ARMA、ARIMA和SARIMA
ARMA、ARIMA和SARIMA
1 背景知识
1.1 自回归模型(AR)
描述当前值与历史值之间的关系,用变量自身的历史时间数据对自身进行预测,自回归模型必须满足平稳性。

- 自回归(AR),就是指当前值只与历史值有关,用自己预测自己
- p阶自回归,指当前值与前p个值有关
- 求常数u与自回归系数ri
- 自回归模型的限制
(1)自回归模型是用自身的数据来进行预测,即建模使用的数据与预测使用的数据是同一组数据;
(2)必须具有平稳性;
(3)必须具有自相关性,如果自相关系数(φi)小于0.5,则不宜采用;
(4)自回归只适用于预测与自身前期相关的现象。
1.2 移动平均模型(MA)
移动平均模型关注的是自回归模型中的误差项的累加,移动平均法能有效地消除预测中的随机波动。
![]()
- q阶自回归,指当前值与前q个误差有关
- 求常数u与系数θi
1.3 自回归移动平均模型(ARMA)
自回归与移动平均的结合
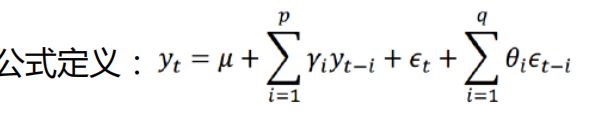
- p与q分别为自回归模型与移动平均模型的阶数,需要人为定义
- γi与θi分别是两个模型的相关系数,需要求解
- 如果原始数据不满足平稳性要求而进行了差分,则为差分自相关移动平均模型(ARIMA),将差分后所得的新数据带入ARMA公式中即可
1.4 判断时序数据是否稳定的方法
- 严谨的定义: 一个时间序列的随机变量是稳定的,当且仅当它的所有统计特征都是独立于时间的(是关于时间的常量)。
- 判断的方法:
(1)稳定的数据是没有趋势(trend),没有周期性(seasonality)的; 即它的均值,在时间轴上拥有常量的振幅,并且它的方差,在时间轴上是趋于同一个稳定的值的。
(2)可以使用Dickey-Fuller Test进行假设检验。
2 ARIMA的参数与数学形式
ARIMA模型有三个参数:p,d,q。
- p --代表预测模型中采用的时序数据本身的滞后数(lags) ,也叫做AR/Auto-Regressive项
- d --代表时序数据需要进行几阶差分化,才是稳定的,也叫Integrated项。
- q --代表预测模型中采用的预测误差的滞后数(lags),也叫做MA/Moving Average项
先解释一下差分: 假设y表示t时刻的Y的差分。

ARIMA的预测模型可以表示为:
Y的预测值 = 常量c and/or 一个或多个最近时间的Y的加权和 and/or 一个或多个最近时间的预测误差。
假设p,q,d已知,ARIMA用数学形式表示为:
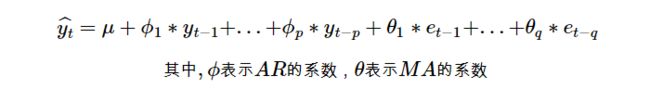
3 ARIMA模型的几个特例
3.1 ARIMA(0,1,0) = random walk:
当d=1,p和q为0时,叫做random walk(随机游走),如图所示,每一个时刻的位置,只与上一时刻的位置有关。
预测公式如下:

3.2 ARIMA(1,0,0) = first-order autoregressive model:
p=1, d=0,q=0。说明时序数据是稳定的和自相关的。一个时刻的Y值只与上一个时刻的Y值有关。
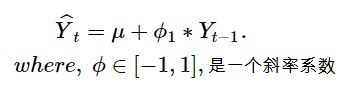
3.3 ARIMA(1,1,0) = differenced first-order autoregressive model:
p=1,d=1,q=0. 说明时序数据在一阶差分化之后是稳定的和自回归的。即一个时刻的差分(y)只与上一个时刻的差分有关。

3.4 ARIMA(0,1,1) = simple exponential smoothing with growth.
p=0, d=1 ,q=1.说明数据在一阶差分后市稳定的和移动平均的。即一个时刻的估计值的差分与上一个时刻的预测误差有关。

3.5 ARIMA(2,1,2)
在通过上面的例子,可以很轻松的写出它的预测模型:
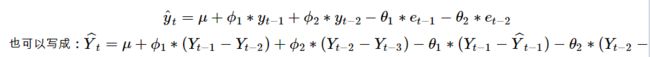
3.6 ARIMA(2,2,2)
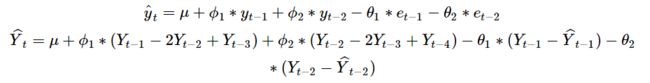
4 ARIMA建模基本步骤
- 获取被观测系统时间序列数据;
- 对数据绘图,观测是否为平稳时间序列;对于非平稳时间序列要先进行d阶差分运算,化为平稳时间序列;
- 经过第二步处理,已经得到平稳时间序列。要对平稳时间序列分别求得其自相关系数ACF和偏自相关系数PACF,通过对自相关图和偏自相关图的分析,得到最佳的阶层 p 和阶数 q
- 由以上得到的d、q、p,得到ARIMA模型。然后开始对得到的模型进行模型检验。
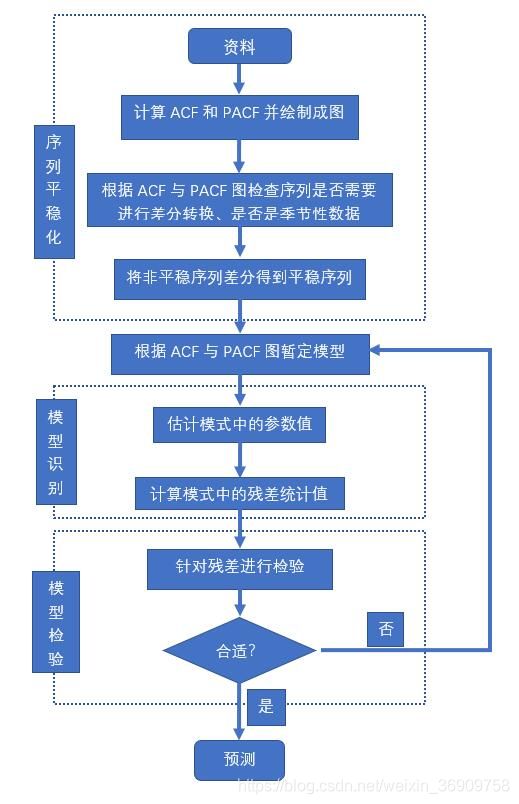
总结d、p、q这三者的选择,一般而言就算不是非平稳的时间序列数据,经过一阶差分或者二阶差分就可以转换为弱平稳甚至是平稳的时间序列数据;对于p和q的选择一般需要根据ACF和PACF图进行判断,下面说明如何根据ACF和PACF图得到相应的p、q值。
5 ARIMA中p、q阶数确定
5.1 自相关与偏自相关
- 自相关函数(ACF)是将有序的随机变量序列与其自身相比较,它反映了同一序列在不同时序的取值之间的相关性。(包含了其他阶的影响)
- 偏自相关函数(PACF)计算的是严格的两个变量之间的相关性,是剔除了中间变量的干扰之后所得到的两个变量之间的相关程度。(只包含这两阶的影响,更绝一些,把中间阶都剔除了)
5.2 截尾与拖尾
- 截尾:在大于某个常数k后快速趋于0为k阶截尾
- 拖尾:始终有非零取值,不会在k大于某个常数后就恒等于零(或在0附近随机波动)
5.3 p,q确定

截尾:落在置信区间内(图中阴影部分)
AR§:PACF中第几个点落到阴影面积中,就为第几阶p
MA(q) :ACF中第几个点落到阴影面积中,就为第几阶q
5.4 举例

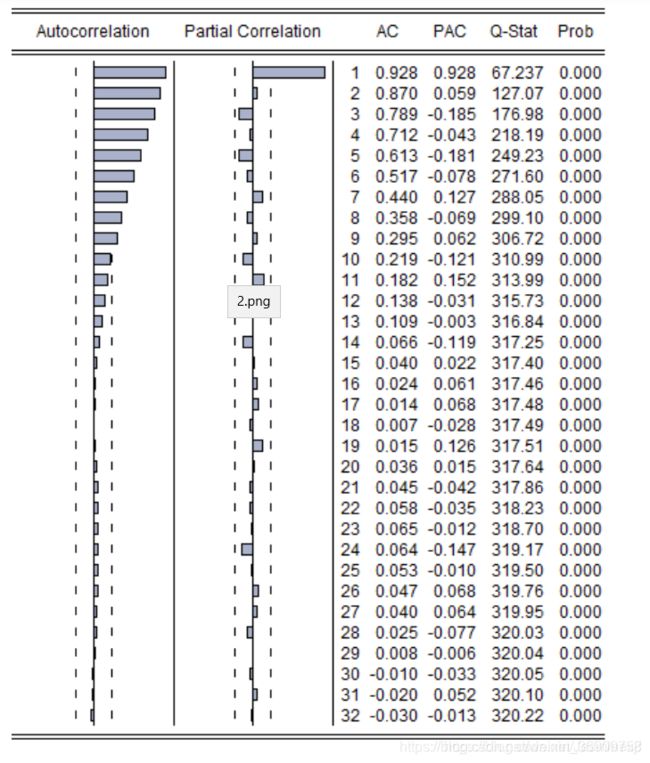
第一个图,偏自相关和自相关都是2阶截尾,所以p,q都是2,就是ARMA(2,2)。
第二个图, 偏自相关1阶截尾,自相关拖尾,就是ARMA(1,0)。
6 ARIMA的优缺点
- 优点: 模型十分简单,只需要内生变量而不需要借助其他外生变量。
- 缺点:
(1)要求时序数据是稳定的(stationary),或者是通过差分化(differencing)后是稳定的。
(2)本质上只能捕捉线性关系,而不能捕捉非线性关系。
注意,采用ARIMA模型预测时序数据,必须是稳定的,如果不稳定的数据,是无法捕捉到规律的。比如股票数据用ARIMA无法预测的原因就是股票数据是非稳定的,常常受政策和新闻的影响而波动。
7 SARIMA
周期性时间序列,可以作为ARIMA的扩展,因此,首先需要去除周期性,去除的方式是在周期间隔上做一次ARIMA,此时可以得到一个非平稳非周期性的时间序列,然后在此基础之上再一次使用ARIMA进行分析。可以表示为:
ARIMA(p, d, q) × (P, D, Q)S ,其中各参数含义为:
P: 周期性自回归阶数.
D: 周期性差分阶数.
Q: 周期性移动平均阶数.
S: 周期时间间隔.
p,d,q的含义与上面的ARIMA里面含义相同。
举个例子:
对于周期为12的非平稳时间序列,那么ARIMA(3,1,0) x (2,1,0)12的含义为:
D=1意味着当前时刻t的值与过去一个周期时间点t-12的1阶差分,
P=2意味着当前时刻t的值是过去两个周期时间点t-12以及t-24的回归。
处理以后得到的时间序列再通过ARIMA(3,1,0)进行分析。
参考
1.https://www.cnblogs.com/bradleon/p/6827109.html
2.https://blog.csdn.net/TU_JCN/article/details/88130820
3.https://blog.csdn.net/jasminexjf/article/details/94993362
4.https://blog.csdn.net/just_lion/article/details/88226526