Python基础语法----数据类型
我们先思考一个问题,为什么需要不同的数据类型?这要借用一句俗语“杀鸡焉用牛刀”,虽然两者都是刀,但属于不同的类型,如果两者混用,要么出现大材小用的情况,要么出现不堪使用的情况,由此可以看出,正是有了类型的区分,才可以根据不同的类型实施不同的操作。
Python一共有7种基本数据类型,分别是数值型,布尔型,字符串,列表,元组,字典,集合,下面逐一讲解它们的用法。
目录
一,数值型
1.可以同时为多个不同的变量赋不同的值
2.数值型的运算
二,布尔型
1.布尔与--and
2.布尔或--or
3.布尔非--not
三,字符串型
1.字符串索引
2.字符串拼接
3.字符串分割
4.字符串的格式化
四.列表
1.列表的索引
2.一次性从列表中获取多个元素
3.列表拼接
4.添加列表元素
5.删除列表元素
6.列表元素的计数和索引
7.列表的排序与逆序
8.Python的内置函数对列表进行操作
五,元组
六,字典
1.字典的索引通过键key实现
2.获取全部的键/值/键值对
3.给字典中的某个键赋值/增加元素
4.字典的拼接
5.元素的删除
七.集合
1.集合元素的添加/删除
2.集合的特殊操作
一,数值型
数值型包括整型(int),浮点型(float),复数(complex)
注:我们在用Python定义变量时不需要像c,c++等语言声明其数据类型,变量是在赋值时根据‘=’右边的数据类型变成相应的数据类型。

1.可以同时为多个不同的变量赋不同的值

该语句的作用是将3赋值给a,将5.5赋值给b,实际上‘=’左右两边是一个元组,下面我们会提到。
注:对于复数的表示,虚数部分的表示格式是数值‘j’,而不是我们常用的‘i’。
2.数值型的运算

以上算数运算符我们并不陌生,且它们都有对应的赋值运算符(即+=,-=,*=,/=,%=,**=),需要注意的是Python中的两个整数相除并不会像C语言那样取整,而是得到一个浮点数,Python中具有取整功能的是‘//’运算符.

二,布尔型
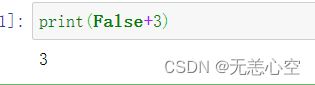
Python中的bool常量有两个,分别是False和True(与C语言中的true和false大小写要区分开),它们分别对应整形数字0和1,所以严格意义上讲布尔类型也是数值型,有下图为证.
Python支持逻辑运算符,如下:
1.布尔与--and
x and y

如果x=False,则返回False,也就是0,我们可以这样考虑,‘与’项如果第一项为假,整个表达式即为假,无需考虑后面的项;如果x=True,则返回y的值。
需要注意的是,任何非0和非null的情况都可以被视为True
2.布尔或--or
x or y

如果x非零,则直接返回x的值,我们可以这样考虑,‘或’式如果第一项为真,整个表达式即为真,所以无需计算第二项的值。如果x为零则返回y的值。
3.布尔非--not
not x
如果x非零则返回False,否则返回True。
除了进行逻辑运算外,我们主要采用布尔值判断由比较运算符(>,<,>=,<=,==,!=等)/逻辑运算符构成的表达式,若表达式为真返回True,表达式为假返回False。
三,字符串型
在Python中没有字符型,只有有一对单引号(' ')或双引号(" ")包括起来的字符串,与这两者不同的是,由三引号(""" """)包括起来的字符串支持换行,但是需要注意由三引号包括的字符串如果没有被赋给某一变量a,则会被当成注释。
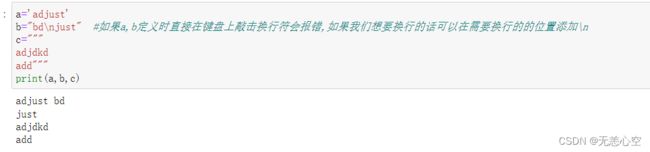
那我们需要考虑一个问题,如果想要定义的字符串本身包含引号怎么办?
下面列出了三种方法:
1.和C语言一样使用\+引号进行转义,但是如果我们想要输出‘\n’这个字符而非换行符的话,可以直接在该字符串之前添加一个r

2.如果字符串中有单引号,我们可以用双引号/三引号进行该字符串的定义
3.同样,如果字符串中有双引号,我们可以使用单引号进行定义
肯定有些同学会想,可不可以使用三引号来将含有双引号的字符串包括进去?下图即为答案。

下面简单演示字符串的运用
1.字符串索引
Python中的字符串同样支持下标索引,但与C语言不同的是,字符串是不可变的 ,一旦某个字符串被赋值,它就会被视为一个常量,即我们虽然可以通过下标索引找到某个字符,但是无法更改它,否则会报错。

字符串中的索引包括正向和负向,其中正向索引从0开始,表示第一个元素,负向索引从-1开始,表示最后一个元素

2.字符串拼接
1.字符串a+字符串b
即可完成字符串的拼接,同样字符串a和 b本身并不会更改,所以我们可以定义一个字符串c来接收他们拼接后的新字符串

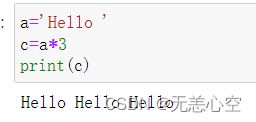
2.字符串a*n
我们很容易想到上述表达式的功能是将字符串a重复n次,然后返回一个新字符串
3.字符串分割
字符串a.split(seq)
该方法的功能是通过指定分隔符seq对字符串进行切片,split()方法返回的是分割后的各个子字符串列表,且该方法同样不会改变字符串本身.

4.字符串的格式化
提到格式化字符串,我们不得不涉及到一个内置函数print(),
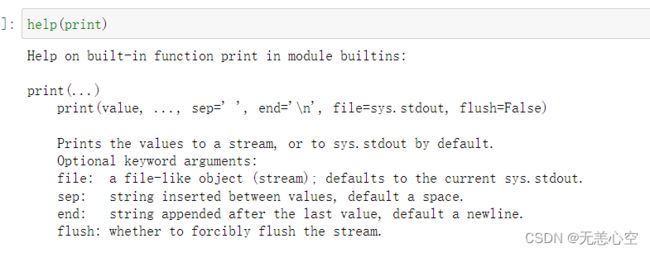
上图是print()函数的官方解释,我们可以用print函数输出多个不同数据的value(其中包括数值型,列表,字符串等等),我们需要将这些参数用(,)连接,参数sep表示输出对象之间的分隔符,默认为空格,当然,我们可以把它改成任意字符(如*,换行等),参数end表示print将所有的value输出完成后输出的最后一个字符,默认为换行,我们同样可以对其默认值进行更改,示例如下.
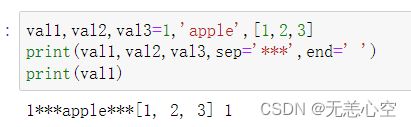
如上图,val1是一个数值型变量,val2是一个字符串型,val3是一个列表,我们在输出这三个对象的时候用字符串‘***’来分割,且输出完成后我们并不输出换行符而是使用一个空格代替,可以看到第一个print与第二个print的输出内容之间确实只有一个空格来分割
下面我们来想一个问题,假设我定义一个数值型变量score记录小明的学习成绩,想输出下面这句话
“本次考试第一名的同学为小明,他的成绩为***”,我们当然不可以直接输出三个*来表示小明的成绩,而是应该输出score对应的数值,那么应该怎样把score‘加入’到这个字符串中呢?
1.使用%占位符
该方法与c/c++语言中printf函数使用的方法类似,如下图
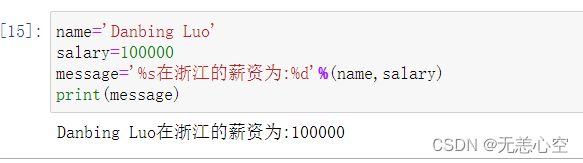
该方法是用%(占位符),表示将后面%的变量变成字符串放到这个地方,但被转换成字符串的变量本身是不变的。当我们给多个变量用%占位时,后面%的后面要紧接上一个()放入变量1,2,3...且它们之间要用(,)连接.
当我们给不同的数据类型占位时,%后面跟着的字母也不同,常用的有%s给字符串占位, %d给整型数据占位,%f给浮点型数据占位...
当我们使用占位符%时,还可以用%m.n控制输出的精度,其中m来控制数据的宽度(当数值本来宽度大于m时,m不起作用),n来控制小数的精度

2.使用format方法进行格式化
该方法主要是通过{ }来代替%进行占位,我们在使用format方法对字符串进行格式化时有两种方式
第一种:参数按位置填入
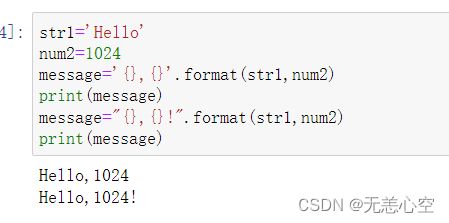
其中.format后面的参数就是我们要格式化输出的变量,我们没有对它进行位置的指定,因此默认按照顺序依次往{ }中填空。
第二种:按指定位置填入

我们默认第一个参数对应的参数索引是0,第二个对应的是1...以此类推。通过这种方法当一个变量多次被放在字符串中输出时,我们不需要重复的进行调用。
值得关注的是,format方法同样可以实现输出格式的控制,如果我们使用第一种方式将字符串格式化,只需要在{ }中填入:+指定输出格式即可,如果我们使用第二种方式,需要在{ }的参数索引后面填入:+指定输出格式
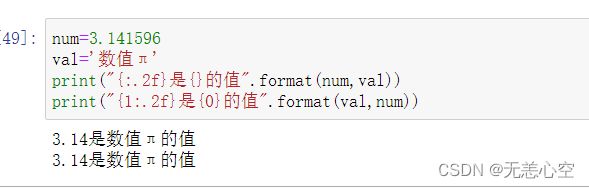
3.快速格式化
该方法的实现如下
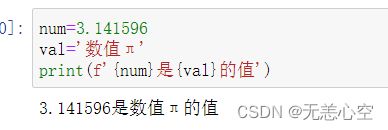
之所以说它快速,我们可以很清晰的感觉到这种方法直接将变量放在{ }中,增强了代码的可读性,但是它的缺点是无法对输出的变量进行精度的控制,所以我们要对以上三种方法斟酌使用。
除了我列举的字符串的内置方法外,有关字符串的处理方法还有很多,可以使用内置函数 dir()来进行查看。

其中常用的还有len(字符串a)求字符串长度,字符串a.lower()返回全部小写的字符串,字符串a.upper()返回全部大写的字符串......
四.列表
列表的创建并不复杂,只要把不同的列表元素用(,)分隔,并整体用([ ])括起来即可。
创建空列表的方法有两种,如下图

1.列表的索引
列表的索引同样可以通过下标实现,与字符串索引相同,列表同样有正向索引和反向索引两种方法。
需要注意的是,列表的元素可以是各个类型的数据,所以我们可以使用嵌套列表

当我们使用了嵌套列表时,可以通过双下标来实现对双层列表的访问

2.一次性从列表中获取多个元素
通过下标索引我们可以得到列表的每个元素,但是如果我们想要一次性从列表中获取多个元素时该怎么办呢?可以利用列表分片来解决。
它的实现为

当[ 起始值:结束值:步长 ]中我们将起始值省略,则默认从下标为0的元素开始,同样,如果将结束值省略,则默认取到最后一个元素终止(包括最后一个元素),(:步长)也可以省略,如果我们的起始值<终止值,则默认步长为1,否则为-1
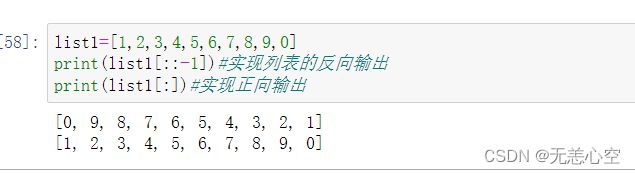
需要注意的是,该方法会生成列表的一个部分副本,而不会操作列表本身
3.列表拼接
和字符串一样,列表的拼接操作也只是需要两个简单的符号(+,*)
该方法同样会产生一个新的列表,对原列表本身没有处理

4.添加列表元素
与字符串不同的一点是,列表本身是可变数据类型,它的内部元素是可以更改的,因此添加列表元素是对该列表本身进行操作。
1.list.append()
该方法是在列表尾部添加一个新元素,添加完成后会改变列表本身

2.list.insert()
该方法是在列表中的指定索引位置插入一个新元素
所以有两个参数,第一个为插入位置的下标,第二个为要插入的元素

3.list.extend()
同样,如果我们觉得一个个插入元素太麻烦,我们可以一次性插入多个元素
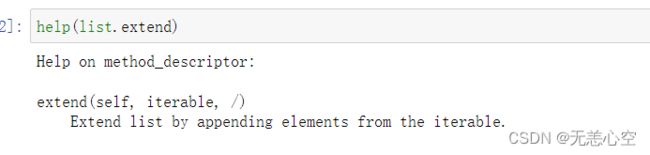
该方法的参数iterable是一个可迭代对象(字符串,元组,列表等),将该参数的元素一个个插入到要插入的列表后面。

5.删除列表元素
与添加列表元素一样,对列表进行删除操作同样会改变列表本身。
1.list.pop()
该方法的参数为要“弹出”的元素下标,如果不指定索引值,则默认为-1,即弹出最后一个元素并返回
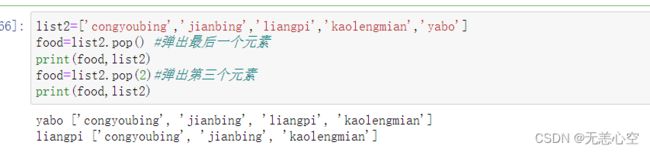
2.list.remove()
该方法的参数为要删除的元素,当列表中有多个重复的该元素时只会删除第一个,且该方法无返回值

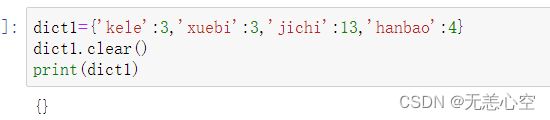
3.list.clear()
该方法会直接清空列表

6.列表元素的计数和索引
1. 与之前的下标索引不同,这次我们是通过元素来找下标,该方法使用list.index()实现

同样,当我们要查找的元素多次在列表中重复出现时,只会返回该元素出现的第一个位置的下标。
2.列表的计数通过list.count()方法实现
该方法的参数是要查找的元素,返回值是它在列表中出现的次数
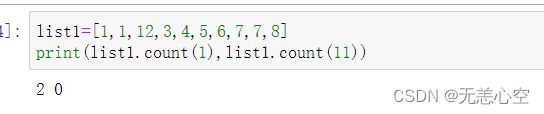
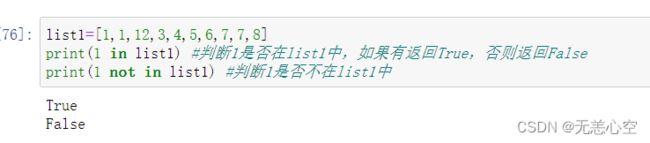
与计数类似的是查找该元素是否在列表中出现过,我们可以简单地用两个表达式来实现
7.列表的排序与逆序
1.列表的排序
对列表的排序有两种方法,一种是列表的内置方法list.sort(),一种是Python的内置函数,下面讲解这两种方法的使用与不同。
1.list.sort()
list.sort(key=None,reverse=False)
该方法的第一个参数key通常为一个指定排序规则的函数(即将列表的元素通过该函数处理得到对应值,并返回一个新序列,实际上是对新序列中的元素进行排序),如果没有给key赋值我们默认对其用数值排序,第二个参数 reverse=False(默认)表示升序,如果想用降序我们可以让reverse=True.

该方法是list的内置方法,如上图所示,列表本身也会变成排序结果
2.sorted()

sorted函数的第一个参数为可迭代对象(列表,元组等),后面的key和reverse同上文的list.sort()方法
与上面方法不同的是,sorted函数是Python的内置函数,不会改变列表本身,而是生成一个列表的副本,然后对副本进行操作。

此外,list.sort()只能给列表使用,而sorted可处理多种可迭代数据类型,后续我们还会讲到。
2.列表的逆序
实现列表的逆序只需要list.reverse()函数即可实现,该操作同样会改变列表本身

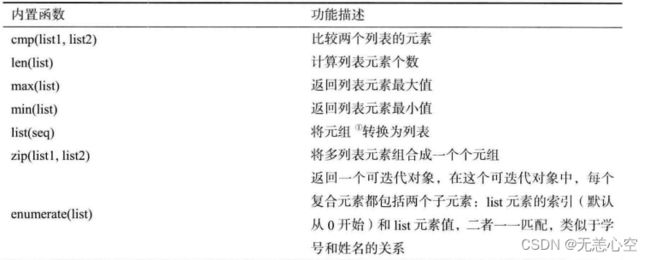
8.Python的内置函数对列表进行操作
除了列表这个数据本身自带的函数,Python的内置函数(可理解为脱离具体对象的全局函数)也可以对列表进行操作,部分函数如下:
1.zip( )
顾名思义,zip()的功能就是将两个可迭代数据类型(列表,元组等)缝合起来形成一个个小元组。
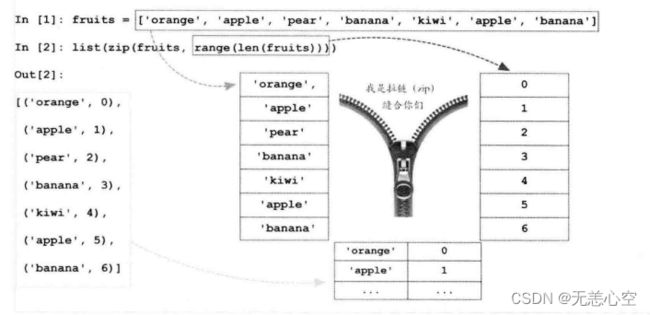
需要说明的是,在缝合过程中,如果两个列表长度不一样怎么办呢?zip( )会根据较短列表的长度实现最大限度的缝合,下面我们用代码进行实现。

其实zip函数可以缝合的不止两个,也可以同时对n个(n>2)个对象(对象类型可不同)进行缝合
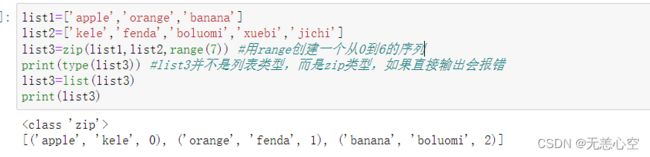
同样,进行缝合时会找出最短长度的可迭代对象,实现最大限度缝合。
2.enumerate( )
enumerate函数用于将可迭代的数据对象形成一个个小元组,元组的第一个元素为下标索引,第二个元素为该数据对象的元素。
enumerate的原型如下:
![]()
iterable表示一个序列或其他可迭代对象,start表示下标起始位置,默认为0,返回的是enumerate(枚举)对象,同样不能直接进行输出。
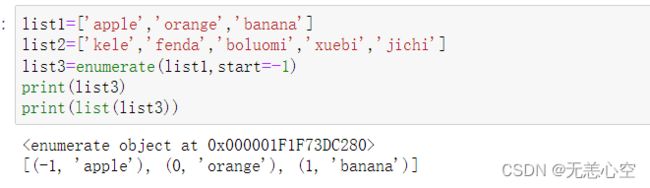
需要注意的是zip函数比enumerate的适用面更广,因为enumerate只能为可迭代对象提供索引封装,而zip函数可实现将多个数据类型进行缝合。
五,元组
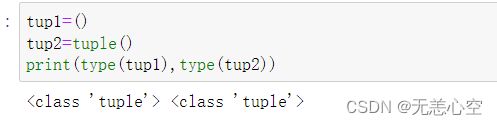
元组被称为“常量版列表”,即元组一经定义无法改变。
元组使用一对()将元素囊括其中,创建元组非常简单,只需在()中添加元素,并用(,)将元素隔开即可。
空元组的创建有两种方法:
需要注意的是,如果元组仅仅包含一个元素,我们需要在定义时在该元素的后面加上一个(,),否则定义出来的就不是元组
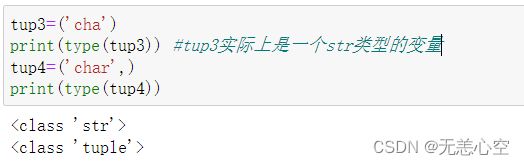
有趣的是,我们在定义有多个元素的元组时,如果去掉包裹他们的()而仅仅保留(,)也可以定义一个元组,因此(,)的对元组来说比()还要重要!
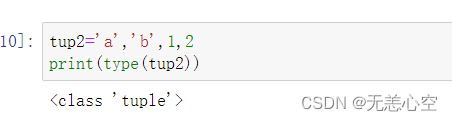
这也就可以解释前面的同时为多个变量赋值,实际上是将(=)后面的元组中元素的值依次赋给(=)前面的元组的元素
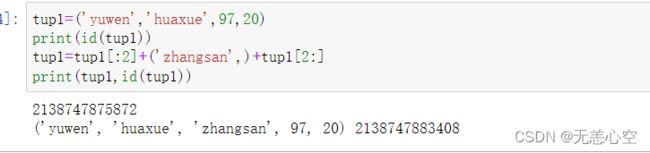
作为列表的孪生兄弟,元组的下标索引,从元组中获取多个元素得到一个新元组等操作与列表是一样的,此处不再赘述。
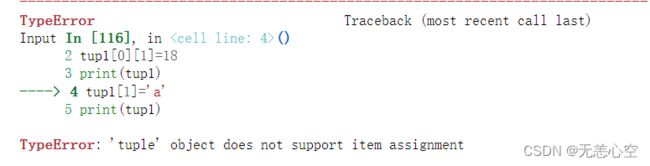
元组内的元素不支持修改,因此没有添加/删除元素等操作。如果想要进行此类操作,只能定义一个新元组去接收它或者将该变量重新赋值
但是有特殊情况,如果元组内的某一元素是可变数据类型(列表,集合等),该元素可以修改,只要保持其类型不变即可

如果我们对元组中的不可变量进行操作就会报错
六,字典
在Python中,字典被视为一种可变类型数字容器,它是由多个键( key)值(value)对构成的,每个键与值之间都用(:)分隔开,不同的键值对之间用(,)分隔开,整个字典包括在一对{ }中。
![]()
字典中的键类似于我们的身份证号码,它必须独一无二,如果我们强行命名相同的键,该键只会更新最后一个赋值,但值value不必受此约束,可同可不同。

除了命名不可以重复,键的类型必须是不可更改的元素(不可以是列表,字典,集合等),而值的类型不受限制。
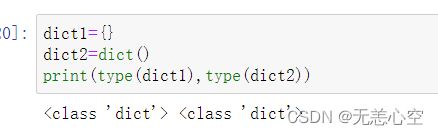
空字典的定义同样有两种方法,如下
1.字典的索引通过键key实现
1.dict[key]
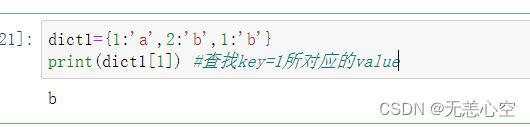
2.dict.get( )
我们也可以使用get方法提取定键对应的值,如果该键不在字典中,就返回默认值,否则返回该键所对应的值,该方法的函数原型如下:
![]()
其中default=None表示如果该键不在字典中,就返回默认值None,当然我们在调用dict.get()函数时可以进行传参修改该默认值。

2.获取全部的键/值/键值对
dict.items()函数可获取该字典中全部的键值对并分装在小元组中,
dict.keys()函数可获取该字典中全部的键
dict.values()函数可获取该字典中全部的值
以上三种函数在字典的遍历中会经常使用

3.给字典中的某个键赋值/增加元素
我们同样使用键索引对其所对应的值进行更改

需要注意的是,如果该键不存在,则相当于我们填入了一个新的键值对。

4.字典的拼接
通过dict1.update(dict2)将dict2中的元素更新到dict1中

5.元素的删除
1.dict.pop()函数
这个函数是不是看着很眼熟,没错,列表中元素的删除同样有一个pop函数,但他们之间的不同是列表接收的参数是元素下标,如果没有接收参数则默认弹出最后一个元素,而字典接收的是键,且没有默认值,如果我们不进行传参则会报错,如果传入的键不在该字典中也会报错
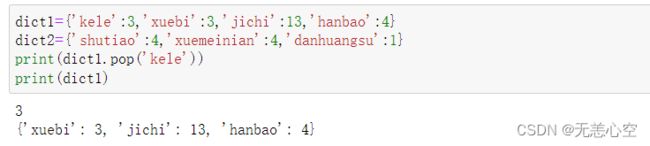
2.dict.popitem( )
上个pop函数是不是提到必须传入一个指定的键,其实也可以使用匿名弹出的方法dict.popitem( )函数,该函数按照栈的数据结构,会弹出进入字典的最后一个键值对

七.集合
与其他编程语言类似,集合是一个无序的元素集,因为它的无序,所以我们无法通过下标/键来访问集合中的元素。
在形式上,集合的所有元素与字典类似,元素之间由(,)分隔,且所有元素用{ }包括起来。
集合的原型为![]()
空集合的定义:
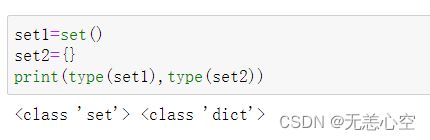
如上,因为{ }已经被空字典的定义占用,空集合只能有一种定义方式。
集合中的所有元素都是唯一的,即使我们强制元素重复,集合本身也会进行去重操作

利用这个特性,我们可以通过将其他数据类型转换为集合进行去重处理
1.集合元素的添加/删除
由于集合本身是一个可变数据类型,我们可以对其进行元素的增删操作
元素添加:set.add( )
该函数的参数是要添加的元素,代码实现如下

元素删除:
1.set.remove( )
该函数的参数是要删除的元素, 如果该元素不在集合内则会报错,代码实现如下
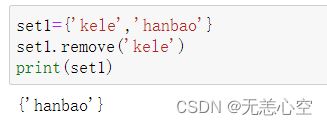
2.set.pop( )
该函数没有参数,它的功能是随机弹出集合中的某一个元素

与清空列表类似,如果我们想清空集合,只需使用set.clear( )函数即可

你可能会有些奇怪,为什么前面清空列表返回的是一个[ ],而清空集合返回的是set( ),而不是集合的对应符号{ },实际上也是因为 { }已经被字典所占用,下图为证
2.集合的特殊操作
与我们所学习的数学知识一样,Python同样可以对集合进行求并集/交集/差集等操作,这些操作都会返回一个新的集合,而对原集合本身没有影响
求并集:
1.set1.union(set2)
2.set1|set2

求交集:
1.set1.intersection(set2)
2.set1&set2

同样还可以进行消除交集的操作
set1.difference_update(set2)
需要注意的是,该操作会直接在set1集合中进行删除

求差集:
1.set1.difference(set2)
2.set1-set2

求对称差集:
1.set1.symmetric_difference(set2)
2.set1^set2
