深度学习——常见问题
算法工程师炼丹Trick手册
https://mp.weixin.qq.com/s/hjtIFse5agAFBwuQcVBK2w
数据太少怎么搞深度学习?
https://mp.weixin.qq.com/s/wn5XYtEguhXAasVx8M37pw
在我们讨论利用有限的数据进行深度学习的方法之前,请忘了神经网络并创建一个简单的基准。尝试一些传统模型(如随机森林)通常不需要很长时间。这将帮助你评估深度学习的任何潜在提升,并深入理解在你的问题上深度学习与其它传统方法的权衡取舍。
获取更多数据
花时间和金钱来收集更多数据。实际上,这通常是你的最佳选择。
不确定需要收集多少数据?尝试在增加数据时绘制学习曲线并查看模型性能的变化。
微调(Fine-Tuning)
微调的基本思想是用一个非常大的数据集,该数据集最好和你数据的领域有些相似,训练一个神经网络,然后用较小的数据集微调此预训练网络。
数据增强(Data Augmentation)
数据增强最常用于图像分类问题,比如常见的旋转、平移、镜像、局部。
GAN来生成新数据。
余弦损失(Cosine Loss)——比较前沿
最近一篇paper 《Deep Learning on Small Datasets without Pre-Training using Cosine Loss》, 使用余弦损失在没有进行预训练的情况下对小型数据集进行深度学习的研究发现,将损失函数从分类交叉熵损失切换为余弦损失时,分类问题小型数据集的准确率提升了30%。
自编码器(Autoencoders)
使用堆叠式自编码器以更理想的初始权重对网络进行预训练已经取得了一些成功。这可以让你避开局部最优解以及其它错误初始化的陷阱。不过Andrej Karpathy 建议不要对无监督的预训练过度兴奋。
自编码器的基本思想是建立一个可预测输入的神经网络。
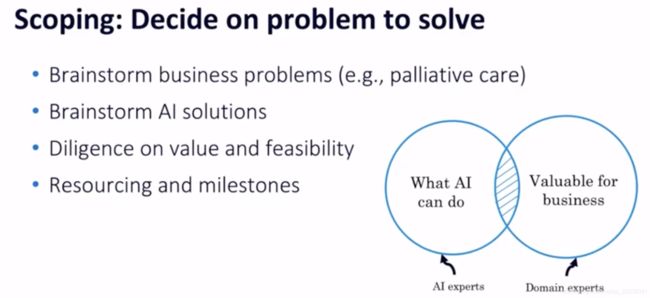
先验知识(Prior Knowledge)
最后但并非最不重要的一点是,尝试找到整合领域特定知识以指导学习过程的方法。例如,在paper "Human-level concept learning through probabilistic program induction"中通过概率性程序归纳法,作者构建了一个模型,该模型通过利用过程中的先验知识从各个部分构建概念。这超越了当时的深度学习方法,达到了人类水平的表现。
你还可以应用领域知识来限制网络的输入,以减少维度或将网络结构调整到更小。
我将其作为最后的选择是因为整合先验知识很有挑战性,且通常是最耗时的。
Making Small Cool Again
深度学习入门的神视频:为什么随机梯度下降方法能够收敛? - YJango的回答 - 知乎 https://www.zhihu.com/question/27012077/answer/501362912
吴恩达:AI部署的三大挑战和解决方案
https://mp.weixin.qq.com/s/KBC1CdNCdrAsTdDzWRRcMQ
bilibili视频:https://www.bilibili.com/video/BV13y4y1r7hY/
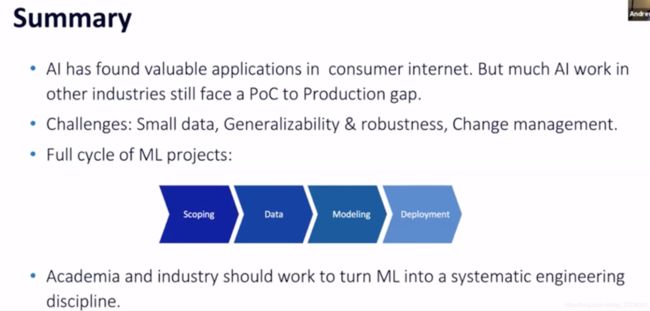
99%的AI价值是由有监督学习算法提供的。

-
小数据在消费者互联网之外的工业应用程序中很常见,而 AI 研究经常使用大数据。
-
算法的鲁棒性和泛化性。模型在已发表的论文中效果好,但在生产中通常不行。
-
变化管理。作为自动化工作流中一个部分,模型可能会潜在地影响整个系统和很多相关者。
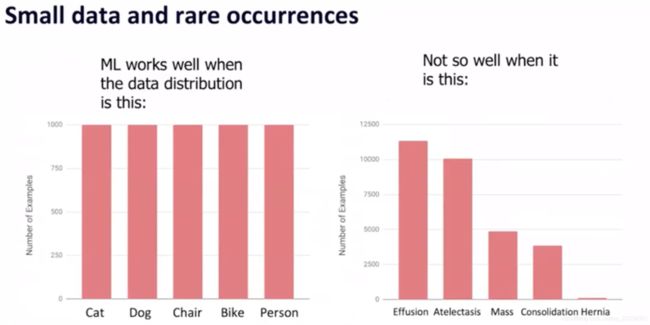
小数据集
很多场景天然就没有海量数据,消费互联网的应用场景。
数据分布不平衡问题,
机器学习的任务并不是在测试数据集上表现有多准确,而是在实际使用时效果有多好。
因为准确率并不能正确反应这类数据不均衡的问题。
针对小样本类别的问题,可用算法:
- 人工合成、数据增强,比如GANs
- one-shot, few-shot学习
- 自监控学习
- 迁移学习
- 异常检测
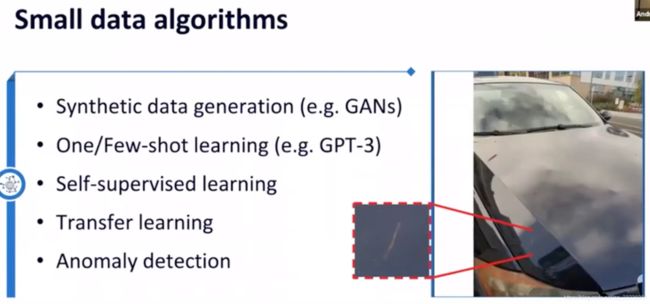
算法的鲁棒性和泛化性
论文实现的算法,在实际生产环境中经常效果不好。
不同训练数据集构建的模型能否扩展与不同的数据集。
变化管理
模型可解释性:
专家不需要解释,直接就能评判;他们需要的是一种确保、保证,AI能够提供合理的结论,解释性对于他们来说就是合理的意思,然后再也不管解释性了
可解释性是为了给谁看的? 你需要他们看到之后做些什么?

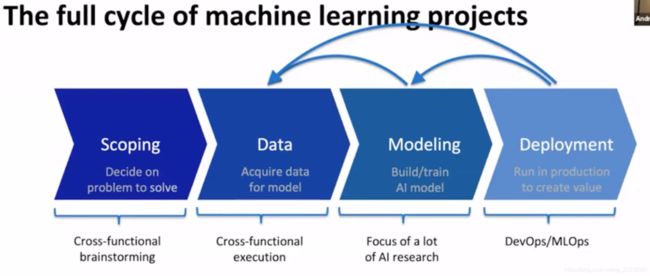
机器学习项目的生命全周期
full cycle of machine learning projects
ML代码只是一小部分。
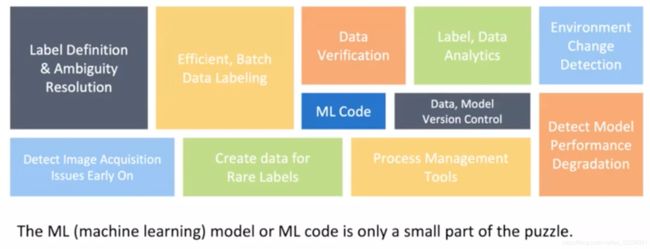
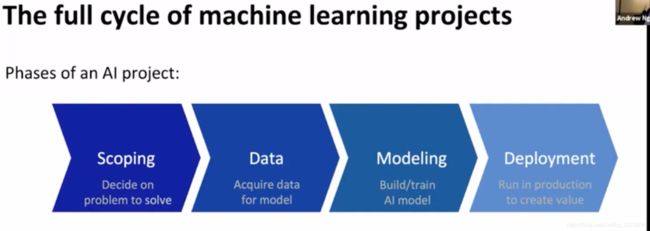
一般是固定训练集,不断调参;但实际可以固定参数,调整训练集,分析模型在为什么会失败(error analysis),是否需要考虑更多场景下但数据
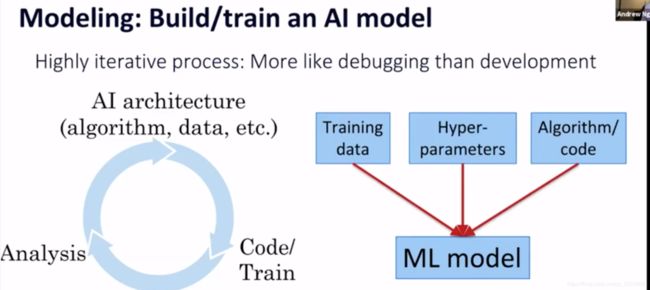
不一定要花两年的时间把所有基础打好,构建起丰富的数据集,然后再把AI作为首要任务去实施;
需要哪些数据?哪种类型的数据? 初步分析后回过头来分析还需要哪些数据?