实例示范( 泰坦尼克沉船数据分析之一)

欢迎关注公众号 数据分析指北
数据分析指北 - 实例示范( 泰坦尼克沉船数据分析之一)
历史回看:
基础(数据来源及轮廓)
基础( KNIME 基础模块之一 )
附录三 软件的成本,数据分析的成本

Photo by F.G.O. Stuart(1843–1923)
微信公众号:数据分析指北
泰坦尼克 titanic
数据探索
原始数据
对原始数据进行粗略观察
稍进一步观察数据
泰坦尼克 titanic
泰坦尼克号是一艘英国皇家邮轮,在服役期间是全世界最大的海上船舶,号称“永不沉没”,“梦幻之船”。它在头等舱的设计上极尽奢华和舒适,设有健身房、游泳池、接待室、高档餐厅和豪华客舱,甚至还有一台高功率的无线电报机。在一百多年前,这样的配置是当时的最高标准了。
1912年4月10日,泰坦尼克号展开首航,也是唯一一次载客出航,它是从南安普敦出发的,最终的目的地为纽约。除了约908名船员外(男性船员885名,女性船员23名),还有乘客约1316人:头等舱325人、二等舱285人、三等舱706人,其中805人是男性,402人是女性;船上有109名儿童,其中79名都在三等舱(以上数据来源于维基百科中英国贸易委员会)。船上乘客多种多样,包括世界上最富有的一些人、社会名流,也包括一些其他地方的穷人移民 – 他们寻求在美国展开新生活的机会。
4月14至15日子夜前后,泰坦尼克号在中途碰撞冰山后沉没。2224名船上人员中有1514人罹难,成为近代史上最严重的和平时期船难。在危难时刻,不同的人以不同方式对死亡的威胁做出反应,有人接受命运、有人为生存而战。船上的许多人不得不在他们的人际关系中作出不可能的选择:与丈夫和儿子待在船上,或独自搭上救生艇生存下来。似乎有一些“女人和小孩优先”原则确认了侠义男子气概,还有千万富豪约翰·雅各·阿斯特四世和本杰明·古根海姆的自我牺牲,证明了富人和强者的慷慨和道德优越,在很多方面,这次船难都产生了深远和持久的影响。
船难解释方式和角度如此广泛,因此这场灾难经过许多年后仍是民众争论和着迷的主题。Kaggle是世界上最大的数据科学家以及机器学习爱好者的社区,他经常会举行很多数据比赛,吸引众多从业者以及爱好者参加,它的入门练习比赛就是分析这次船难的数据,通过机器学习得到一个模型,预测哪些人是幸存者。
因为哪些人存活下来已经成为了一个事实,所以这个比赛是这样的:给你提供一部分的船上人员的数据,让你构建模型,并让你预测另外一部分船上人员的存活情况,并与事实进行对比,来验证构建出来模型的准确性。
数据探索
原始数据
原始数据是以CSV文件提供给我们的,train.csv 共有891行,12列,各列的解释如下:
| 变量 | 解释 |
|---|---|
| PassengerId | 乘客编号 |
| survived | 是否存活下来, 1代表存活, 0代表死亡 |
| pclass | 船舱等级, 1代表头等舱, 2代表二等舱, 3代表三等舱 |
| name | 乘客姓名 |
| sex | 性别 |
| Age | 年龄 |
| sibsp | 同在船上的兄妹及配偶的数量 |
| parch | 同在船上的父母或子女的数量 |
| ticket | 船票座次号 |
| fare | 船票费用 |
| cabin | 船舱号 |
| embarked | 上船的港口, C = Cherbourg, Q = Queenstown, S = Southampton |
对原始数据进行粗略观察
首先我们先通过CSV Reader模块读入train.csv,如下图所示:

CSV模块读取原始数据
在进一步分析数据之前我们对数据要有一个大概的认识,通过在CSV节点上单击右键,看一眼数据:
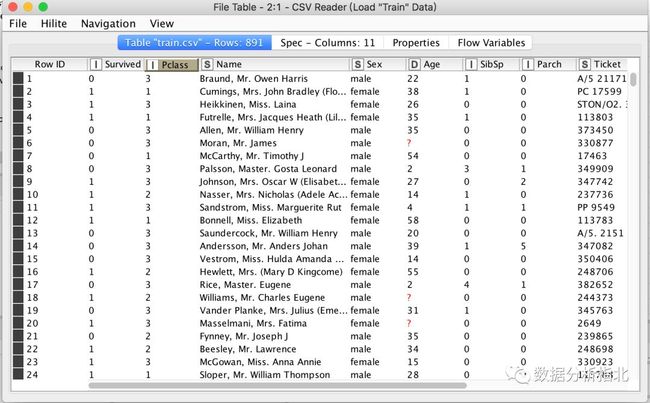
看一眼原始数据
可以看到,数据已经被我们正确配置的CSV节点读入,单击列名时,可以对这一列数据进行升序或降序排列。有一点细节需要稍微注意一下,表头中Survived之前有个I,代表了这一列数据的类型,I代表integer整数类型,S代表String字符型,D代表double双精度浮点型等等。数据类型是个人认为比较重要的部分,因为对于一些节点,只能处理特定类型的数据。举例来说,如果你将日期存储成了整数,比如20190301,或被 KNIME 误读成了整数,当你需要进行一些日期的操作,比如要确定这个日期是这一年中的第几天,那么就得把这个整数转换成日期类型,然后再去做日期类型的计算。但是并没有整数直接转换为日期类型的节点,只有字符转换为日期类型的节点,你只能做如下类似操作了:

对整数记录的日期进行操作
好,我们继续对现有的数据进行观察,在这里我们先使用模块自带的spec标签页对数据进行粗略观察:
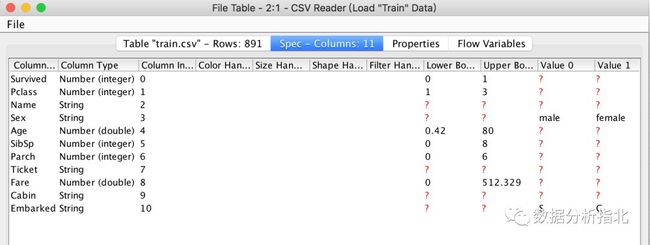
通过spec标签页对数据粗略观察
可以看到一些数据被解析为错误的类型,比如survived列中的1代表存活,0代表死亡,这不应该算是整型值(因为整型还可以有其他数值可选,比如2,3等等),这个问题我们在下文会进行处理。
通过原始数据以及spec标签页的粗略观察,我们或多或少对对数据有一些问题,这些问题可以成为我们探索的起点:
- 年龄有从0.42岁到80岁的,船票有从0镑到500多镑的,兄妹和配偶总数有8个之多的等等,他们的生存概率一样吗
- 有一些数据会存在丢失的情况,丢失的数据在表格中是以?问号呈现的,这些数据如何处理,会不会影响到最终模型的效果
- 船票座次号,以及上船的港口这种数据对存活或是死亡这件事有影响吗?
- 等等
在python中,当我们读取完数据,会对数据进行一个基础的统计,使用的是pandas.describe函数;而在KNIME中,也有类似的功能,就是Statistics模块,我们连接上这个模块,并对结果进行观察:
配置并打开Statistics模块
这个node不需要进行太复杂的配置即可使用,对其结果进行观察如下:

使用Statistics模块观察数值型的值
Statistics将数据分成两大类,一类是数值类型的值,放在一个标签下,一类是名义类型的值,放在另外一个标签下。对于数值类型的值,可以有一些基本的统计方法对数据进行统计,比如这一列的最小值、最大值、中值、均值、标准差、峰度、偏度等等,当然最有意思的还是这个数值型值的分布,了解这个就会对这列数据有一个整体上的把握。比如age年龄这一列,是比较接近正态分布的,而其有177个缺失值,如果要填补缺失值,那么就可以考虑用正态分布的最中间的那个峰,即均值对数据进行补充。
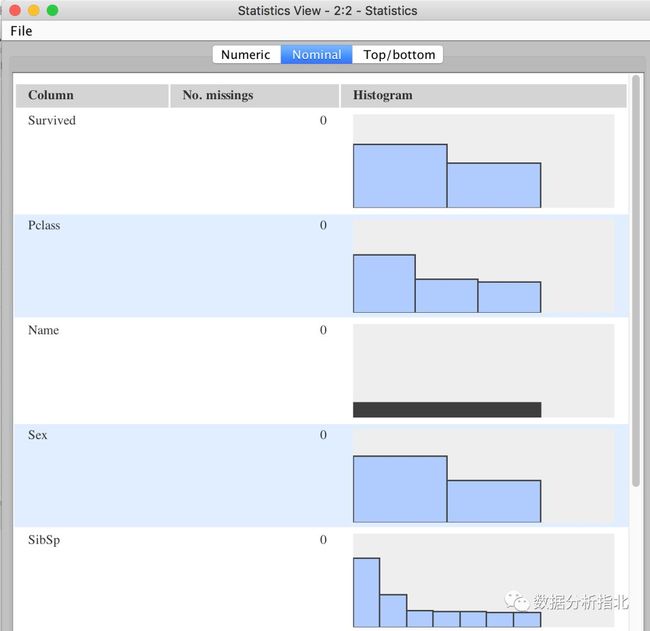
使用Statistics模块观察名义类型的值
而对于名义类型的值,也有专门的标签来对他们进行一个整体上的描述,比如幸存标记Survived列显示,幸存者和死亡者是差不多的(但我们最终知道,总体数据其实不是这样,死去的人很多,这也是我之前在“基础部分数据来源及轮廓”里所讲的,要了解真实世界的数据分布与你手上数据分布的差异并尽可能减少这部分差异);比如pclass,船舱等级这一列,一眼望去就知道有三种类型,三等舱的人数是头等舱和二等舱的两倍还多一些,等等。
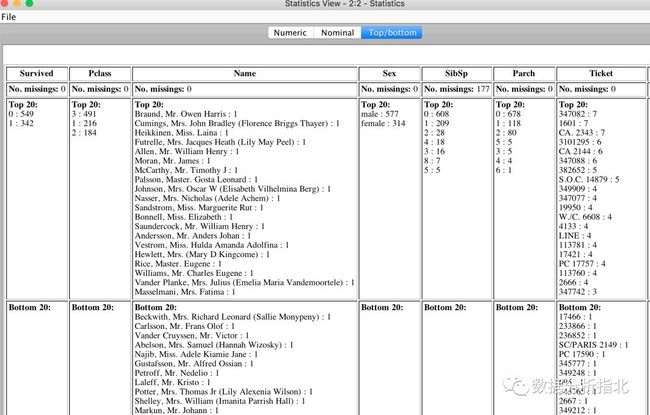
使用Statistics模块观察排名前二十和后二十
另外还有各列中排名前二十和后二十的数据可供我们参考。
稍进一步观察数据
我们可以再进一步观察数据的分布,先通过number to string节点,将错误归类为数值型的Survived和Pclass转换为字符,变成名义类型的值:
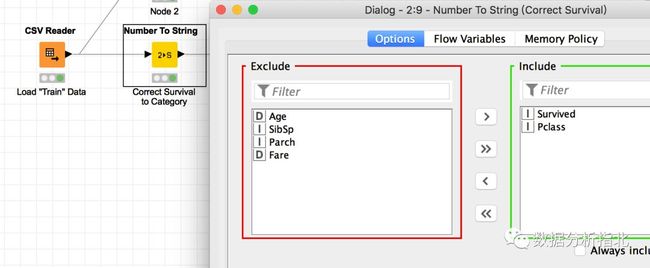
使用number to string节点转换数据类型
然后使用Color Manager对Survived列进行不同颜色的标记,存活1为绿色,死亡0为红色:
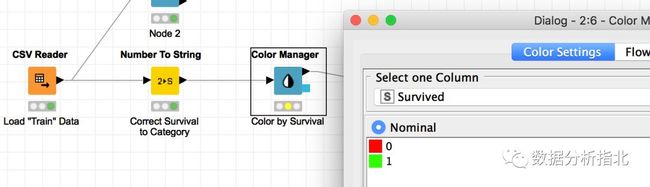
对数据进行颜色标记
我们可以看一下标记之后的数据:
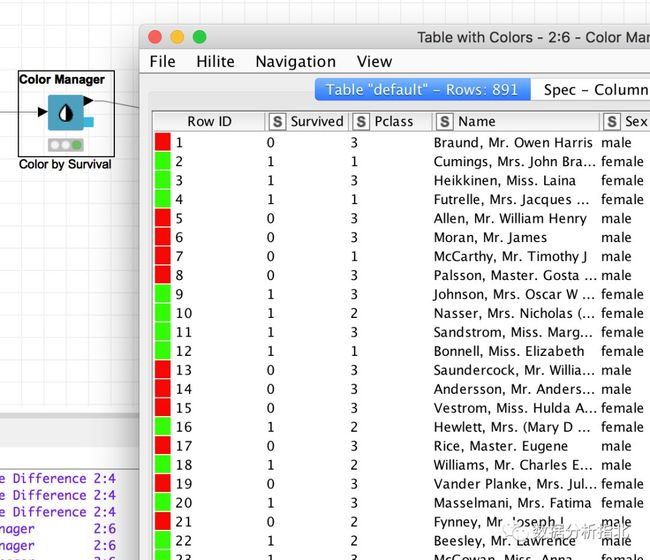
经过颜色标记的数据
颜色标记是KNIME中一个很特别的功能,这一部分功能我们在04可视化章节有过描述(然而还未完成= =;)。最后,我们使用Histogram节点来观察经过颜色标记过的数据,在节点输出选择“Column/Aggregation Settings”标签,注意右下角的binning column选项:

Histogram节点输出图像结果配置
直方图的制作是这样一个过程:计算机会按照你对某一个数据的要求分成几个不同的桶(bin),来一行数据,判断这行数据符合哪个桶的要求,就在那个桶里面扔一个球,把所有的数据遍历一遍之后,把桶中球的个数,当作纵坐标的值就可以了。在SQL中就是group by然后再count(*)的过程。
也就是说,如果我们想要按照性别这个条件进行分桶,那么只需要在binning column中选择sex就可以了!

按照性别进行分桶binning
如果没有之前的对存活或死亡的数据进行标注,那么我们只能看到所有船上人员男性和女性的直方图对比,但现在我们可以很明显的看到,虽然女性在整个船上人员中的比例相对较少,但女性的存活比例要远远高于男性。
如果我们按照年龄进行分桶,然后对比各个年龄段的存活和死亡人数,那么只需要在binning column选择age,然后配置一下图形的选项即可:

按照年龄进行分桶binning
如果我们按照船舱等级进行分桶,那么将会得到如下结果:

按照船舱等级进行分桶binning
REF:
- 泰坦尼克号 - 维基百科: https://zh.wikipedia.org/wiki/%E6%B3%B0%E5%9D%A6%E5%B0%BC%E5%85%8B%E5%8F%B7
- Titanic: Machine Learning from Disaster | Kaggle: https://www.kaggle.com/c/titanic
- https://www.byrnedata.com/blog/2017/3/6/using-knime-for-kaggle-titanic-survival-model
回头聊
给赞是支持,转发是更大的支持
