【C进阶】——详解10个C语言中常见的字符串操作函数及其模拟实现
这篇文章给大家介绍一些C语言中处理字符串的 库函数 以及它们的使用和注意事项,一起来学习吧!!!
本篇文章介绍的函数需要包含的头文件都是#include
文章目录
-
- 前言
- 1.求字符串长度——strlen
-
- 1.1 使用及注意事项
- 1.2 strlen的模拟实现
- 2.字符串拷贝——strcpy
-
- 2.1 使用及注意事项
- 2.2 strcpy的模拟实现
- 3.字符串追加函数——strcat
-
- 3.1使用及注意事项
- 3.2 strcat的模拟实现
- 3.3思考
- 4.字符串比较函数——strcmp
-
- 4.1使用及注意事项
- 4.2strcmp 的模拟实现
- 5.小结
- 6. strncpy
-
- 6.1 与strcpy对比
- 6.2 使用及注意事项
- 6.3 strncpy的模拟实现
- 7. strncat
-
- 7.1与strcat对比
- 7.2使用及注意事项
- 7.3上述3.3思考解答
- 7.4 strncat的模拟实现
- 8. strncmp
-
- 8.1 使用练习
- 8.2 strncmp的模拟实现
- 9.字符串查找函数——strstr
-
- 9.1使用及注意事项
- 9.2strstr的模拟实现
- 10. strtok
-
- 10.1功能解释及使用说明
- 10.2 代码演示及优化
- 11. strerror
-
- 11.1功能解释及使用说明
- 11.2 应用场景
前言
C语言中对字符和字符串的处理很是频繁,但是C语言本身是没有字符串类型的,字符串通常放在 常量字符串 中或者 字符数组 中。
字符串常量 适用于那些对它不做修改的字符串函数.
1.求字符串长度——strlen
strlen是库函数,我们要知道库函数的参数和它的功能是C语言标准规定好的,那我们怎么看它的参数是什么呢?
之前的文章里给大家提到过一个查询库函数的网站(cplusplus.com):
链接: link
那我们来看一下C语言标准规定strlen的参数和功能是怎么样的的:

1.1 使用及注意事项
相信这个函数大家以及比较熟悉了,但这里还是带大家一起来复习一下,并强调一些注意事项:
-
字符串以 ‘\0’ 作为结束标志,strlen函数返回的是在字符串中 ‘\0’ 前面出现的字符个数(不包含 ‘\0’ )。
举个例子:
#include 看下结果:

字符’\0’之前有6个字符,所以结果是6,相信大家都能明白。
-
参数指向的字符串必须要以 ‘\0’ 结束。
我们知道字符串的结束标志是’\0’,那如果一个字符串中没有’\0’,还能用strlen计算它的长度吗?
int main()
{
char arr[] = { 'a','b','c','d','e','f' };
char arr2[] = { 'a','b','f'};
printf("%d\n", strlen(arr));
printf("%d\n", strlen(arr2));
return 0;
}
大家思考一下结果会是什么?

19和31,为什么会是这个结果,是巧合吗?我们再运行一次:

又一个不同的结果,为啥呢?
因为如果我们不加’\0’,去求一个没有结束标志的字符串,它的结果将会是一个随机值,为什么呢?
因为函数strlen 求的是字符串中’\0’之前的字符个数,但是上面的两个字符串(C语言没有字符串类型,我们放到了字符数组中)中没有’\0’,所以strlen函数就会一直向后寻找,直至遇到’\0’,但数组后面的内存空间放的是什么我们是不知道的,所以我们不知道什么时候会遇到’\0’,因此结果是一个随机值。
-
注意函数的返回值为size_t,是无符号的( 易错 )
大家可能不是太明白,我们来先看一段代码:
#include 大家思考一下结果是啥?
str1的长度为6,str2的长度为3,所以
strlen(str2)-strlen(str1)的结果是-3,小于0,if判断为假,所以打印"srt1>str2"
如果你是这样想的那就错了!!!
我们来看一下结果是啥?

结果是str2>str1,与我们想的不一样,原因就在于函数strlen的返回值为size_t。
解释:

不知道大家有没有注意到,库函数strlen的返回类型是size_t。
那什么是size_t呢?我们来看一下:
怎么看,在vs2022中输入一个size_t,鼠标右键转到定义或直接按F12即可查看:
我们看到,size_t其实就是unsigend int (无符号整型),因为typedef unsigned int size_t的意思其实就是把类型unsigned int 重命名为 size_t。
由于strlen的返回类型是size_t,所以strlen(str2)-strlen(str1)的结果就也是size_t了。
那么3-6=-3,我们知道内存中存的是补码:
那如果11111111111111111111111111111101被当作一个无符号整型,转化为10进制将是一个非常大的正数,肯定大于0,所以结果才是str2>str1。



1.2 strlen的模拟实现
那我们现在已经知道了函数strlen的参数以及它的功能,我们是不是可以尝试去模拟实现一下strlen呢?

这里我们介绍三种方法去模拟实现strlen:
- 计数器方式
怎么实现呢?
把字符串的首字符地址传给函数,用指针接收,用该指针遍历字符串,如果指针指向的内容不是’\0’,计数器++,指针继续向后移动,直至遇到’\0’停止,返回计数器的值。
size_t my_strlen(const char* str)
{
int count = 0;
while (*str)
{
count++;
str++;
}
return count;
}
看一下能不能达到效果:

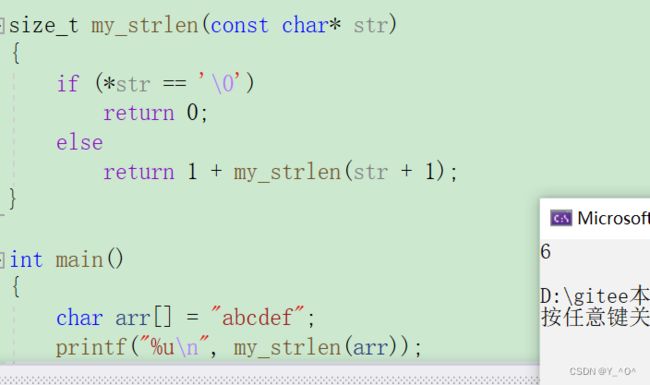
- 递归实现
怎么递归呢?
我们对传过来的首字符地址直接解引用,如果是’\0’,那就返回0。
如果不是’\0’,那说明至少有一个有效字符,让指针+1,返回1+my_strlen(str+1),直至遇到’\0’,开始回归得出结果。
size_t my_strlen(const char* str)
{
if (*str == '\0')
return 0;
else
return 1 + my_strlen(str + 1);
}
也能得到正确结果:
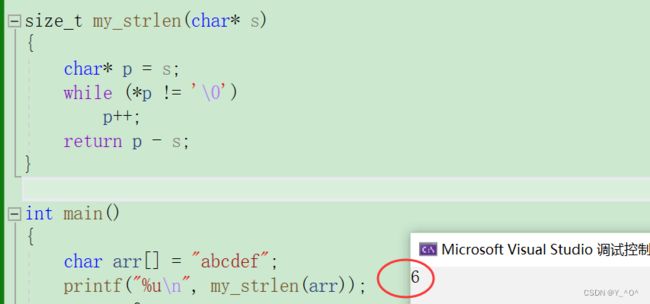
- 指针-指针
在指针的学习中我们已经知道,指针-指针得到的是两个指针之间的元素个数,那我们让一个指针指向首字符,另一个指针指向’\0’,后者减前者,得到的元素个数不就是字符串长度吗?
size_t my_strlen(char* s)
{
char* p = s;
while (*p != '\0')
p++;
return p - s;
}
这样依然可行:
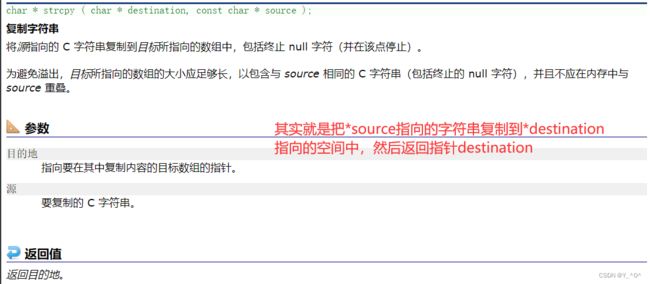
2.字符串拷贝——strcpy
先来认识一下它吧:

网站上都是英文的,不过我们可以翻译一下(当然有些地方可能翻译的不太准确):
2.1 使用及注意事项
- 源字符串必须以 ‘\0’ 结束
我们知道字符串的结束标志是’\0’,也就是说,strcpy在拷贝源字符串时,遇到’\0’才会停止拷贝,而跟字符串的长度无关,只要不遇到’\0’,就一直往后继续拷贝,那如果我们的源字符串中没有’\0’,会出现什么后果呢?
int main()
{
char arr1[20] = { 0 };
char arr2[] = {'a','b','c'};
strcpy(arr1, arr2);
return 0;
}
将arr2中的字符串拷贝到arr1中,但是arr2中的字符串并没有’\0’,会出现什么样的结果呢?

我们调试可以发现,这样是会发生错误的,因为在字符’a’、‘b’、‘c’的后面并没有放’\0’,所以strcpy会一直向后拷贝,我们不知道什么时候才会遇到’\0’停止下来,而且arr1我们申请的空间也是有限的,也不能无限的向里面放东西,所以这样就有可能造成越界,而且在’a’、‘b’、'c’后面会拷贝什么内容我们也不知道,这是不可行的。
因此,源字符串必须以 ‘\0’ 结束。
- 会将源字符串中的 ‘\0’ 拷贝到目标空间
strcpy在拷贝的时候会将源字符串的’\0’也拷贝到目标空间
我们来验证一下:
int main()
{
char arr1[20] = "*****************";
char arr2[] = "abc";
strcpy(arr1, arr2);
printf("%s", arr1);
return 0;
}

- 目标空间必须足够大,以确保能存放源字符串
既然我们要把源字符串拷贝放到目标空间,那一定要确保目标空间足够大,能够放得下源字符串,如果目标空间大小不够,肯定也会出现问题的。
int main()
{
char arr1[] = "abc";
char arr2[] = "xxxxxx";
strcpy(arr1, arr2);
printf("%s", arr1);
return 0;
}

- 目标空间必须可变
什么意思呢,就是目标空间放的内容必须是可修改的,因为我们要把源字符串的内容拷贝放进目标空间中(相当于修改了目标空间的内容),如果目标空间不可变,那肯定是不行的。
比如:
int main()
{
char* p = "hello world";
char arr[] = "abc";
strcpy(p, arr);
return 0;
}

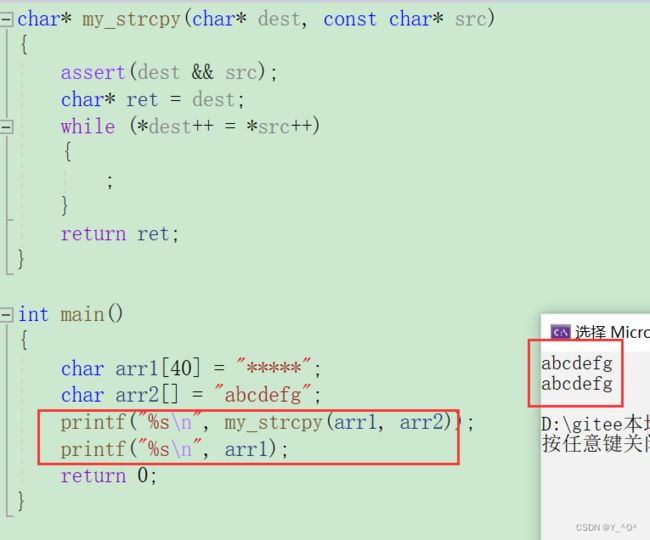
2.2 strcpy的模拟实现
接下来我们来模拟实现一下strcpy,直接上代码:
char* my_strcpy(char* dest, const char* src)
{
assert(dest && src);
char* ret = dest;
while (*dest++ = *src++)
{
;
}
return ret;
}
解释一下:

看一下效果:
3.字符串追加函数——strcat
一起来认识一下:

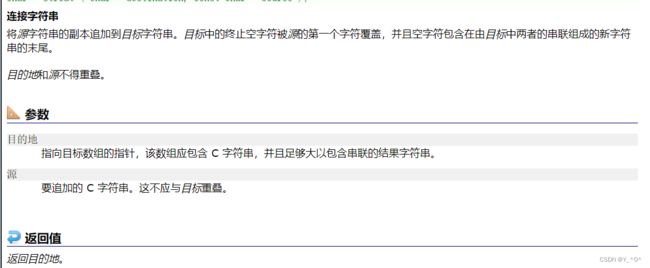
其实就是在一个字符串的后面追加上另外一个字符串。追加的字符串从目标字符串(即被追加的字符串)的结束标志’\0’处开始追加(会覆盖目标字符串的’\0’),追加至’\0’停止。
演示一下:
#include 看看效果:

3.1使用及注意事项
- 源字符串必须以 ‘\0’ 结束。
因为追加的时候还是遇到’\0’停止,如果源字符串中没有’\0’,就会一直继续向后追加,而后面的空间是不属于我们的,里面放的是什么东西也是未知的,这样肯定会出现问题的。

-
目标空间必须有足够的大,能容纳下源字符串的内容。
-
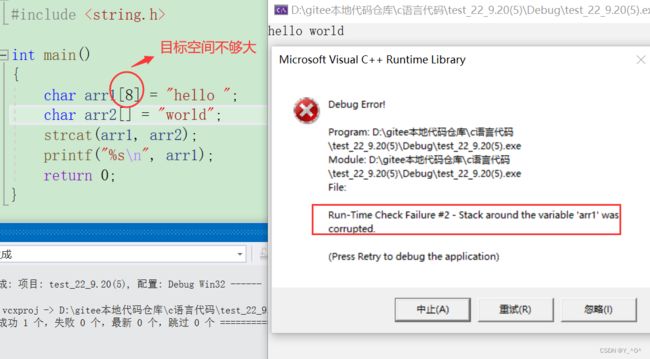
目标空间必须可修改
跟strcpy一样,要操作的目标空间必须是可变的,因为追加字符串相当于对目标空间做出了修改,所以目标空间必须是可变的,不能是字符串常量。
3.2 strcat的模拟实现
现在我们已经知道了strcat的参数和工作原理,那我们就来模拟实现一下它:
怎么搞呢?
我们知道strcat在追加字符串时是从目标字符串的结束标志’\0’处开始追加的(会覆盖掉目标字符串的’\0’),直至遇到’\0’追加结束,当然源字符串的’\0’也会追加上去。
那我们先用一个指针找到目标字符串的’\0’,然后的操作是不是就跟strcpy一样了啊,把源字符串的内容拷贝到目标字符串的’\0’之后不就行了嘛。
实现一下:
char* my_strcat(char* dest, const char* src)
{
assert(dest && src);
//1.找到目标字符串的'\0'
char* p = dest;
while (*p != '\0')
{
p++;
}
//2.将源字符串拷贝到目标空间的'\0'之后
while (*p++ = *src++)
{
;
}
return dest;
}
看看效果:

3.3思考
现在我们已经了解了这个函数了,那我们来思考一个问题,使用strcat可不可以实现 字符串自己给自己追加?
这样是不可行的!!!
为啥尼?
因为如果是字符串自己给自己追加,那么目标字符串和源字符串就是同一个字符串了,我们已经知道strcat在进行追加时是会将目标字符串的’\0’覆盖掉的,因为它是从’\0’处开始向后追加,那这样一来,源字符串中就没有’\0’,遇不到’\0’的话指针就会一直向后走,这样肯定会出现问题的。
所以这样的操作是不行的。
那有没有什么方法可以实现字符串自己给自己追加呢?
方法是有的,别着急,我们在后面给大家解答!

4.字符串比较函数——strcmp
先来认识一下:


4.1使用及注意事项
注意strcmp在比较字符串的时候不是比较两个字符串的长度,而是比较它们对应位置的字符,一个一个的比较,如果相等就比较下一个,不相等的时候,看两个字符谁大谁小(ASCII码值),返回对应的值。
下面我们来练习一下它的使用:
#include arr和arr1进行比较,前两个字符ab都相同,第三对字符arr的’x’大于arr1的’c’,所以arr大于arr1,返回1。
看看结果是不是:

4.2strcmp 的模拟实现
思路就很明白了,我们就一对一对的比较就行了。
如果两个字符串是一样的,那就一直往后比,直到遇到’\0’停止,返回0。
不一样的话,还是先一直往后比,比到不相同的那一对字符,判断它们的大小关系,返回对应值就行了。
我们来实现一下:
int my_strcmp(const char* s1, const char* s2)
{
assert(s1 && s2);
while (*s1 == *s2)
{
if (*s1 == '\0')
return 0;
s1++;
s2++;
}
if (*s1 > *s2)
return 1;
else
return -1;
}
看看效果:

当然这里我们实现的和strcmp一样,返回的是1,0,-1。
但其实不一定非得是1,-1,因为标准规定只要是大于0,小于0的数字就行了,所以我们还可以简化一下,直接返回*s1 - *s2,这样得到的是它们的ASCII码的差值,也符合要求。
int my_strcmp(const char* s1, const char* s2)
{
assert(s1 && s2);
while (*s1 == *s2)
{
if (*s1 == '\0')
return 0;
s1++;
s2++;
}
return *s1 - *s2;
}
5.小结
学到这里,我们来回顾一下刚才学的几个函数,strcpy、strcat、strcmp,我们会发现,这几个操作字符串的函数跟字符串的长度的是没有关系的,关键在于’\0’:
strcpy拷贝完’\0’就停止拷贝
strcat追加完’\0’就停止追加
strcmp比较完’\0’就停止比较
我们把它叫做长度不受限制的字符串操作函数。
那接下来,我们再来学习一组字符串操作函数,大家对比一下,和上面这几个有什么区别!
6. strncpy
6.1 与strcpy对比
我们发现这个函数的名字是不是和strcpy很像啊,就多了一个n而已,那它们两个有什么区别吗?
我们来对比一下:

我们来看一下:

那现在我们就明白了,参数num可以接收我们想要拷贝的字符的个数,那这样就使得我们可以控制我们想要拷贝的字符串的个数,是否拷贝结束就不再受’\0’的支配了。
6.2 使用及注意事项
我们来练习一下:
#include 
对于strncpy来说,我们传的参数是几,它就严格的拷贝几个字符,而且不会带’\0’。
虽然我们可以自己觉得拷贝的字符个数,但是我们也不能随意指定,也要在合理的范围内。
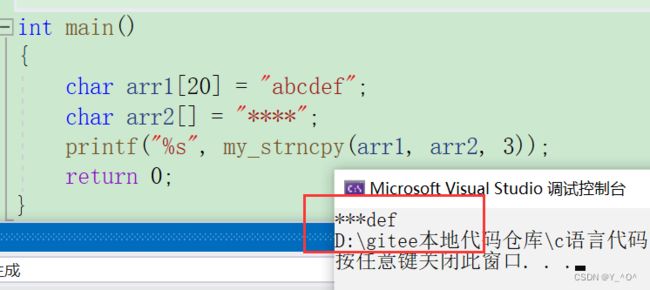
举个例子:
int main()
{
char arr1[10] = "abcdef";
char arr2[] = "****";
printf("%s", strncpy(arr1, arr2, 6));
return 0;
}
arr2中带上’\0’也只有5个字符,而我们却拷贝了6个。

我们来调试观察一下:

这样写貌似没有报错,但是,我们最好还是不要这样做。
6.3 strncpy的模拟实现
其实思路也很简单:
回想一下
strcpy模拟实现我们是怎么实现的,我们是每次拷贝一个字符,直至拷贝到"\0"停止。
那strncpy与strcpy相比就多了一个参数size_t num,那我们只搞一个循环,每次拷贝一个字符,循环num次就行了。
上代码:
char* my_strncpy(char* dest, const char* src,size_t num)
{
assert(dest && src);
char* ret = dest;
while (num--)
{
*dest++ = *src++;
}
return ret;
}
看看效果:
7. strncat
7.1与strcat对比
学过strncpy,相信大家就明白strncat是怎么回事了,它还是追加字符串的,只不过我们可以通过参数来控制要追加的字符个数。

7.2使用及注意事项
来练习一下strncat的使用:
int main()
{
char arr[20] = "abcdef";
char arr2[] = "*****";
printf("%s\n", strncat(arr, arr2, 4));
return 0;
}

那我们再来思考一个问题,strncat在追加完N个字符后,会不会在最后补上’\0’呢?
看这段代码:
int main()
{
char arr[20] = "abcdef\0oooooo";
char arr2[] = "*****";
printf("%s\n", strncat(arr, arr2, 4));
return 0;
}
我们来看一下追加之后,最后一个’*‘后面是’o’还是’\0’,如果是’o’,表示追加完没有补’\0’,如果是’\0’,那就是strncat在追加完补上的。
所以strncat在追加完会补上一个’\0’,以确保追加之后还是以一个字符串('\0’是字符串的结束标志)。

7.3上述3.3思考解答
上面在讲strcat的时候,我们遗留了一个问题,使用strcat无法实现字符串自己给自己追加,那我们刚才了解到strncat在追加之后会自动补上一个’\0’,那用strncat是不是可以实现字符串自己给自己追加呢?
答案是可以的!
我们来试一下:
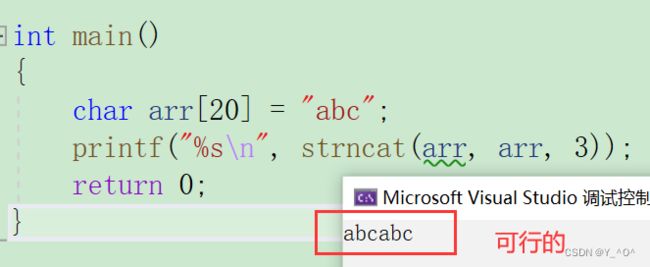
int main()
{
char arr[20] = "abc";
printf("%s\n", strncat(arr, arr, 3));
return 0;
}
7.4 strncat的模拟实现
strcat是从目标字符串(即被追加的字符串)的结束标志’\0’处开始追加(会覆盖目标字符串的’\0’),追加至’\0’停止。
那strncat是向后追加num个字符,那我们还是搞个循环就行了,循环num次,当然记得最后补上一个"\0"。
上代码:
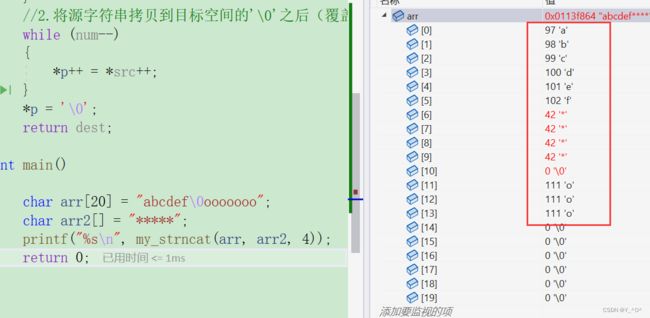
char* my_strncat(char* dest, const char* src, size_t num)
{
assert(dest && src);
//1.找到目标字符串的'\0'
char* p = dest;
while (*p != '\0')
{
p++;
}
//2.将源字符串拷贝到目标空间的'\0'之后(覆盖"\0")
while (num--)
{
*p++ = *src++;
}
*p = '\0';
return dest;
}
看看效果:
8. strncmp

8.1 使用练习
那strncmp与strcmp相比当然还是多了一个参数size_t num。使得我们可以控制我们想要比较的字符个数。
它的比较规则以及返回值和strcmp还是一样的。
我们来练习练习:
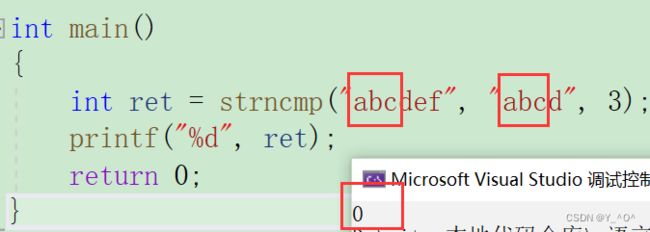
int main()
{
int ret = strncmp("abcdef", "abcd", 3);
printf("%d", ret);
return 0;
}
只比较前3个字符,那他们都是"abc",是一样的,所以应该返回0,我们看看结果是不是:
其它两种情况就不给大家一一演示了。
8.2 strncmp的模拟实现
与strncmp模拟实现相比加一个限制条件控制比较的个数就行了。
如果两个字符串是一样的,那就一直往后比,遇到’\0’或者num等于0都停止,返回0。
不一样的话,还是先一直往后比,比到不相同的那一对字符,判断它们的大小关系,返回对应值就行了。
上代码:
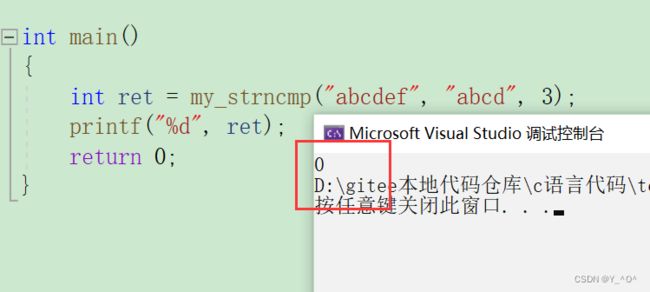
int my_strncmp(const char* s1, const char* s2, size_t num)
{
assert(s1 && s2);
while (*s1 == *s2 && num--)
{
if (*s1 == '\0' || num == 0)
return 0;
s1++;
s2++;
}
if (*s1 > *s2)
return 1;
else
return -1;
}
看看效果:
9.字符串查找函数——strstr
9.1使用及注意事项
接下来我们再来认识一个函数——strstr。它的作用是什么呢?
在一个字符串(str1)中查找另一个字符串(str2)是否存在,
如果存在,返回该字串的起始地址,如果出现多次,返回的是第一次出现的地址。
比如:在abcdefabcdefabcd中寻找fab,fab出现了两次,我们返回第一个fab的起始地址。
如果不存在,返回NULL。

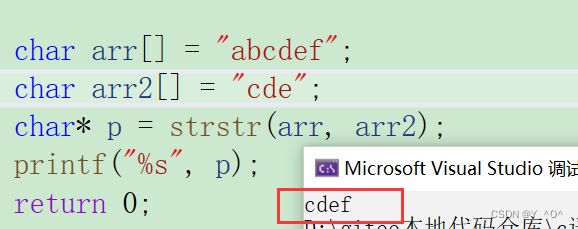
我们来练习一下它的使用:
int main()
{
char arr[] = "abcdef";
char arr2[] = "cde";
char* p = strstr(arr, arr2);
printf("%s", p);
return 0;
}
cde在arr中存在,那应该返回cde的起始地址,我们打印出来应该是cdef,验证一下:
9.2strstr的模拟实现
然后我们来尝试模拟实现一下strstr,先来看一下代码:
char* my_strstr(const char* str1, const char* str2)
{
assert(str1 && str2);
const char* s1 = str1;
const char* s2 = str2;
const char* p = str1;
while (*p)
{
s1 = p;
s2 = str2;
while ((*s1 != '\0') && (*s2 != '\0') && (*s1 == *s2))
{
s1++;
s2++;
}
if (*s2 == '\0')
return (char*)p;
p++;
}
return NULL;
}
下面来解释一下:

来看看效果:

可以实现!
10. strtok
10.1功能解释及使用说明

这个函数是干嘛的呢?解释一下:
首先来看strtok的第二个参数delimiters,delimiters是分隔符的意思,那这个参数是接收啥呢?
- 参数delimiters的类型是char *,它是用来接收字符串中所有分隔符所组成的字符集合的。
比如:有这样一个字符串
char arr[][email protected];,我们把"@."作为分隔符,可以将该字符串拆分为:
helloworld
strtok
hhh
那我们把这个分隔符的集合放到一个字符串中:
char* p="@.;
那我们就可以把p传给参数delimiters。
- 第一个参数
char* str;接收被分隔符分割的那个字符串[email protected]
那把这些传给它,strtok能帮我们做什么呢?
当我们把arr和p传给strtok:
- strtok函数的第一个参数不为 NULL ,strtok函数找到str中的第一个标记(分隔符)时停止,保存它在字符串
中的位置,并将其用 \0 结尾,返回一个指向这个标记的指针(对这个字符串来说就是返回首字符h的地址)。
注:strtok函数会改变被操作的字符串,所以在使用strtok函数切分的字符串一般都是临时拷贝的内容并且可修改。
看代码:
int main()
{
char arr[] = "[email protected]";
char* p = "@.";
char* ret = strtok(arr, p);
printf("%s", ret);
return 0;
}
那按照上面的规则,strtok会找到第一个分隔符’@‘,将其置为’\0’,返回h的地址。
那我们将它的返回值以字符串形式打印出来应该就是helloworld,虽然后面还有,但我们知道打印到’\0’就结束了嘛,我们看看是不是:

我们现在拿到了被分割符分开的第一个字串helloworld,如果我们还行拿到后面的strtok和hhh,我们应该怎么做呢?
当我们想从上次的第一个分隔符的位置继续向后分割字符串拿到
strtok时,我们需要再次调用strtok函数,但是这次第一个参数我们应该NULL,为什么呢?
4.strtok函数的第一个参数为 NULL ,函数将从上一次字符串中被保存的位置开始,查找下一个标记。
也就是说,再次调用该函数时,只要我们第一个参数给它传空指针
NULL,strtok就会从上次保存的位置(即上次查到的分隔符的位置),继续向后寻找下一个分隔符,将其置为’\0’,然后返回起始地址。
那我们这样是不是就可以拿到第二个被分隔的字串strtok了。
char arr[] = "[email protected]";
char* p = "@.";
char* ret = strtok(arr, p);
printf("%s\n", ret);
ret = strtok(NULL, p);
printf("%s\n", ret);

那我们想拿到最后一个字串hhh,再次去调用strtok的话,后面已经没有分隔符了,那会怎么样呢?
- 如果找到终止空字符,扫描也会停止,返回起始地址。
也就是说,虽然后面没有分隔符了,但是strtok扫描到’\0’,也会停止,那这样我们就拿到最后一个字串了。
char arr[] = "[email protected]";
char* p = "@.";
char* ret = strtok(arr, p);
printf("%s\n", ret);
ret = strtok(NULL, p);
printf("%s\n", ret);
ret = strtok(NULL, p);
printf("%s\n", ret);
return 0;

- 一旦在对 strtok 的调用中找到 str 的终止空字符,则对此函数的所有后续调用(以空指针作为第一个参数)都将返回空指针。
也就是说,当strtok将字符串处理完之后,如果我们再去以NULL作为第一个参数去调用strtok,都将返回空指针NULL。
10.2 代码演示及优化
到这里,相信大家就应该明白这个函数的使用了,然后我们再来看一下刚才的代码:
#include 大家有没有觉得这样写太挫了啊,我们是知道已经知道这个字符串被分隔成了3段,所以我们调用3次,那以后操作其它的字符串,是不是调用次数也要变啊。
接下来我们就来改进一下这个代码:
怎么搞呢?我们先来看代码:
int main()
{
char arr[] = "[email protected]";
char* p = "@.";
char* str = NULL;
for (str = strtok(arr, p); str != NULL; str = strtok(NULL, p))
{
printf("%s\n", str);
}
return 0;
}
解释一下:
for循环的初始化部分为
str = strtok(arr, p),我们知道for循环的初始化部分只执行一次,而我们在调用strtok时恰好就是第一次需要传字符串,而且也只传一次,这正好符合我们的调用操作。
接下来我们再次调用函数就需要传空指针了,而恰好调整部分就是str = strtok(NULL, p),这样正好符合我们的需求。
然后判断部分为str != NULL,而strtok 如果返回空指针,就证明已经找到终止字符’\0’了,已经对字符串分割完毕了,这时候停止循环,正好符合我们的需求。
我们来测试一下效果:

完美!!!
11. strerror
11.1功能解释及使用说明
我们看它的参数,接收一个整型,返回一个字符指针,那它是用来干嘛的呢?
strerror函数的功能是:
将C语言中的错误码转化为对应的错误信息,并返回对应错误信息字符串的首地址。
演示一下:
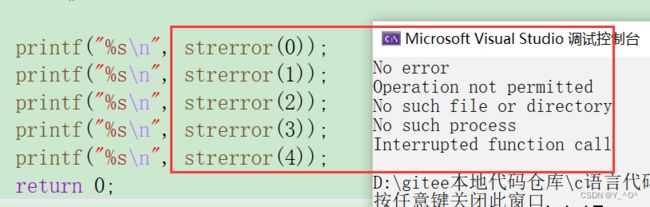
int main()
{
printf("%s\n", strerror(0));
printf("%s\n", strerror(1));
printf("%s\n", strerror(2));
printf("%s\n", strerror(3));
printf("%s\n", strerror(4));
return 0;
}
我们来看一下结果:
11.2 应用场景
C语言的库函数在调用失败时会产生错误码,这个错误码会保存到errno中,errno——C语言提供的全局的错误变量,产生错误时的错误码会记录到错误码变量errno中。
举个例子:
int main()
{
FILE* pFile;
pFile = fopen("unexist.ent", "r");
if (pFile == NULL)
{
printf("Error opening file unexist.ent: %s\n", strerror(errno));
printf("%d\n", errno);
}
return 0;
}
我们使用库函数fopen打开一个文件
unexist.ent,但是这个文件并不存在,所以它是会发生错误的,我们就把这个保存在errno中的错误码对应的错误信息打印出来看看。

这就是strerror的一个应用。
以上就是对C语言中常见的字符串函数的一个介绍,欢迎大家指正,希望能帮助到大家!!!
