forms;
using System.Xml;
using System.Xml.Serialization;
using System.IO;
namespace WindowsFormsApplication1
{
- 本地事务和全局事务Local Transaction and Global Transaction(JTA)
darrenzhu
javaspringlocalglobaltransaction
Configuring Spring and JTA without full Java EE
http://spring.io/blog/2011/08/15/configuring-spring-and-jta-without-full-java-ee/
Spring doc -Transaction Management
http://docs.spring.io/spri
- Linux命令之alias - 设置命令的别名,让 Linux 命令更简练
dcj3sjt126com
linuxalias
用途说明
设置命令的别名。在linux系统中如果命令太长又不符合用户的习惯,那么我们可以为它指定一个别名。虽然可以为命令建立“链接”解决长文件名的问 题,但对于带命令行参数的命令,链接就无能为力了。而指定别名则可以解决此类所有问题【1】。常用别名来简化ssh登录【见示例三】,使长命令变短,使常 用的长命令行变短,强制执行命令时询问等。
常用参数
格式:alias
格式:ali
- yii2 restful web服务[格式响应]
dcj3sjt126com
PHPyii2
响应格式
当处理一个 RESTful API 请求时, 一个应用程序通常需要如下步骤 来处理响应格式:
确定可能影响响应格式的各种因素, 例如媒介类型, 语言, 版本, 等等。 这个过程也被称为 content negotiation。
资源对象转换为数组, 如在 Resources 部分中所描述的。 通过 [[yii\rest\Serializer]]
- MongoDB索引调优(2)——[十]
eksliang
mongodbMongoDB索引优化
转载请出自出处:http://eksliang.iteye.com/blog/2178555 一、概述
上一篇文档中也说明了,MongoDB的索引几乎与关系型数据库的索引一模一样,优化关系型数据库的技巧通用适合MongoDB,所有这里只讲MongoDB需要注意的地方 二、索引内嵌文档
可以在嵌套文档的键上建立索引,方式与正常
- 当滑动到顶部和底部时,实现Item的分离效果的ListView
gundumw100
android
拉动ListView,Item之间的间距会变大,释放后恢复原样;
package cn.tangdada.tangbang.widget;
import android.annotation.TargetApi;
import android.content.Context;
import android.content.res.TypedArray;
import andr
- 程序员用HTML5制作的爱心树表白动画
ini
JavaScriptjqueryWebhtml5css
体验效果:http://keleyi.com/keleyi/phtml/html5/31.htmHTML代码如下:
<!DOCTYPE html>
<html xmlns="http://www.w3.org/1999/xhtml"><head><meta charset="UTF-8" >
<ti
- 预装windows 8 系统GPT模式的ThinkPad T440改装64位 windows 7旗舰版
kakajw
ThinkPad预装改装windows 7windows 8
该教程具有普遍参考性,特别适用于联想的机器,其他品牌机器的处理过程也大同小异。
该教程是个人多次尝试和总结的结果,实用性强,推荐给需要的人!
缘由
小弟最近入手笔记本ThinkPad T440,但是特别不能习惯笔记本出厂预装的Windows 8系统,而且厂商自作聪明地预装了一堆没用的应用软件,消耗不少的系统资源(本本的内存为4G,系统启动完成时,物理内存占用比
- Nginx学习笔记
mcj8089
nginx
一、安装nginx 1、在nginx官方网站下载一个包,下载地址是:
http://nginx.org/download/nginx-1.4.2.tar.gz
2、WinSCP(ftp上传工
- mongodb 聚合查询每天论坛链接点击次数
qiaolevip
每天进步一点点学习永无止境mongodb纵观千象
/* 18 */
{
"_id" : ObjectId("5596414cbe4d73a327e50274"),
"msgType" : "text",
"sendTime" : ISODate("2015-07-03T08:01:16.000Z"
- java术语(PO/POJO/VO/BO/DAO/DTO)
Luob.
DAOPOJODTOpoVO BO
PO(persistant object) 持久对象
在o/r 映射的时候出现的概念,如果没有o/r映射,就没有这个概念存在了.通常对应数据模型(数据库),本身还有部分业务逻辑的处理.可以看成是与数据库中的表相映射的java对象.最简单的PO就是对应数据库中某个表中的一条记录,多个记录可以用PO的集合.PO中应该不包含任何对数据库的操作.
VO(value object) 值对象
通
- 算法复杂度
Wuaner
Algorithm
Time Complexity & Big-O:
http://stackoverflow.com/questions/487258/plain-english-explanation-of-big-o
http://bigocheatsheet.com/
http://www.sitepoint.com/time-complexity-algorithms/