HINet | 性能炸裂,旷视科技提出适用于low-level问题的Half Instance Normalization
编辑:Happy
首发: AIWalker
大家好,我是Happy。
一直以来,甚少有normalization技术在low-level得到广泛应用并取得优异性能,就算得到应用其性能也会受限或者造成异常的视觉效果。
不过,现在有了!旷视科技的研究员提出了一种Half Instance Normalization技术用于图像复原并在不同的low-level领域取得了SOTA性能,先来看一下其刷新的性能(注:以下数据来自paperswithcode.com,此前最佳性能由MPRNet达成):
- Image Denoising on SIDD: 39.99 vs 39.71
- Image Deblurring on GoPr0: 32.71 vs 32.66
- Image Deraing on Rain100H: 30.65 vs 30.41
- Image Deraing on Rain100L: 37.28 vs 36.40
- Image Deraing on Test100: 30.29 vs 30.27
- Image Deraing on Test1200: 33.05 vs 32.91
- Image Deraing on Test2800: 33.91vs 33.64

paper: https://arxiv.org/abs/2105.06086
code: https://github.com/megvii-model/HINet
本文是旷视科技&复旦大学&北大在图像复原方面的的最新进展,所提方案取得了NTIRE2021图像去模糊Track2赛道冠军。本文针对low-level领域normalization问题进行了思考,分析了BN、IN在low-level应用中的失败与成功之处,进而提出了一种新的Half Instance Normalization模块,受益于HIN,所提HINet在多个图像复原任务上取得了新突破:在大幅降低计算量的同时提升模型性能。比如,相比MPRNet,在SIDD降噪方面,HINet取得了0.28dB指标提升且计算量仅需30%,推理速度块2.9倍;在图像去雨任务上,HINet取得了0.3dB指标提升且推理速度快1.4倍。
Abstract
本文对Instance Normalization在low-level视觉任务上的作用进行了探索。具体来收,我们提出了一个新的模块:Half Instance Normalization(HIN)用于提升图像复原网络的性能。基于HIN模块,我们设计了一个简单且强大的多阶段网络HINet,它包含两个子网络。
受益于HIN,HINet在不同的图像复原任务上均取得了超越SOTA方案的性能,比如:
- 图像降噪:在SIDD数据上,所提方案(HINet0.2x与HINet)取得了0.11dB与0.28dB的指标提升,且仅需7.5%和30%的计算量,推理速度快6.8倍和2.9倍;
- 图像去模糊:所提方案仅需22.5%的计算量且推挤速度快3.3倍即可在REDS与GoPro数据上取得相当的性能;
- 图像去雨:在多个数据集上,所提方案取得了平均0.3dB的PSNR指标提升且推理速度快1.4倍;
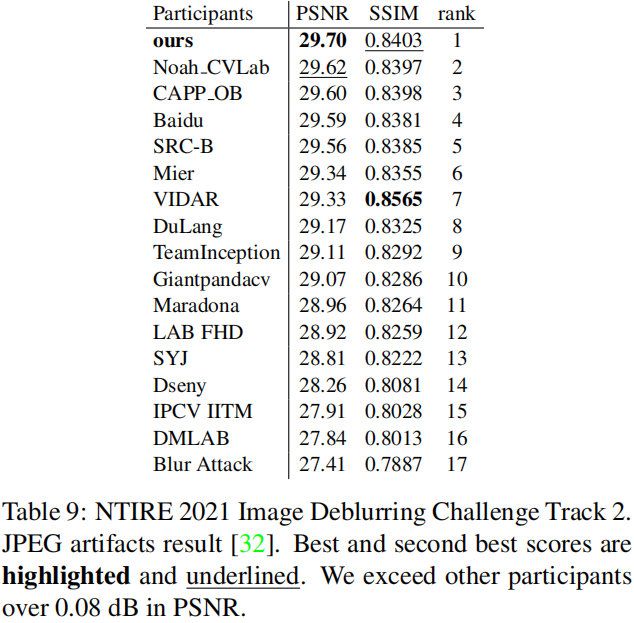
- NTIRE2021:所提方案取得了图像去模糊Track2的冠军,PSNR指标达29.70;
本文贡献包含以下几点:
- 精心的将Instance Normalization(IN)集成到基础模块并提出了HIN模块。该文是首个
直接采用规范化技术在图像复原任务中达到SOTA性能的方案; - 基于HIN模块,设计一种多阶段架构HINet用于图像复原,以更少的计算量、更少的推理耗时达到了SOTA性能;
- 多个图像复原任务上的实验验证了所提方案的有效性;受益于HIN模块,HINet凭借29.70dB性能取得了NTIRE2021图像去模糊Track2赛道的冠军。
Method
HINet
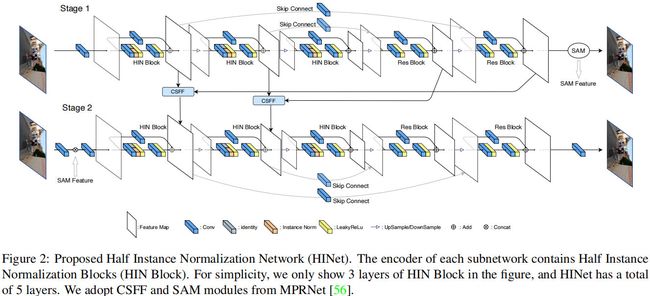
上图为HINet网络架构示意图,它包含两个子网络,均为UNet架构。在每个阶段UNet,我们采用一个 3 × 3 3\times 3 3×3卷积提取初始特征,然后所提取特征送入到后续编解码架构中(四个下采样+四个上采样)。我们采用 4 × 4 4\times 4 4×4卷积进行下采样,采用 2 × 2 2\times 2 2×2反卷积进行上采样。
在每个编码部分,我们设计了HIN模块提取每个尺度的特征,但下采样时通道数倍增。在解码部分,我们采用ResBlock提取高级特征并与编码部分特征融合以补偿重复采样导致的信息损失。最后,我们采用 3 × 3 3\times 3 3×3卷积得到最终的残差输出。
我们采用CSFF(Cross-Stage Feature Fusion)与SAM(Supervised Attention Module)对两个子网络进行连接。相关信息如下:
- CSFF:我们采用 3 × 3 3\times 3 3×3卷积对前一阶段的特征进行变换并送给下一阶段进行集成,这有助于丰富下一阶段的多尺度特征;
- SAM:我们采用 3 × 3 3\times 3 3×3卷积替换原始模块中的 1 × 1 1\times 1 1×1卷积并对每个卷积添加bias参数。SAM有助于将当前阶段的有用特征传递给下一阶段,而无价值信息可以通过注意力掩码进行抑制。
除了网络架构外,我们采用PSNR作为损失函数,假设 X i ∈ R N × C × H × W X_i \in R^{N \times C \times H \times W} Xi∈RN×C×H×W表示自网络 i i i的输入, R i ∈ R N × C × H × W R_i \in R^{N \times C \times H \times W} Ri∈RN×C×H×W表示子网络 i i i的最终预测, Y ∈ R N × C × H × W Y \in R^{N \times C \times H \times W} Y∈RN×C×H×W表示每个阶段的GT。我们通过如下损失对HINet进行端到端优化:
L o s s = − ∑ i = 1 2 P S N R ( ( R i + X i ) , Y ) Loss = - \sum_{i=1}^2 PSNR((R_i + X_i), Y) Loss=−i=1∑2PSNR((Ri+Xi),Y)
Half Instance Normalization Block
由于每个批次内不同图像块的差异性,以及训练、测试的不同配置,BN在low-level任务中并不常见。相反,IN可以在训练与推理阶段保持相同的规范化处理;此外,IN可以对特征的均值与方差进行重校正且不受batch维度的影响,可以保持更多的尺度信息。我们采用IN构建HIN,通过引入HIN模块,HINet的建模能力得到了改善,此外,IN导致的额外参数与计算量可以忽略。

以上图为例,首先,HIN以 F i n ∈ R C i n × H × W F_{in} \in R^{C_{in} \times H \times W} Fin∈RCin×H×W作为输入,采用 3 × 3 3\times 3 3×3卷积生成中间特征 F m i d ∈ R C o u t × H × W F_{mid} \in R^{C_{out}\times H \times W} Fmid∈RCout×H×W;然后,中间特征倍分为两部分 F m i d 1 , F m i d 2 F_{mid_1}, F_{mid_2} Fmid1,Fmid2,前者采用IN进行规范化,后者不做任何规范化,将所得两者沿着通道维度进行拼接。HIN模块在一半通道上进行IN处理,通过另一半保持上下文信息,这种操作对于浅层特征更为友好。完成拼接后,我们采用另一个 3 × 3 3\times 3 3×3卷积提取残差特征 R o u t ∈ R C o u t × H × W R_{out} \in R^{C_{out}\times H \times W} Rout∈RCout×H×W;最后,HIN通过将 R o u t R_{out} Rout与短链接特征(通过 1 × 1 1\times 1 1×1卷积得到)相加得到输出 F o u t F_{out} Fout。
Experiments
Dataset 我们在不同的任务上进行了方案有效性验证,它们的数据集分别如下:
- 图像降噪:SIDD
- 图像去模糊:GoPro
- 图像去雨:Rain13K;
- 去模糊+压缩伪影:REDS。
Main Results
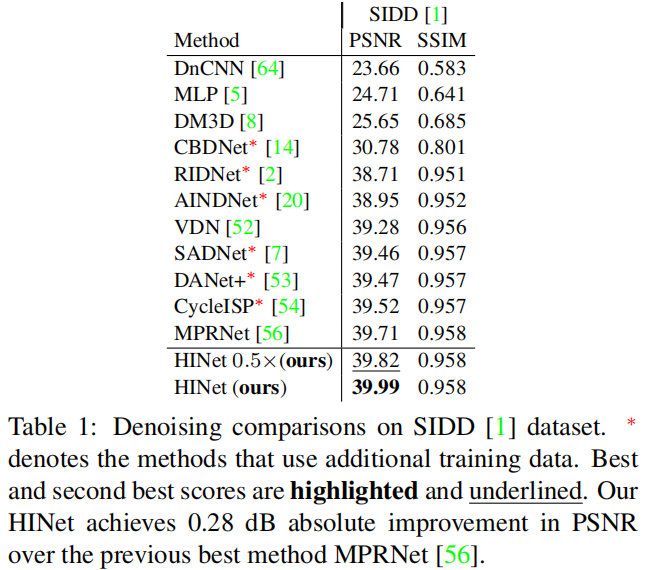
上表给出了SIDD数据上图像降噪性能对比,可以看到:
- 仅需MPRNet7.5%的计算量,所提方案HINet0.5x即可取得0.11dB指标提升;
- 仅需MPRNet30%的计算量,所提方案HINet即可取得0.28dB指标提升。

上表为GoPro数据上的图像去模糊性能对比,可以看到:仅需MPRNet的22.5%计算量,所提方案即可取得相当的性能。

上表为图像去雨任务上的性能对比,可以看到:相比MPRNet,HINet取得了0.3dB指标提升。
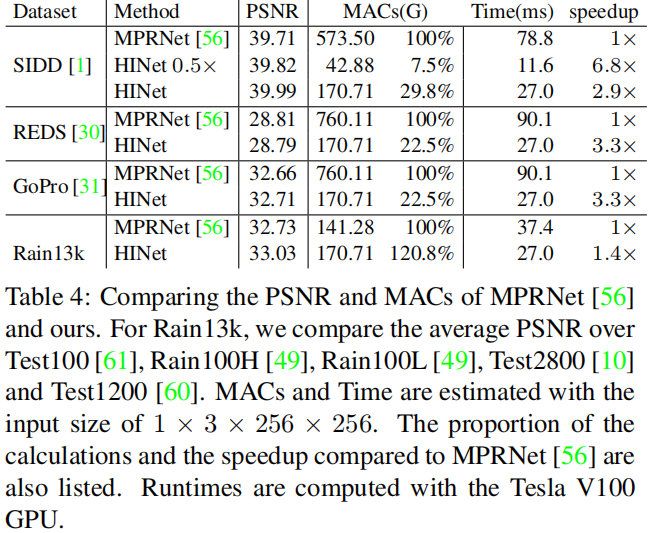
上表对比了所提方案在不同任务上的指标、计算量以及推理耗时对比,可以看到:
- 在SIDD任务上,所提方案HINet推理速度比MPRNet快2.9倍;所提方案HINet0.5x推理速度比MPRNet快6.8倍;
- 在REDS任务上,所提方案HINet推理速度比MPRNet快3.3倍;
- 在GoPro任务上,所提方案HINet推理速度比MPRNet快3.3倍;
- 在Rain13k任务上,所提方案HINet推理速度比MPRNet快1.4倍。

Extension to HINet
为获得NTIRE2021图像去模糊Track2的更佳性能,我们对HINet进行了扩展,并采用了TTA(Test Time Augmentation)策略。为进一步增强性能,我们集成了三个相似模型。除了测试阶段结果外,下面的指标均在REDS-val-300数据上测试所得。
Wider, Deeper 已有研究表明:提升模型的宽度和深度可以提升模型能的建模能力。对于宽度,我们简单的采用HINet2x;对于深度,我们在每个编码和解码抹开后添加两个残差模块。它取得了29.05dB指标。
Test Time Augmentation and Ensemble 我们采用镜像和旋转作为测试时增广,它可以带来0.14dB指标提升;我们随机裁剪上百个快,然后在每个快上随机镜像、随机旋转,带来0.05dB指标提升;简单的采用三个模型集成可以带来0.01dB指标提升。通过这些策略,模型指标可以从29.05dB提升到29.25dB;
Development phase result 开发阶段我们随机裁剪720个图像块,结果见下表。

Test phase result 在测试阶段,我们随机裁剪1000个图像块,结果见下表。
推荐阅读
- NTIRE2021图像去模糊竞赛冠军方案: EDPN
- NTIRE2020图像去模糊冠军方案分享,首次解决跨设备部署问题
- NBNet|图像降噪新思路,旷视科技&快手科技联合提出子空间注意力模块用于图像降噪
- CVPR20201|港理工&达摩院张磊团队提出支持实时4K超高分辨率Image2Image的拉普拉斯金字塔变换网络
- 浙大&微软联合提出实时视频增强|RT-VENet
- 图像增强领域大突破!以1.66ms的速度处理4K图像,港理工提出图像自适应的3DLUT
- 真正实用的退化模型:ETH开源业内首个广义盲图像超分退化模型,性能效果绝佳