Presto初步剖析
Presto
一、概况
即席查询
- 充分利用内存(Presto)
- 预查询思想(kylin)
开源的分布式SQL查询引擎,开源的,并不是阿帕奇的。用它就是写SQL
GB->PB 查询比较快的,查询延迟比较低的,秒级查询的场景
Presto不是一个标准的数据库,查询需要对接其他数据源,查询引擎 分析引擎
如果想要计算的数据分散在Hdfs、Hive、ES、Hbase、MySql、Kafka中,应该怎么做?
Facebook科学家们发现目前并没有一款合适的计算引擎,最终决定开发一款MPP交互式计算引擎
2012年秋天进行研发,2013年开源出来并成功用其对300PB的数据进行运算,奠定了Presto的地位
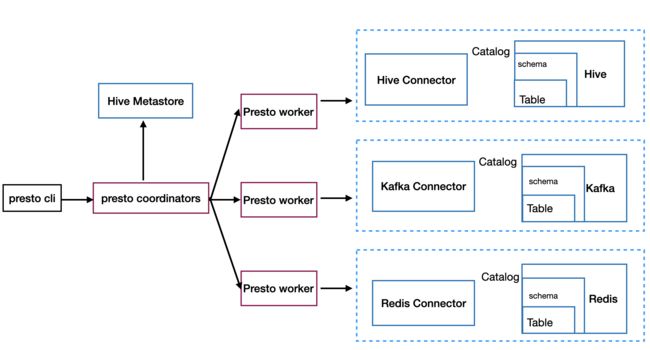
master/slave架构
- coordinators 解析SQL语句,生成执行计划,分发执行任务给Worker节点执行
- **workers **负责执行实际查询任务,访问底层存储系统。
- Worker节点启动后向Discovery Server服务注册,Coordinator从Discovery Server获得可以正常工作的Worker节点
架构图
优点:
- 基于内存运算,减少了硬盘IO,计算更快
- 能够连接多个数据源,跨数据源连表查,比如从Hive查询大量网站访问记录,然后从Mysql中匹配出设备信息。
缺点:
- Presto能处理PB级别的海量数据分析,但Presto并不是把PB即数据都放在内存中计算。而是根据场景,如Count,AVG等聚合运算,是边堵数据边计算,再清理内存,再读数据再计算,这种内存耗的并不高。但是连表查,就可能产生大量的临时数据,因此速度会变慢。
解决:
数据模型
PipeLine模式:
Worker节点将小任务封装成一个PrioritizedSplitRunner对象,放入pending split优先级队列中
Worker节点启动一定数目的线程进行计算,线程数task.shard.max-threads=availableProcessors() * 4
每个空闲线程从队列中取出PrioritizedSplitRunner对象执行,每隔1秒,判断任务是否执行完成,如果完成,从allSplits队列中删除,如果没有,则放回pendingSplits队列
每个任务的执行流程如下图右侧,依次遍历所有Operator,尝试从上一个Operator取一个Page对象,如果取得的Page不为空,交给下一个Operator执行
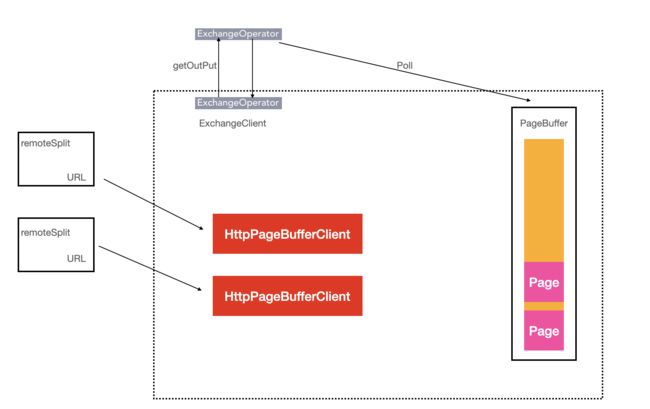
节点间流水线计算
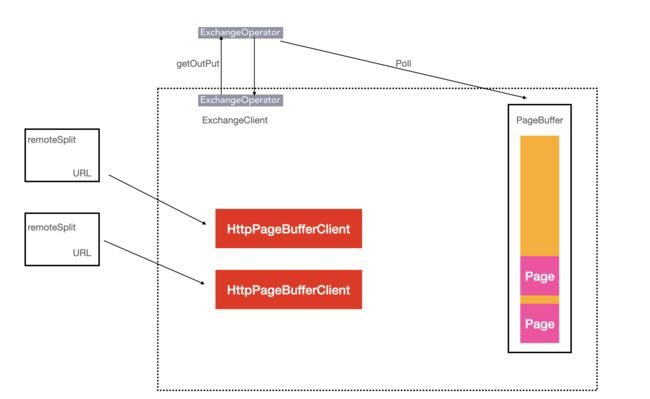
ExchangeOperator的执行流程图,ExchangeOperator为每一个Split启动一个HttpPageBufferClient对象,主动向上一个Stage的Worker节点拉数据,拉取的最小单位也是一个Page对象,取到数据后放入Pages队列
presto采取三层表结构:
- catalog 对应某一类数据源,例如hive的数据,或mysql的数据
- schema 对应mysql中的数据库
- table 对应mysql中的表
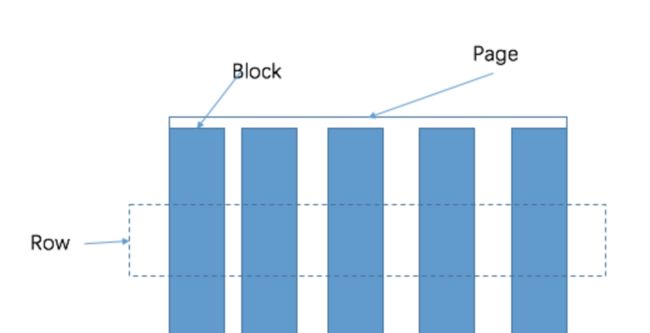
presto的存储单元包括:
- Block是一张表的一个字段对应的队列
- Page由Block构成,一个Page包含多个Block,多个Block横切为一行。
列式存储
- 顺序写文件。
- 一行数据多个属性,有多少个属性就有多少个文件,把一行数据放到多个文件中,对于复杂数据,肯定不行。一个ppt,每页分成一个文件。
- 内存中缓存数据,缓存到一定量后,将各个列的数据放在一起打包,各个包再按一定顺序写入文件,精8髓:按列缓存打包
- 每一列也会分成一个个数据包,这就是Page,(1000行打包一个page或8Kb打包一个page)
- 每列数据类型一致,高效压缩。数据既是索引,只访问查询涉及的列。
-
ORC文件格式 ORC文件格式是一种Hadoop生态圈中的列式存储格式
-
文件footer里存储了每个条带(script)的最大值最小值,可以用来过滤
snappy压缩
- parquet (Impala支持最好)
- orc (Presto支持最好)
Snappy 是一个 C++ 的用来压缩和解压缩的开发包。其目标不是最大限度压缩或者兼容其他压缩格式,而是旨在提供高速压缩速度和合理的压缩率
列式存储 行式存储各有各自的优缺点,在OLAP场景下,我们需要的就是列式存储。
执行计划分析
一个查询是由Stage、Task、Driver、Split、Operator和DataSource组成
每个查询分解为多个stage
每个 stage拆分多个task(每个PlanFragment都是一个Stage)
每个task处理一个或多个split(Driver)
每个Driver处理一个split,每个Driver都是作用于一个split的一系列Operator集合
每个split对应一个或多个page对象 :一个大的数据集中的一个小的子集
每个page包含多个block对象,每个block对象是个字节数据 (presto中最小处理单位)
Operator:一个operator代表对一个split的一种操作(如过滤、转化等)
operator每次只会读取一个page对象 并且每次也只会产生一个page对象
Cli —> parser—>analysis —> 优化 —> 拆分为子plan —> 调度
一般分为四种Stage:
- Source Stage: 从数据源读取数据
- Fixed Stage: 进行中间的运算
- Single Stage: 也称为Root Stage,这个是必不可少的,用于最后把数据汇总给Coordinator
- Coordinator_Only:用于执行DDL语句等不需要进行计算的语句
一个简单查询,最终构造为一个QueryPlan。对于较复杂的查询,是多个QueryPlan的组合。
Task
Task是Stage的具体分布式查询计划,由Coordinator进行划分
Task需要通过Http接口发送到具体的Node上去,然后生成对应的本地执行计划
一个Stage可以分解为多个同构的Task
Driver
Task是发送到本地的执行计划
Task被分为多种Driver去并发的执行
Operator
一个Driver内包含多个Operator
真正操作Page数据的是Operator
一个Operator代表一种操作,比如Scan->读取数据, Filter -> 过滤数据
优化过程
谓词下推:基本思想即:将过滤表达式尽可能移动至靠近数据源的位置,以使真正执行时能直接跳过无关的数据。(将过滤表达式下推到存储层直接过滤数据,减少传输到计算层的数据量)
- 客户端调用CN提供的查询rest接口,CN接收到请求后创建一个对应的Query对象放在队列里并转化为Statement树,同时返回一个QueryId给客户端用于后续获取状态以及获取结果
QueuedStatementResource对象 - 在客户端初次通过QueryId进行查询时,CN会启动一个线程对这个Query对象进行调度
SqlQueryExecution对象 - 首先将Query对象对应的Statement转化为AST对象;此阶段做语法校验、语句重写以及权限校验
Analysis对象 - 执行计划编译器将语法树层层展开,把树转成树状的执行结构,每个节点都是一个操作;此时会优化器会发挥作用,生成效率更高的执行计划树。
Plan 对象 - 对执行计划树进行分布式处理,使其可以并行的运算处理。
SubPlan 对象
1~5 是发生在Coordinator进程中的预查询阶段 - 遍历逻辑执行计划树获取需要执行的Stage集合
SqlQueryScheduler#createStages方法:创建Stages集合列表
StageExecutionPlan 对象 - 生成逻辑执行计划并开始进行任务调度,此时调度的最小单位是Task;Task的作用是在Worker拉起计算任务同时周期查询此Task的状态
SqlQueryScheduler 对象
6~7 是发生在Coordinator进程中的调度阶段 - Worker提供接口给Coordinator进行Task的状态更新
TaskResource对象 - Worker有缓存TaskId和SqlTask的映射,在接收到请求时会根据TaskId获取对应的SqlTask来进行请求处理
每个Task任务都有唯一对应的SqlTask对象,每个SqlTask对象都有唯一对应的TaskHolder对象
TaskHolder对象存储Task的状态以及Task处理逻辑 SqlTaskExecution - 先构造TaskContext 对象,再根据此对象来创建本地执行计划,最终根据本地执行计划构造Task执行器SqlTaskExecution
LocalExecutionPlanner 对象 - 在构造SqlTaskExecution对象时,其会以依赖注入方式构造对应的TaskExecutor 对象
TaskExecutor对象通过构造函数并以线程池方式添加计算任务,由TaskRunner对象封装计算逻辑
每个TaskRunner对象从待处理split队列头获取一个split进行处理;加锁根据DriverContext和算子集合来构造并执行Driver - TaskExecutor对象通过DriverSplitRunner对Driver进行管理,此时执行Driver的逻辑
释放算子Operator不用的内存资源,同时根据条件进行磁盘溢写操作;更新Driver的数据源split列表信息
TaskRunner线程对象会依次处理Split/Driver队列中的任务直到队列为空,此时SqlTask对象的状态就会变为已完成状态
Driver 对象 - 将该Task对应的TaskSource列表存到SqlTaskExecution中同时更新此Task对应的Driver的数据源。同时将当前Task状态信息返回给Coordinator
- 在更新Task对应的数据源时,开始进行任务调度
SqlTaskExecution#schedulePartitionedSource
8~14发生在Worker节点
内存管理分析
Presto是一款内存计算型的引擎,所以对于内存管理必须做到精细
使用Slice进行内存操作,Slice使用Unsafe#copyMemory实现了高效的内存拷贝
内存池
Presto采用逻辑的内存池,来管理不同类型的内存需求。
Presto把整个内存划分成三个内存池,分别是System Pool ,Reserved Pool, General Pool。

- System Pool 是用来保留给系统使用的,用于读写buffer,默认为40% JVM max memory * 0.4。的内存空间留给系统使用。
- Reserved Pool和General Pool 是用来分配query运行时内存的。
- 其中大部分的query使用general Pool。 而最大的一个query,使用Reserved Pool, 所以Reserved Pool的空间等同于一个query在一个机器上运行使用的最大空间大小,默认是10%的空间JVM max memory * 0.1。
- General则享有除了System Pool和General Pool之外的其他内存空间。
为什么要使用内存池
System Pool用于系统使用的内存,例如机器之间传递数据
为什么需要保留区内存呢?并且保留区内存正好等于query在机器上使用的最大内存?
如果没有Reserved Pool, 那么当query非常多,并且把内存空间几乎快要占完的时候,某一个内存消耗比较大的query开始运行。但是这时候已经没有内存空间可供这个query运行了,这个query一直处于挂起状态,等待可用的内存。 但是其他的小内存query跑完后,又有新的小内存query加进来。由于小内存query占用内存小,很容易找到可用内存。 这种情况下,大内存query就一直挂起直到饿死。
所以为了防止出现这种饿死的情况,必须预留出来一块空间,共大内存query运行。 预留的空间大小等于query允许使用的最大内存。Presto每秒钟,挑出来一个内存占用最大的query,允许它使用reserved pool,避免一直没有可用内存供该query运行。
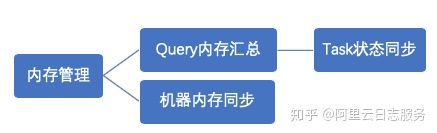
Presto内存管理,分两部分:
-
query内存管理
-
- query划分成很多task, 每个task会有一个线程循环获取task的状态,包括task所用内存。汇总成query所用内存。
- 如果query的汇总内存超过一定大小,则强制终止该query。
-
机器内存管理
-
- coordinator有一个线程,定时的轮训每台机器,查看当前的机器内存状态。
当query内存和机器内存汇总之后,coordinator会挑选出一个内存使用最大的query,分配给Reserved Pool。
内存管理是由coordinator来管理的, coordinator每秒钟做一次判断,指定某个query在所有的机器上都能使用reserved 内存。那么问题来了,如果某台机器上,,没有运行该query,那岂不是该机器预留的内存浪费了?为什么不在单台机器上挑出来一个最大的task执行。原因还是死锁,假如query,在其他机器上享有reserved内存,很快执行结束。但是在某一台机器上不是最大的task,一直得不到运行,导致该query无法结束。
Presto底层数据拉取和运算的设计和实现
Presto在数据进行shuffle的时候,是Pull模式。
在两端负责分发和交换数据的类分别是ExchangClient和OutputBuffer。
Source Stage把数据从Connector中拉取出来,这时候需要给下一个FixedStage进行处理。
他会先把数据放在OutputBuffer中,等待上游把数据请求过去,而上游请求数据的类就是ExchangeClient。
@Path("{taskId}/results/{bufferId}/{token}")
ExchangeClient
ExchangOperator
@Override
public Page getOutput()
{
SerializedPage page = exchangeClient.pollPage();
if (page == null) {
return null;
}
}
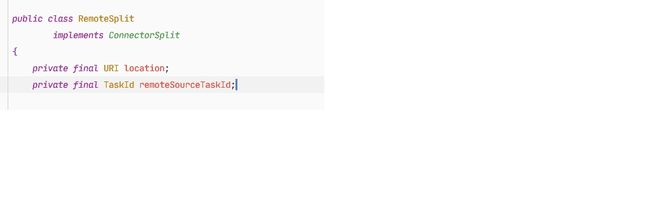
ExchangOperator接收的HttpPageBufferClient

这在一定的程度上缓解了请求的压力,同时为节约了下游的cpu资源。因为如果那台服务器挂了,那么一直无意义的http请求是毫无意义的,还会一直浪费cpu资源。
BroadcastOutputBuffer和PartitionedOutputBuffer
每来一个Page,把大小加进去,每出一个Page把大小减去,如果当前攒着的大小超过了阈值,那么就返回Blocked,把整个Driver给Block掉,不去执行了。
partition的情形,因为每一个Page进来,只会分到指定的一个ClientBuffer中,移除的时候直接减去就行了。
对于广播 定怎么知道已经被所有的Task取走了呢
包装了一个PageReference类,传递进去原先的Page和一个回调,这个回调就是把当前的BufferSize减去CurPageSize。
引用计数的实现,每add到Buffer中一次,计数就加一,每从buffer中移除一次,计数就减一,当为0的时候,就调用回调把size减去。
性能调优
由于采用列式存储,选择需要的字段读取、减少数据量,避免*
能以分区做过滤条件尽量使用分区
group by语句优化,合理安排语句顺序count(distinct)数据 降序排序 id gender
order by要使用limit 排序需求大部分不会全局的排序集。最终要合并到一个节点,压力过大。没个worker的前100.
join 大表放前边,小表放后边 hive不需要考虑这个问题。为什么:
- presto join有两种:broadcastjoin,用在最大表join小表。切一张表,剩一张表广播,切的原则是切前边的。
-
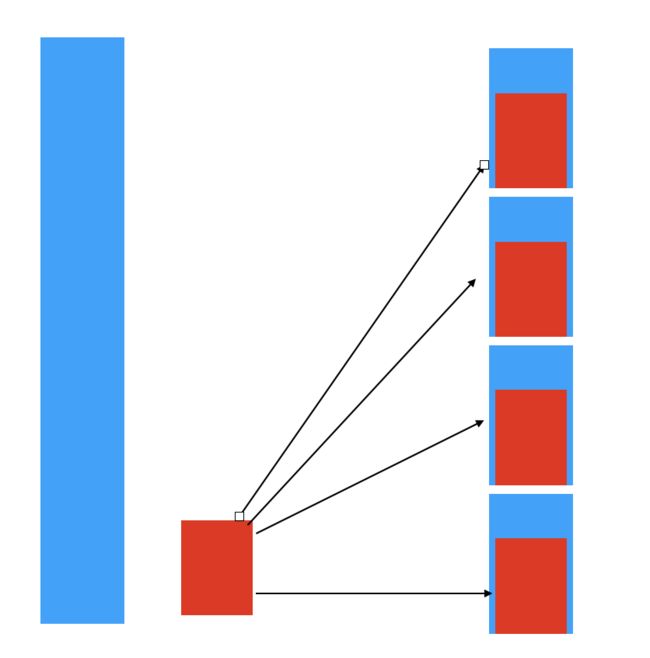
- hash join应对的场景 两张大表,把hash相同的放到同一个worker,这样就不用考虑先后了
字段名饮用,票号,用的是双引号。
时间类型,
目前仅支持parquet格式 列式存储格式的读取,不支持插入
- 调整线程数增大task的并发以提高效率。
- worker处理split的线程数。
- 每个worker上处理split的数,当单个spilt处理时间短时可调大。
部分源码分析
启动过程
-
PrestoServer类 启动类,启动一个server线程
-
加载框架 相比Spring的IOC,Google的Injector更轻量级一些
-
加载插件 plugins目录下,将其注册到PluginManager中
-
加载数据源
StaticCatalogStore类
加载资源管理
加载权限管控
- AccessControlManager类
启动服务
启动客户端
./prestocli --server 127.0.0.1:8080 --catalog mysql --schema default
show shemas;
should tables;