【多模态论文解读】Align before Fuse: Vision and Language Representation Learning with Momentum Distillation
- Name: ALBEF
- Key words: Multimodal; Contrastive Learning; Knowledge Distillation
- Year: 2021
- Source: NeurIPS
- Paper: https://arxiv.org/abs/2107.07651
- Code: https://github.com/salesforce/ALBEF
本文介绍了一种名为ALBEF的高效视觉语言模型,采用了对比学习预训练的方式,能够学习到图像和文本之间的丰富关系,为视觉问答、图像分类、图像生成等下游任务提供更好的表征。ALBEF主要由三部分组成:image encoder、text encoder&multimodal encoder、momentum model。它的预训练目标主要包括对比损失、掩码语言重建任务和图像文本匹配任务的损失函数。此外,作者还提出了一种Momentum Distillation的方法,用于从动量模型生成的伪目标中学习,以便有效学习带噪声的图像文本对。实验结果表明,ALBEF在多个下游任务中表现出色,具有广泛的应用前景。
1 讲故事
视觉语言模型的目的在于从大规模的图像文本对中学习多模态表征,用以提升下游的视觉语言任务性能。目前的大多数方法都依赖预训练的目标检测器来提取图像特征,然后再使用一个multimodal encoder来融合图像特征和token embedding,虽然这种方法有效,但是却有三点限制
1)基于object detector的region feature需要较高的注释成本和计算成本,有效但不高效
2)图像的区域特征和文本的嵌入向量都是在各自的特征空间提取的,只在multimodal encoder中进行特征交互,具有一定的建模困难
3)现在的大多数网络收集的大规模图像文本对数据集具有一定程度的噪声,上述方法的预训练目标(MLM、ITM)可能会过拟合,消解网络的泛化能力
因此,针对上述限制,作者提出了align before fuse模型,首先分别使用object-free的图像特征编码器和文本编码器分别提取到图像和文本输入的特征,随后使用multimodal encoder融合文本图像中的跨模态信息,并使用image-text contrastive loss来对齐不同模态的特征信息。ALBEF模型有三个优点
(1) 该模型调整了图像和文本特征之间的对齐关系,使跨模态编码器更容易执行跨模态学习
(2) 改善了单模态编码器对图像和文本语义意义的理解
(3) 学习了一个常见的低维空间来嵌入图像和文本,这使得图像-文本匹配目标通过对比hard-negative样本的挖掘来找到更有信息量的样本
2 看故事
除了ALBEF之外,还有一些重要的视觉语言模型,例如:
- VisualBERT:使用Transformer编码器和解码器来执行多模态任务,单流模型,在输入端进行text-image-feature拼接
- ViLBERT:使用视觉和语言双向嵌入来处理视觉问答和自然语言推断等任务,双流模型,单独使用region-feature encoder和text-encoder提取特征,通过transformer layer(encoder)进行co-attention的阔模态交互
- LXMERT:在ViLBERT的基础上进行了改进,使用了更强大的特征提取器和更复杂的多模态交互机制
- UNITER:使用Transformer编码器和解码器来执行多模态任务,同时使用了对比学习和知识蒸馏等技术
- ViLT:使用对比学习来预训练视觉语言模型,为下游任务提供强大的多模态表征。单流模型,输入前就特征拼接。由于单流模型无法分别提取text or image feature,故作者在得到encoder输出后又过了一层pooler,目的在于将输出投影到2d上进行logits,选择对数似然最为ITM的损失
每个模型都有其独特的结构和预训练目标,旨在学习多模态表征以提高下游任务的性能。接下来可以通过网络模型及预训练目标的对比更好地理解ALBEF模型。
2.1 网络结构概览
主要看单流模型VisualBERT、ViLT以及双流模型ViLBERT与ALBEF的对比
2.1.1 VisualBERT
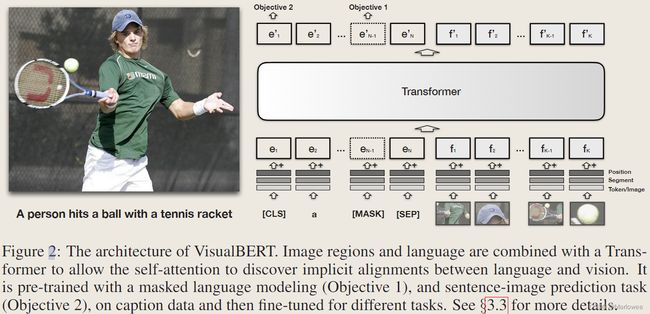
VisualBERT是一种强大的单流视觉语言模型,采用Transformer编码器和解码器架构来学习多模态表征,以用于各种下游任务。在输入端,VisualBERT接受文本和图像特征的拼接,得到文本和图像的联合表示。
该模型的预训练目标包括Masked Language Modeling(MLM)和Image-Text Matching(ITM)。MLM是一种语言建模目标,模型在此目标下受到训练,以预测输入文本中的掩码单词。ITM是一种目标,模型在此目标下受到训练,以评分图像和相应文本说明之间的相似性。这些目标确保VisualBERT能够理解文本和图像输入之间的关系,并生成能够捕捉两种模态的语义意义的有意义表示。
VisualBERT使用对比损失函数来训练模型,旨在最大化正样本图像-文本对之间的相似性,并最小化负样本之间的相似性。对比损失函数包括图像和文本输入之间的相似度度量和负样本度量,鼓励模型区分相似和不相似的图像-文本对。这种训练方法使VisualBERT能够学习到强大的多模态表示,可用于各种下游任务。

总的来说,VisualBERT是一种非常有效的模型,用于学习文本和图像的联合表示,并在各种视觉语言任务中取得了最先进的性能。它采用了Transformer编码器和解码器架构,以及预训练目标和对比损失函数,使其成为自然语言处理和计算机视觉任务中涉及多模态数据的强大工具。
WARNING:上面几段话是GPT生成的
2.1.2 ViLBERT
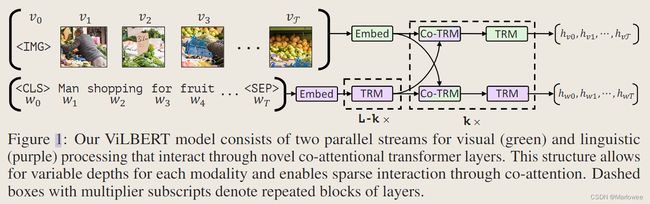
ViLBERT是一种先进的视觉语言模型,利用了BERT(双向编码器表示来自Transformer)的强大功能,学习图像和文本的联合表示。ViLBERT是双流模型,包含两个独立的编码器:一个用于处理文本,另一个用于处理图像。每个编码器由多个Transformer层组成,这是一种在自然语言处理和计算机视觉任务中取得巨大成功的神经网络架构类型。
ViLBERT的输入是图像和文本,其中图像输入是一组视觉区域,每个区域由特征向量表示,文本输入是由单词嵌入向量组成的句子。ViLBERT的输出是表示图像和文本之间关系的向量。
ViLBERT的预训练目标包括Masked Language Modeling(MLM)和Image-Text Matching(ITM)。MLM是一种语言建模目标,ViLBERT在此目标下受到训练,以预测输入文本中的掩码单词。ITM是一种目标,ViLBERT在此目标下受到训练,以评分图像和相应文本说明之间的相似性。
ViLBERT使用对比损失函数来训练模型,它旨在最大化正样本图像-文本对之间的相似性,同时最小化负样本之间的相似性。对比损失函数包括图像和文本输入之间的相似度度量和负样本度量,鼓励模型区分相似和不相似的图像-文本对。
WARNING:上面几段话是GPT生成的

ViLBERT的设计其实就跟ALBEF对比学习任务很像了,拿fig3(b)来看,ViLBERT使用的预训练目标是图像文本对匹配任务,具体而言是抽取image encoder输出的IMG token和text encoder输出的CLS token,二者代表了各自模态上的全局特征,因此可以直接将二者相乘计算相似度,从而判断文本信息和图像信息是否匹配,得出Aligned or Not Aligned的最终输出。
其实fig(a)也有好玩的一点,因为还有一个MML多模态掩码重建的训练目标,所以不仅要对文本掩码重建(这一点大家都熟,就不赘述了),还要对图像掩码重建。这里的图像其实更具体而言是特征区域(feature-region),也就是通过预训练的Faster-RCNN提取的区域,显而易见他们的尺寸也是不相同的,所以直接预测这个特征区域像素点是不可行的。所以作者这里转化了一下思路,从元素个体而言,不同的特征区域像素值肯定有差异,而从区域整体而言,不同特征区域的分布肯定也存在差异,所以作者直接去预测特征区域的分布,使用KL散度来衡量预测分布与真实分布之间的差异,并最小化这个差异
概念
KL散度(Kullback-Leibler Divergence)是一种度量两个概率分布之间差异的方法。它可以用来比较两个概率分布的相似性或差异性,也可以用来评估一个概率分布对另一个概率分布的逼近程度
公式
D K L = ( P ∣ ∣ Q ) = ∑ i = 1 N [ p ( x i ) log p ( x i ) − p ( x i ) log q ( x i ) ] D_{KL}=(P||Q)=\sum_{i=1}^{N}[p(x_i)\log p(x_i)-p(x_i)\log q(x_i)] DKL=(P∣∣Q)=∑i=1N[p(xi)logp(xi)−p(xi)logq(xi)]
其中 P P P和 Q 分别表示两个概率分布,i表示样本空间中的第 i 个元素。KL的值越小,表示两个概率分布越相似;KL 的值越大,表示两个概率分布越不相似。
举个例子:
班里男生占40%,女生占60%,则班里随机抽取一个人的性别的概率分布是Q = [0.4, 0.6]
小明猜测班里男生占30%,女生占70%,则小明拟合的概率分布P1 = [0.3, 0.7]
小红猜测班里男生占20%,女生占80%,则小红拟合的概率分布P2 = [0.2, 0.8]
K L 1 = [ 0.3 × log ( 0.3 ) − 0.3 × log ( 0.4 ) ] + [ 0.7 × log ( 0.7 ) − 0.7 × log ( 0.6 ) ] = 0.0216 KL_1=[0.3\times\log(0.3)-0.3\times\log(0.4)]+[0.7\times\log(0.7)-0.7\times\log(0.6)]=0.0216 KL1=[0.3×log(0.3)−0.3×log(0.4)]+[0.7×log(0.7)−0.7×log(0.6)]=0.0216
K L 1 = [ 0.2 × log ( 0.2 ) − 0.2 × log ( 0.4 ) ] + [ 0.7 × log ( 0.8 ) − 0.8 × log ( 0.6 ) ] = 0.0915 KL_1=[0.2\times\log(0.2)-0.2\times\log(0.4)]+[0.7\times\log(0.8)-0.8\times\log(0.6)]=0.0915 KL1=[0.2×log(0.2)−0.2×log(0.4)]+[0.7×log(0.8)−0.8×log(0.6)]=0.0915
K L 1 < K L 2 KL_1
KL1<KL2 ,因此小明的预测与Q更接近
2.1.3 ViLT

ViLT(Vision-and-Language Transformer)是一种使用对比学习预训练的视觉语言模型,设计目的是学习多模态表征以提高下游任务的性能。具体而言,ViLT采用单流模型,输入前特征拼接,输入由文本和图像特征组成。
ViLT的输入包括图像和文本信息。其中,图像输入是一组图像特征,每个特征是对图像的不同区域进行编码得到的。文本输入是由单词嵌入向量组成的句子,这些单词嵌入向量可以通过预训练的方式得到。
在预训练阶段,ViLT使用了对比学习的方法,最大化正样本的相似性并最小化负样本之间的相似性。具体而言,该模型使用了多种损失函数,包括图像和文本输入之间的相似度度量和负样本度量,以鼓励模型区分相似和不相似的图像-文本对。该模型使用的损失函数旨在最小化正样本图像-文本对之间的距离,同时最大化负样本之间的距离。这种训练方法使ViLT能够学习到强大的多模态表示,可用于各种下游任务。
ViLT的预训练目标是使用对比学习来预训练视觉语言模型,以便为下游任务提供强大的多模态表征。模型输出是表示图像和文本之间关系的向量。该向量可以用于下游任务,如视觉问答、图像分类、图像生成等。ViLT的设计目的是学习多模态表征以提高下游任务的性能。
总的来说,ViLT是一种高效的视觉语言模型,具有强大的多模态表征能力。使用对比学习预训练的方式,ViLT能够学习到图像和文本之间的丰富关系,从而为下游任务提供更好的表征。ViLT的设计使其适用于多种下游任务,是一种在视觉语言领域有着广泛应用前景的模型。
WARNING:上面几段话是GPT生成的

感觉Transforemrs提出来之后,图像端再用object-detector去提特征的方法就慢慢被舍弃了,主要是由于CNN的计算消耗大而且这种方法后处理也挺费劲
2.1.4 ALBEF

- 网络结构
ALBEF主要包括三部分:1)image encoder,使用的12层的视觉Transformer ViT-B/16,使用ImageNet-1k上的预训练权重提特征;2)text encoder&multimodal encoder:两部分加起来相当于一个bert-base模型,也就是说相当于用了一个解耦的bert模型,前半部分作为text-encoder,后半部分联合image-tokens就行跨模态学习;3)momentum model,主要是为了有效学习带噪声的图像文本对,具体细节后边再说
- 输入输出
ALBEF的输入跟大部分的双流网络相同,即各自encoder接收的视觉特征或文本特征
输出有两部分,一部分是用于对比学习的输出,这部分输出只提取cls token来计算相似度;另一部分则是multimodal的输出,用于掩码重建任务及图像文本对匹配任务;
- 损失函数&预训练目标
首先是对比损失,利用image encoder、text encoder输出的特征做对比,但是这部分输出只提取cls token来计算相似度,并且会将这个768-d的token映射到256-d后,再计算image与text的相似度,公式如下图所示,其中的g是768→256的线性投影层

其次是掩码语言重建任务的建模损失,这部分主要是用图像和上下文的文本信息进行掩码重建,不再赘述
![]()
最后是图像文本匹配任务的损失。也是使用multimodal encoder的cls token作为多模态的联合表示,通过一个线性投影层预测是否匹配,其损失函数如下
![]()
其实刚开始我都没区分清楚图像文本对比ITC和图像文本匹配ITM的差异在哪里,于是又回头看了之前综述讲过的VisualBERT、ViLBERT、ViLT,才有点头绪。
用我的理解来说,ITC主要是利用单个模态的输出进行对比学习,而ITM则需要利用跨模态中的信息进行匹配,虽然说二者都是使用代表全局信息的cls token,但是token所包含的信息是有不同的侧重点的。所以在ITC中,要计算图像文本是不是相关,还需要将二者点乘后得到联合信息投影,而ITM则直接将最后得到的CLS token进行投影。
ALBEF总损失/总预训练目标:
![]()
- Momentum Distillation
用于预训练的图像文本对大多都收集自网络,往往都包含噪声。因此,正样本对经常是弱相关的,即文本包含和图像无关的文字或图像包含文本中没有描述的实体。对于ITC学习,图像的负样本文本可能也会匹配图像的内容。对于MLM,可能存在其他和标注不同的词能够更好地描述图像。但是ITC和MLM的one-hot标签会惩罚所有负标签预测,不考虑它们的正确性。
为了解决这一问题,作者提出从动量模型生成的伪目标中学习。动量模型是一个不断发展的教师模型,包含单模态和多模态编码器的指数移动平均版本。在训练过程中,作者训练基本模型使得它的预测值和动量模型的相匹配。对于ITC,作者首先使用来自动量单模态编码器的特征计算图像文本相似度,然后计算伪目标。
作者展示了伪目标中前5个候选对象的示例,有效地捕捉了图像的相关单词或文本。

2.2 下游任务表现
作者首先在加噪的总共14.1M的Conceptual数据集上进行预训练,结果如下

table1展示了不同变体在各种下游任务上的性能表现,基本上添加新的预训练目标在一定程度上能够提升模型性能,并且模型性能也会受到参数规模的影响

table2-4展示了不用下游任务中的模型表现,ALBEF在图像文本检索任务Flickr30k中的性能还是比较出色的,在参数量只有CLIP的1/28情况下超了6个点
其实最让我感兴趣的还是作者在附录中展示的交叉注意力图的可视化,可以看到模型不仅能分辨出真实世界中的客观实体,还能学习到抽象的关系或者动作,像working、wearing、old这种信息都能学到,牛的!
复盘
- Q1 故事讲完整了吗
我觉得应该算是比较完整了。对于开篇提出的三个问题:image encoder效率低、input info交互性低、带噪数据泛化能力低,分别提出了解决方法:pretrained ViT-B/16、ITC&ITM、Momentum Distillation
- Q2 故事新颖在哪里
主要是把bert-base解耦,也就是针对第二个问题的部分吧。其实这篇文章并不是一开始就找到研读的,一开始是在看CVPR2023的一篇多模态预训练工作CoCa(性能炸裂,争取过两天读明白写个博客),CaCo的创新点跟ALBEF的创新点不是完全相同,就是一模一样,这里放个CoCa的网络结构,所以先看了这篇早期的工作。
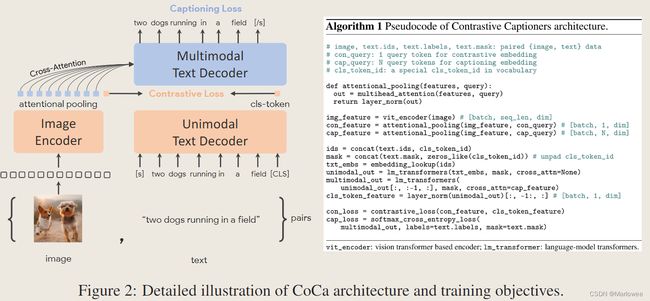
ALBEF的故事中把ITC&ITM都用上了,属于是既要又要了,既要学习单个模态在各自空间上的关联,又要学习交叉注意力后的联合信息。
- Q3 为什么想到解耦bert-base,还有其他方法吗?
没想清楚,留个坑