python语言基础(五)基础数据类型和字符串
python基础数据类型
比如玩游戏的时候,有玩家的名称、人物属性(字符串),装备(字符串)放到盒子(列表)里存储,买装备用到金币(数值,浮点数)等会用到很多数据类型,用数据类型可以更好分配管理内存(人物名称和金币消耗的内存不一样,分开管理,更好的分配内存)、方便统一管理(对所有的字符串进行操作)、更贴近人类分类管理习惯。目的:方便对数据进行存储和读取。
数据类型的种类:
1、内置的(自带的),不需要安装就可以直接使用
数值类型: int(整数),bool(布尔型,True,False),float(浮点数),complex(复数)
序列类型: 不可变的 str(字符串)、tuple(元组)、bytes(字节),字典的key值不可变;可变的list(列表)
集合类型: set(集合)(添加的值是不可变)
映射类型: dict(字典)
2、自定义的,自己去定义的数据类型
数值类型
包括int(整数),bool(布尔型,True,False),float(浮点数),complex(复数)。
数值类型介绍(熟悉)
数值类型是 不可变 类型。所谓的不可变类型,指的是类型的值一旦有改变了,那么它就是一个全新的对象。数字1和2分别代表两个不同的对象,对变量重新赋值一个数字类型,会新建一个数字对象。
Python 的变量和数据类型的关系,变量是容器,只是对某个对象的引用或者说代号、名字、调用等等,变量本身没有数据类型的概念,我们把数据赋值给变量,而通过变量使用数据 。只有1,[1,2],"hello"这一类对象才具有数据类型的概念。
Python 支持三种不同的数值类型:整数、浮点数和复数与布尔。
整数(int)介绍(熟悉)
整数通常被称为整型,数值为正或者负,不带小数点。表示数字的时候,通常使用十进制(decimal) 来表示。
有时我们还会用八进制或十六进制来表示(了解):
- 十六进制用0x前缀和0-9,a-f表示,例如:0xff00。python 中使用 hex() 将十进制转为十六进制
- 八进制用0o前缀和0-7表示,例如0o45。python 中使用 oct() 将十进制转为八进制
- 二进制用0b前缀和0-1表示,例如0b11。python 中使用 bin() 将十进制转为二进制
整数内存(了解)
python 的整数长度为32位,并且通常是连续分配内存空间的。
从下面代码的内存地址看,1和2之间的内存地址正好相差32。
In [1]: id(1)
Out[1]: 1628405872
In [2]: id(2)
Out[2]: 1628405904
数值是不可变的数据类型,如果改变它的值,相当于重新开辟了一块内存区域去存储,可能1和2会使用无限多次,每一次都开辟新区域,都会消耗不必要的内存。可以用赋值去解决,a=1,反复去调用a,python对常用的数值建立特定的内存来存储,每次用的时候直接去调用就可以了,就引申到小整数对象池。
小整数对象池(了解)
很多数据类型都有自己的池子,为了节省内存消耗,都开辟的有特有的内存区域
python 初始化的时候会自动建立一个小整数对象池,方便我们调用,避免后期重复生成!这是一个包含262个指向整数对象的指针数组,范围是-5到256。也就是说比如整数10,即使我们在程序里没有创建它,其实在 Python 后台已经悄悄为我们创建了。
作用:节省开销,增快运行速度,对象池内里面的数值,本身的内存地址是已经创建好的,每次访问的时候直接调用就可以了
In [3]: id(-4)
Out[3]: 1628405712
In [4]: id(-5)
Out[4]: 1628405680
In [5]: id(255)
Out[5]: 1628414000
In [6]: id(256)
Out[6]: 1628414032
In [7]: id(257)
Out[7]: 3175345206288
In [8]: id(-6)
Out[8]: 3175345205744
可以看一下,在-5到256之间的内存分配地址格式一致,但是超过了小整数对象池比如-6,257的内存分配地址跟范围内的就不一样了。
整数缓冲区(了解)
除了小整数对象池,Python 还有整数缓冲区的概念,也就是刚被删除的整数,不会被真正立刻删除回收,而是在后台缓冲一段时间,等待下一次的可能调用。看是否有相同的调用,如果有就直接调用,没有的话就销毁。
a = 100000
print(id(a))
del a
b = 100000
print(id(b))
3028842491600
3028842491600
注意:在ipython交互环境当中演示不出来效果,没有缓冲区的概念。该效果在pycharm当中实现;并且注意不是小整数对象池当中的值。
浮点数(float)介绍(熟悉)
浮点数也就是小数,如1.23,3.14,-9.01等等。但是对于很大或很小的浮点数,一般用科学计数法表示,把10用e替代,1.23x10^9就是1.23e9,或者
12.3e8,0.000012可以写成1.2e-5,等等。在数据分析的学习见的比较多。
浮点数与整数之间转换(掌握)
在ipython交互环境下,输入 help(float)、 help(int)可以查看float类、int类的使用方法
int 转为 float: float(x) -> floating point number;a=1 -->float(a) -->1.0
float 转为int int(x=0) -> integer,只取整数部分,不进行四舍五入
a=12.7 -->int(a) -->12
复数(complex)(了解)
复数由 实数部分 和 虚数部分 构成,可以用 a + bj, 或者 complex(a,b) 表示,复数的 实部a 和 虚部b 都是浮点。
数学计算(熟悉)
对于数学计算,除了前面提到过的简单的加减乘除等等,更多的科学计算需要导入 math 这个标准库,它包含了绝大多数我们可能需要的科学计算函数。常用的几个需要记住。
import math
math.ceil(x) —>向上取整,print(math.ceil(4)) —>5
math.floor(x) —>向下取整,print(math.floor(4.5)) —>4
math.pow(x) —>取幂次,print(math.pow(2,3)) —>8.0
内置的,直接使用
abs(x) —>取绝对值,print(abs(-10)) —>10
round(x) —>四舍五入函数,python3进行了改良执行的是四舍六入五成偶
print(round(4.1)) —>4
print(round(4.5)) —>4,按四舍五入的话会加1成5,5是奇数,就不加1,加完后为偶数的才会加1,只有.5会出现,如果4.7就会进1变为5
print(round(4.6)) —>5
print(round(3.5)) —>4,加完后为4,4为偶数,所以结果就会加1,变为4
ceil(x) 返回数字的上入整数,如math.ceil(4.1) 返回 5
exp(x) 返回e的x次幂(ex),如math.exp(1) 返回2.718281828459045
fabs(x) 返回数字的绝对值,如math.fabs(-10) 返回10.0
floor(x) 返回数字的下舍整数,如math.floor(4.9)返回 4
log(x) 如math.log(math.e)返回1.0,math.log(100,10)返回2.0
log10(x) 返回以10为基数的x的对数,如math.log10(100)返回 2.0
modf(x) 返回x的整数部分与小数部分,两部分的数值符号与x相同,整数部分以浮点型表示。
pow(x, y) x**y 运算后的值。
sqrt(x) 返回数字x的平方根
acos(x) 返回x的反余弦弧度值。
asin(x) 返回x的反正弦弧度值。
atan(x) 返回x的反正切弧度值。
atan2(y, x) 返回给定的 X 及 Y 坐标值的反正切值。
cos(x) 返回x的弧度的余弦值。
hypot(x, y) 返回欧几里德范数 sqrt(xx + yy)
sin(x) 返回的x弧度的正弦值。
tan(x) 返回x弧度的正切值。
degrees(x) 将弧度转换为角度,如degrees(math.pi/2) , 返回90.0
radians(x) 将角度转换为弧度
布尔类型
布尔类型介绍(掌握)
比如我们抛硬币,不是正面就是反面。那其实对于对与错、0与1,都是传统意义上的布尔类型。
但在Python语言中,布尔类型只有两个值,True 与 False。
注意:首字母必须大写,不能有其它的花式变型
布尔类型
bool()使用
我们通过 python 内置的 bool() 函数来测试一个表达式的布尔值的结果。用的比较多的就是条件判断
print(2>3) --> False;print(2<3) --> True;print(3 in [1,2,3]) --> True
print(3 == 9/3) --> True;print(3 is 3.0) --> False(is比较的是内存地址)
print(bool(True)) --> True;print(bool(False)) --> False
print(bool(-1)) --> True;print(bool(0.0)) --> False
print(bool("")) --> False;print(bool(" ")) --> True;print(bool(“0”)) --> True
print(bool([])) --> False;print(bool([1,2,3])) --> True
print(bool(None)) --> False
归纳:
- 数值类型:0、0.0的 bool 值都为 False,其它的都为 True
- 字符串:空字符串的 bool 值为 False,其它的都为 True。注意空格字符串为 True
- 列表:空列表的 bool 值为False,其它的都为 True。
- None 的 bool 值永远为 False
布尔类型运算
布尔类型运算如下:
- and 运算,两者都为真,结果为真
- or 运算,其中一个为真,结果即为真
- not 运算,取反运算
- 算术运算,注意:把 True 看作1,而 False 看作 0
print(True +1) --> 2;print(False +1)) --> 1
空值
空值介绍(掌握)
空值不是布尔类型,是 Python 里一个特殊的值,用 None 表示(首字母大写)。None 不能理解为0,因为0是整数类型,而 None 是一个特殊的值。None 也不是布尔类型,而是 NoneType。一般用于返回值,return None
print(type(None)) --> NoneType
print(None == 0) --> False;print(None == “”) --> False;print(None == []) --> False
字符串(str)(重点内容)
字符串介绍(掌握)
字符串是 Python 中最常用的数据类型之一,编程语言中表示文本的数据类型,使用成对的单引号或双引号来创建字符串,使用三引号创建多行字符串。
用成对的单引号或双引号创建字符串的时候,如果需要输出的时候换行,可以输入“\n”,如果需要打印“\n”这个符号,则输入“\\n”;三引号是文本格式,保留了文本的样式(回车,tab等),如果需要换行输出,直接敲回车就可以了,通常用于文本输出。
hello_str = "hello world"
hello_str1 = 'hello python'
s = '小明说:"你好"' # 外面是单引号,里面引用的时候用双引号
s = "小明说:'你好'"
s = '小明说:\'你好\'' # '与最近的另一个'匹配,所有要用专业字符,直接输出',并没有执行'的意义
print(hello_str[:5]) # hello
注意:
- 字符串的单引号与双引号都是成对出现的,不能一边单一边双。
- 字符串是 不可变 的 序列数据类型,不能直接修改字符串本身,和数字类型一样!
- 可以使用索引获取一个字符串中指定位置的字符,索引计数从0开始
- 也可以使用for循环遍历字符串中每一个字符
字符串的存储(了解)
思考:以下 数值 与 字符串 存储是一样的吗?
CPU:处理数据,速度比较快,存储小
硬盘:存储数据量大,存储比较大,速度慢
如果CPU直接去硬盘拿数据的话会比较慢,影响运行的速度,这时候就需要内存了。
内存:速度比CPU慢,但比硬盘快。存储比CPU大,但比硬盘小。
完美解决了速度与存储的问题。4G、8G、16G、128G等
1G = 1024M;1M = 1024KB;1KB = 1024B;1B = 8bi
整数在内存中占一个字节,字符串不管中间多少内容都要单独存储。字符串是序列的,跟链子一样,是有序的。
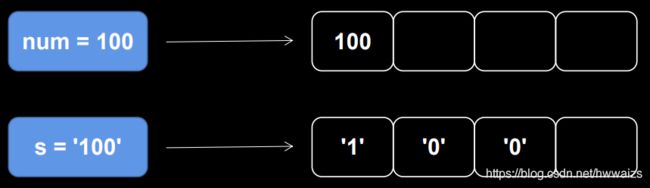
字符串的下标(重点掌握)
由于字符串是 序列数据结构 ,所以我们可以通过下标将字符串中某个字母取出来。下标也可称为 索引,默认从0开始。
思考:name =“hello oldamy”,如何取出 e 值?如何取出最后一个值

print(name[1]) --> “e”;print(name[11]) --> “y”;print(name[-1]) --> “y”
- 超出范围会报错,print(name[12]) --> “IndexError:string index out of range”
- 字符串不支持修改,name[3]=“L” -->TypeError: ‘str’ object does not support item assignment
字符串的切片(重点掌握)
切片方法适用于字符串、列表、元组
切片 使用 索引值 来限定范围,从一个大的 字符串 中 切出 小的 字符串
列表 和 元组 都是 有序 的集合,都能够 通过索引值 获取到对应的数据
字典 是一个 无序 的集合,是使用 键值对 保存数据。
slice(start, stop[, step])

思考:
name =“hello oldamy”,如何取出 oldamy , hloodm 值?name 逆序输出?

print(name[6:12]) --> “oldamy”,[]是左闭右开的;print(name[6:]) --> "oldamy"步长不写,默认为1;结束位置不写,默认为取到最后一位;起始位置和结束位置都不写,取得是字符串的全部。
print(name[::2]) --> “hloodm”;print(name[::-1]) --> 字符串的逆序输出
注意:
- 索引默认从0开始,从头开始,开始索引数字可以省略,冒号不能省略。
- 切片时左闭右开,到末尾结束,结束索引数字可以省略,冒号不能省略,步长默认为1,如果连续切片,数字和冒号都可以省略。
- 当是取单个字符的时候,索引超出范围会报错。而切片时不会报错。
- 步长不能为0,也不允许为浮点数
num_str = "0123456789"
# 1. 截取从 2 ~ 5 位置 的字符串
print(num_str[2:6])
# 2. 截取从 2 ~ `末尾` 的字符串
print(num_str[2:])
# 3. 截取从 `开始` ~ 5 位置 的字符串
print(num_str[:6])
# 4. 截取完整的字符串
print(num_str[:])
# 5. 从开始位置,每隔一个字符截取字符串
print(num_str[::2])
# 6. 从索引 1 开始,每隔一个取一个
print(num_str[1::2])
# 倒序切片
# -1 表示倒数第一个字符
print(num_str[-1])
# 7. 截取从 2 ~ `末尾 - 1` 的字符串
print(num_str[2:-1])
# 8. 截取字符串末尾两个字符
print(num_str[-2:])
# 9. 字符串的逆序(面试题)
print(num_str[::-1])
字符串类型转换(掌握)
str 转为 int
int(x) --> integer
int(“1”) -->1;int(“a”)–>报错,不是十进制;int(1.0) -->1;int(“1.0”) -->报错,不能识别1.0中的符号
int 转为str
str(object=’’) --> str
str(1) -->“1”
字符串组成方式(掌握)
- 字符串相加,print(“1”+“2”) --> “12”;字符串用"+"做拼接
- 字符串格式化
- %s %d %f,以%占坑
%s --> str;%d --> digit(decimal);%f --> float;需要考虑数据类型 - str.format(),以{}占坑,不用考虑数据类型,可以切换数据位置
- python3.6.4 引入 f’’,以{}占坑,不用考虑数据类型
栗子:
name = ‘hansen’, age = 20, 输出 ** 的年龄为 **
- %s %d %f,以%占坑
name = 'hansen'
age = 20
print(name+"的年龄为"+str(age))
print("%s的年龄为%d" % (name, age))
print("{}的年龄为{}".format(name, age))
print("{1}的年龄为{0}".format(age, name))
print(f"{name}的年龄为{age}")
- 作业1
当输入y或Y打印进入卸载,当输入n或N打印退出程序,
输入其它则打印输入不在选项范围之内
str1 = input("请输入(Y/y)or(N/n):")
# 第一种
if str1 == "Y" or str1 == "y":
print("进入卸载")
elif str1 == "N" or str1 == "n":
print("退出程序")
else:
print("输入不在选项范围之内")
# 第二种
if str1 in ["Y", "y"]:
print("进入卸载")
elif str1 in ["N", "n"]:
print("退出程序")
else:
print("输入不在选项范围之内")
# 第三种
if str1.lower() == "y":
print("进入卸载")
elif str1.upper() == "N":
print("退出程序")
else:
print("输入不在选项范围之内")
- 作业2.完成字符串的逆序以及统计
设计一个程序,要求只能输入长度低于20的字符串,当满足需求时,则打印出字符串长度以及使用切片逆序打印出字符串当不满足需求时,打印用户重新输入。
str1 = input("请输入长度低于20的字符串:")
if len(str1) < 20:
print(f"用户输入字符串的长度是:{len(str1)}")
print(f"字符串的逆序打印为:{str1[::-1]}")
else:
print("请重新输入")
- 作业3
’3’+’4’的结果是什么?
print("3"+"4") # --> 34
字符串常见操作(熟悉)
判断类型 --> 9
查找和替换 -->7
大小写转换 -->5
文本对齐 -->3
去除空白字符 -->3
拆分和链接 -->5
| 操作类型 | 说明 | 说明 |
|---|---|---|
| 判断 | string.isspace() | 如果 string 中只包含空格,则返回 True。str1 = " \r\n\t" print(str1.isspace()) |
| 判断 | string.isalnum() | 如果 string 至少有一个字符并且所有字符都是字母或数字则返回 True |
| 判断 | string.isalpha() | 如果 string 至少有一个字符并且所有字符都是字母则返回 True |
| 判断 | string.isdecimal() | 如果 string 只包含数字则返回 True,全角数字,不能小数 |
| 判断 | string.isdigit() | 如果 string 只包含数字则返回 True,全角数字、⑴、\u00b2 ,不能小数 |
| 判断 | string.isnumeric() | 如果 string 只包含数字则返回 True,全角数字,汉字数字 ,不能小数 |
| 判断 | string.istitle() | 如果 string 是标题化的(每个单词的首字母大写)则返回 True |
| 判断 | string.islower() | 如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True |
| 判断 | string.isupper() | 如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True |
| 查找和替换 | string.startswith(str) | 检查字符串是否是以 str 开头,是则返回 True |
| 查找和替换 | string.endswith(str) | 检查字符串是否是以 str 结束,是则返回 True |
| 查找和替换 | string.find(str, start=0, end=len(string)) | 检测 str 是否包含在 string 中,如果 start 和 end 指定范围,则检查是否包含在指定范围内,如果是,返回开始的索引值,否则返回 -1 |
| 查找和替换 | string.rfind(str, start=0, end=len(string)) | 类似于 find(),不过是从右边开始查找 |
| 查找和替换 | string.index(str, start=0, end=len(string)) | 跟 find() 方法类似,不过如果 str 不在 string 会报错 |
| 查找和替换 | string.rindex(str, start=0, end=len(string)) | 类似于 index(),不过是从右边开始 |
| 查找和替换 | string.replace(old_str, new_str, num=string.count(old)) | 把 string 中的 old_str 替换成 new_str,如果 num 指定,则替换不超过 num 次 ,执行后返回一个新的内容 |
| 大小写转换 | string.capitalize() | 把字符串的第一个字符大写 |
| 大小写转换 | string.title() | 把字符串的每个单词首字母大写 |
| 大小写转换 | string.lower() | 转换 string 中所有大写字符为小写 |
| 大小写转换 | string.upper() | 转换 string 中的小写字母为大写 |
| 大小写转换 | string.swapcase() | 翻转 string 中的大小写 |
| 文本对齐 | string.ljust(width) | 返回一个原字符串左对齐,并使用空格填充至长度 width 的新字符串 |
| 文本对齐 | string.rjust(width) | 返回一个原字符串右对齐,并使用空格填充至长度 width 的新字符串 |
| 文本对齐 | string.center(width) | 返回一个原字符串居中,并使用空格填充至长度 width 的新字符串,第一个参数是宽度,第二个参数是填充的字符 |
| 去除空白字符 | string.lstrip() | 截掉 string 左边(开始)的空白字符 |
| 去除空白字符 | string.rstrip() | 截掉 string 右边(末尾)的空白字符 |
| 去除空白字符 | string.strip() | 截掉 string 左右两边的空白字符,也可以用replace替换所有空白字符 |
| 拆分和连接 | string.partition(str) | 把字符串 string 分成一个 3 元素的元组 (str前面, str, str后面) |
| 拆分和连接 | string.rpartition(str) | 类似于 partition() 方法,不过是从右边开始查找 |
| 拆分和连接 | string.split(str="", num) | 以 str 为分隔符拆分 string,如果 num 有指定值,则仅分隔 num + 1 个子字符串,str 默认包含 ‘’, ‘\t’, ‘\n’ 和空格,hello以l分割,结果为[“he”," ",“o”] |
| 拆分和连接 | string.splitlines() | 按照行(’’, ‘\n’, ‘\n’)分隔,返回一个包含各行作为元素的列表 |
| 拆分和连接 | string.join(seq) | 以 string 作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串 |
字符串的统计操作,列表,字典,元组中都可以用
- S.len() -->统计字符串的长度
- S.count() -->统计子字符串在大字符串中出现的次数
- S.index() -->统计子字符串在大字符串中的索引值
s = "hello world"
# 统计字符串的长度
print(len(s)) # 11
# 统计子字符串在大字符串中出现的次数
print(s.count("llo")) # 1
print(s.count("l")) # 3
print(s.count("abc")) # 0
# 统计出子字符串在大字符串中的索引值
print(s.index('llo')) # 返回的索引值2,'llo'是一个整体,只统计第一个字符出现的位置
print(s.index('abc')) # 报错
- S.find(sub) --> 返回该元素最小的索引
- S.index(sub) --> 返回该元素最小的索引
索引值是整型(int)
s1 = "hello python"
print(s1.find("e")) # 1 返回最小的索引,第一次出现的
print(s1.find("o")) # 4 因为最小,返回第一个“o”
print(s1.rfind("o")) # 10 返回右边的那个“o”
print(s1.find("c")) # s1中没有"c"时,不会报错,返回-1
print(s1.index("c")) # index与find作用一模一样,但是区别在于,当通过S.index查询不存在的子串时,会报错,而S.find()返回-1
- S.replace(old, new[, count]) --> 替换
s2 = "hello oldoldstudent"
# old-->beautiful
print(s2.replace("old", "beautiful")) # -->"hello beautifulbeautifulstudent" 默认:全部替换
print(s2.replace("old", "beautiful", 1)) # -->"hello beautifuloldstudent" 默认从第1个开始替换,count:指定替换次数
print(s2.replace("dold", "dbeautiful")) # -->"hello oldbeautifulstudent" 替换第二个old,再前面多加一个字符
print(s2) # -->"hello oldoldstudent", copy of S,意味着没有改变s2本身
- S.split(sep=None) --> 以sep来分割字符串,并返回列表。sep默认为None,分割默认为空格
s3 = "hello everybody yeyeye!"
# 以空格将三个单词进行拆分为列表的元素
print(s3.split(" ")) # -->['hello','everybody','yeyeye!'] 以空格字符串进行分割,那空格字符串消失,返回为列表
print(type(s3.split(" "))) # - S.startswith(prefix[, start[, end]]) --> 判断字符串是否以前缀开始,返回为bool值。
- S.endswith(suffix[, start[, end]]) --> 判断字符串是否以尾缀结束,返回为bool值。
s4 = "hello everybody yeyeye!"
print(s4.startswith("he")) # True,用于判断字符串以什么前缀开始,返回为bool
print(s4.endswith("ye!")) # True 判断以什么尾椎结束的,如.png,.docx进行判断归类
- S.lower() --> 将字符串全部转为小写
- S.upper() --> 将字符串全部转为大写
s5 = "n"
print(s5.upper()) # N
s6 = "Y"
print(s6.lower()) # y
print(s5.upper().lower()) # n
- S.strip([chars]) --> 默认去掉字符串左右的空格
s7 = " 一代 明君 "
print(s7.strip()) # -->"一代 明君",去除首部以及尾部的空格
print(s7.replace(" ", "")) # -->"一代明君"去除中间空格及所有的空格
- S.isalpha() --> 判断字符串是否全为字母,返回的是bool值
- S.isdigit() --> 判断字符串是否全为数字,返回的是bool值
- S.isalnum() --> 判断字符串是否全为数字或者字母,不存在特殊字符,返回的是bool值
- S.join(iterable) --> 将序列中的元素以指定的字符连接生成一个新的字符串
字符串是序列类型 -->可以一个一个的取出元素 -->可以迭代的(iterable)
s8 = "你好某某同学bababalalallaal"
print(" ".join(s8)) # --> 你 好 某 某 同 学 b a b a b a l a l a l l a a l
li = ["你好","世界"]
print(" ".join(li)) # --> 你好 世界
字节(bytes)
字节介绍(掌握)
在 Python3 以后,字符串 和 bytes 类型彻底分开了。字符串 是以 字符 为单位进行处理的,bytes 类型是以 字节 为单位处理的。
bytes 数据类型在所有的操作和使用甚至内置方法上和字符串数据类型基本一样,也是不可变的序列对象。爬虫获取的图片等信息都是字节。
Python3 中,bytes 通常用于网络数据传输、二进制图片和文件的保存等等。
字节创建(掌握)可以通过调用 bytes() 生成 bytes 实例,其值形式为 b’xxxxx’
,对于同一个字符串如果采用不同的编码方式生成 bytes 对象,就会形成不同的值。
字节创建(掌握)
可以通过调用 bytes() 生成 bytes 实例,其值形式为 b’xxxxx’,对于同一个字符串如果采用不同的编码方式生成 bytes 对象,就会形成不同的值。
# 创建字节:b""
bt_1 = b'hello'
print(type(bt_1)) # 字节与字符串转换
有时候获取的数据是乱码,是因为读取的是字节,没有进行字符串的转换。
bytes 转为 str
bt_1 = b"world"
print(type(bt_1)) # hello
** str 转为 bytes**
s_2 = "world"
# 将 字符串 转为 字节 --> 编码
bt_2 = s_2.encode()
print(bt_2) # b'world'
print(bt_2[0]) # 119 ,取出的是ascii