可观测性在灰度发布中的应用
前言
随着云计算的发展、云原生时代的来临,企业数字化转型进程不断深入,应用开发也越来越多地基于微服务化模式,快速迭代的能力使得应用开发更高效、更灵活。同时,也不得不面临应用版本快速升级所带来的的巨大挑战。
传统的发布方式是通过新版本全量替换旧版本,这种模式存在停机时间较长的问题,业务端的压力愈发明显。同时,在新版本发布时,如果直接将应用程序从当前版本全量升级到新版本,风险存在的可能性和严重性也不容忽视。传统发布方式存在如下一些典型的弊端:
- 影响用户体验:如果新版本存在功能或性能问题,那么,所有新版本服务实例都会存在同样问题,从而影响所有用户的使用。
- 影响服务可用性:全量发布一般需要做停机升级(要么同时都为新版本,要么同时都为老版本),导致业务中断,影响服务可用性。
所以,尽可能降低发布对业务造成的影响就变得越来越重要,“业务无感知”的灰度发布策略就大众的视野中。
灰度发布概述
灰度发布,是一种软件部署策略。常规做法是将新版本的应用程序投入生产环境,保留当前版本,并将一小部分流量重定向到新版本中。在此过程中,所有发送到新版本的请求都将被监测,确认新版本可用后,将逐渐将越来越多的流量引导到新版本中。
通过灰度发布,有助于识别可能存在的潜在错误、性能问题或其他问题,以便在全面部署之前及时解决这些问题,从而极大地减少对更广大用户的使用影响,提高用户体验和满意度,加速迭代速度。
可观测性对于灰度发布的成功非常重要,能够为团队提供实时的服务运行状态的数据支持,从而更好地观测和分析新版本的性能、稳定性和用户反馈等指标,更快地发现和解决问题,提高发布的成功率和用户体验。
可观测性在灰度发布的使用价值
在灰度发布过程中,需要对发布的新版本具备评估分析能力,包括对新版本的性能、稳定性和用户反馈等指标进行分析。可观测性可以帮助团队更好地观测和分析这些指标,从而更快地发现和解决问题。具体来说,可观测性可以帮助团队实现以下目标:
- 监控应用程序的性能和稳定性:通过监控应用程序的指标,例如响应时间、错误率、CPU 使用率等,可以及时发现性能和稳定性问题,并采取相应的措施。
- 实现快速故障排除:通过可观测性工具,可以快速定位和解决问题,减少对用户的影响。
- 支持数据驱动的决策:通过可观测性工具,可以收集和分析大量的数据,为团队提供数据支持,支持数据驱动的决策。
因此,可观测性对于灰度发布的成功非常重要,能够帮助团队更好地监控和分析新版本的性能、稳定性和用户反馈等指标,从而更快地发现和解决问题,提高发布的成功率和用户体验。
可观测性在灰度发布中的应用
要评估灰度发布中不同版本的性能及故障,需要收集和分析运行数据。通过观测云的 one agent 数据采集和标签化能力,能够快速、方便地采集不同服务版本中的运行数据,从而加以分析后,对新版本做出评估。
4.1 测试环境应用部署说明
测试环境中的所有服务是部署在 K8s 中。部署结构如下图所示:
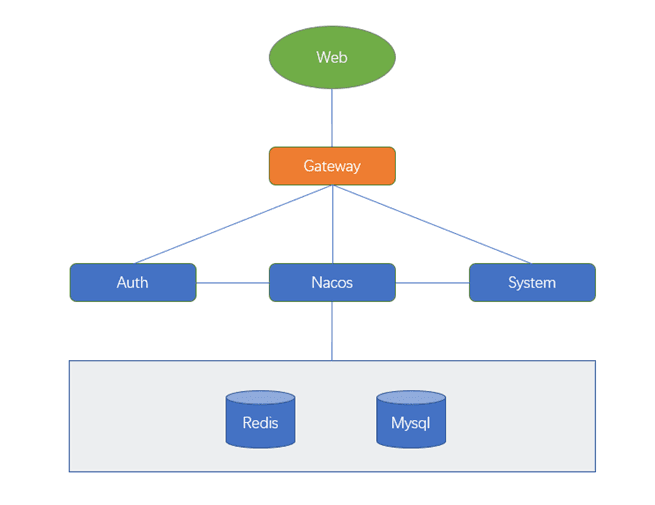
前端 Web 页面请求通过 Gateway 网关访问后端的Auth和System服务,前端 Web 是 Vue 开发的,后端服务是 Java 开发。
4.2 服务版本发布说明
测试将通过对System服务进行灰度发布。发布示意图说明如下:
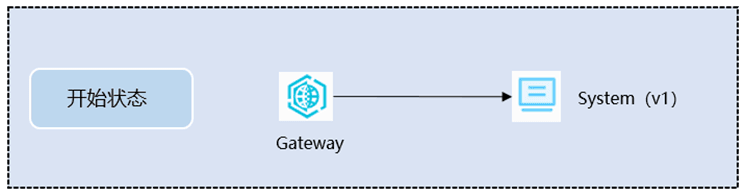
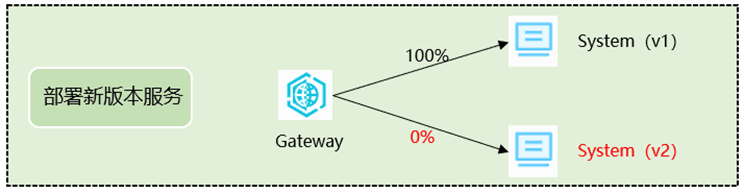
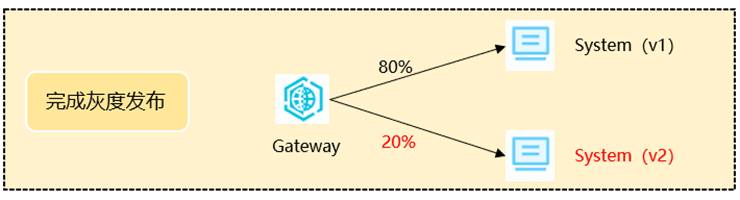
4.3 服务链路的接入和数据标签化
4.3.1 服务链路的接入配置说明
在接入 Java 应用 APM 时,需要使用到dd-java-agent.jar包。在 Kubernetes 的环境中,为了不侵入应用的镜像,常用的方式是在部署应用的 yaml 中使用 initContainers,利用相同 Pod 中的容器共享存储的方式来使用dd-java-agent.jar。
观测云提供 DataKit Operator 的方式向特殊 Pod 提供注入 dd-lib 文件和 environment ,这种方式可以更方便、更快捷地接入应用链路。
4.3.2 标签化说明
标签可以帮助对数据进行分类和组织,通过对服务运行的监控数据打标签,我们可以更好地了解数据的来源、类型、状态等信息,从而更好地进行数据分析。这里,我们就是通过对System服务发布的不同版本打上对应的标签,来实现后续对不同版本运行情况进行观测和分析。
该文中的测试环境中,在服务对应 pod 部署的 yaml 文件中,原始运行服务的版本通过-Ddd.tag参数,打上版本为 version:v1.0的标签。如下图所示:

对新发布的服务版本通过-Ddd.tag参数,打上版本为v2.0 的标签。如下图所示:

通过上述的标签配置,服务对应的所有链路中都会带有对应的版本信息。对应效果如下图所示:
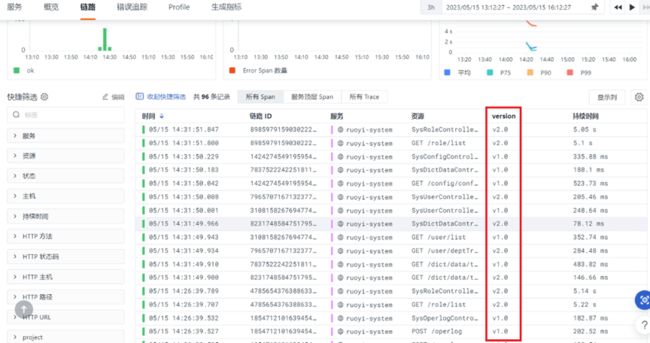
在服务运行的过程中,可以通过对不同版本进行分组来做实时对比观测和分析。
4.4 对服务灰度发布的观测和分析
通过对比新旧两个版本的 QPS、服务执行耗时、服务错误率等指标数据进行实时监测,可以帮助快速发现问题和异常。
4.4.1 看板感知能力
首先,可以通过观测云的「场景」功能,配置针对相关服务灰度发布的观测看板。如下图所示:

通过看板,我们能够实时感知两个服务版本在运行过程中的状态,包括对应的请求数据量、服务错误率、以及服务的响应时间等关键指标。
4.4.2 服务运行状态分析
4.4.2.1 请求数量分析
通过「服务请求数」图表,我们能够清晰知道不同服务版本上的请求量。同时,当新版本做全量切换后,也可以通过该视图来观测全部请求流量是否路由到了正确的服务版本上。
4.4.2.2 服务性能分析
从上图的性能指标中(P75、P90 和 P99),能够直观看到System服务的新版本v2.0比起v1.0存在明显的响应时间长的问题。为了进一步分析该问题,我们可以通过在对应图表上做进一步的下钻,去查看链路的执行详细情况。如下图所示:
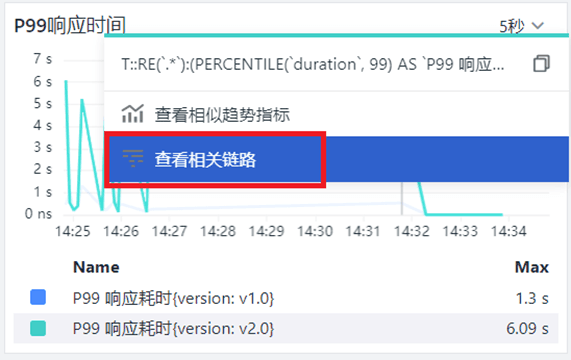
当跳转到「链路」详情页后,可以看到在对应时间段链路的耗时信息。这里也可以通过「持续时间」排序来找到耗时比较长的链路。如下图所示:
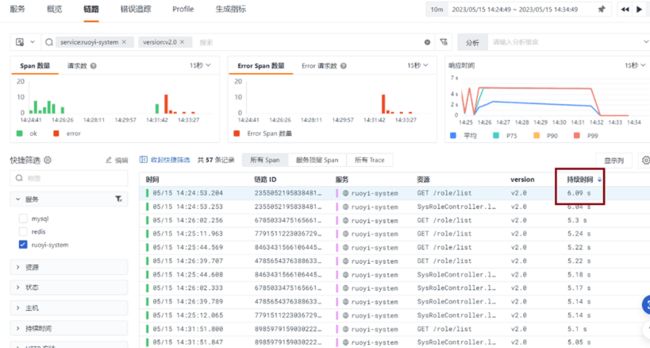
点开其中「执行时间」较长的链路,打开服务执行的「火焰图」详情,如下图所示:
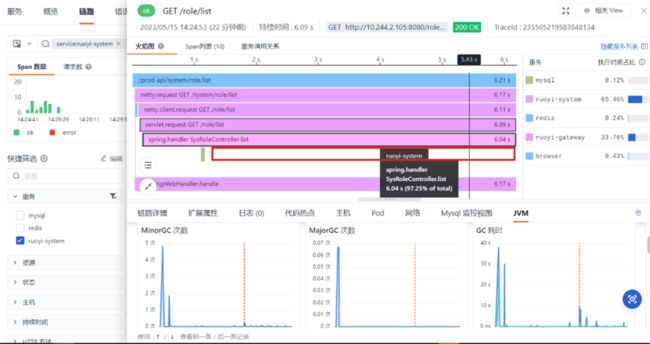
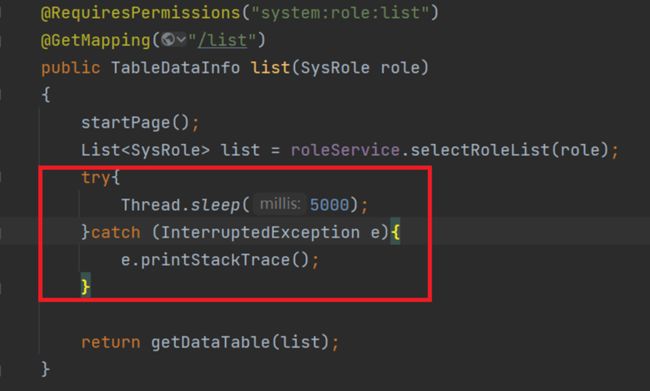
从「火焰图」中,能清晰地看到v2.0版本中的SysRoleController.list这个调用消耗了比较长的时间为 6.04 秒。虽然,该方法调用了 MySQL,但是,从图中可以看到 MySQL 本身执行比较快。所以,问题点并不在数据库侧,需要对代码做进一步分析。
这里将不再做进一步的分析。因为为了模拟性能问题,在v2.0的相关代码中简单加了 5s 的 sleep,整体执行时间也和上面的火焰图对得上。
4.4.2.3 服务错误率分析
通过看板中的「服务错误率」图表,可以感知同一服务的不同版本在运行过程的错误发生情况。对错误率较高的服务版本,同样可以通过图表的下钻能力去查看对应错误的链路情况。如下图所示:

通过链路的详情页面,可以查看更进一步的执行错误信息。如下图所示:
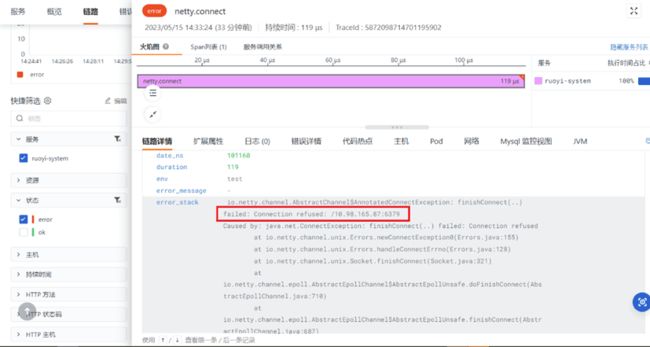
不仅如此,也可以在链路详情中关联应用日志、主机资源使用、网络和 JVM 运行情况等数据做关联分析,提高问题定位和根因溯源的效率。