【openGauss笔记】SQL语法-8 聚集与分组操作
文章目录
- 8. 聚集与分组操作
-
- 8.1 COUNT - 计数
- 8.2 SUM - 求和
- 8.3 AVG - 平均值
- 8.4 MAX - 最大值
- 8.5 MIN - 最小值
- 8.6 GROUP BY - 分组

CREATE TABLE t1 (
C1 INTEGER,
C2 INTEGER
);
INSERT INTO t1 VALUES (1,2), (1,NULL), (2,2);
CREATE TABLE t2 (
C1 INTEGER,
C2 INTEGER
);
INSERT INTO t2 VALUES (1,2), (1,1), (NULL,2);
CREATE TABLE t3 (
C1 INTEGER,
C2 INTEGER
);
INSERT INTO t3 VALUES (1,1), (1,2);
8. 聚集与分组操作
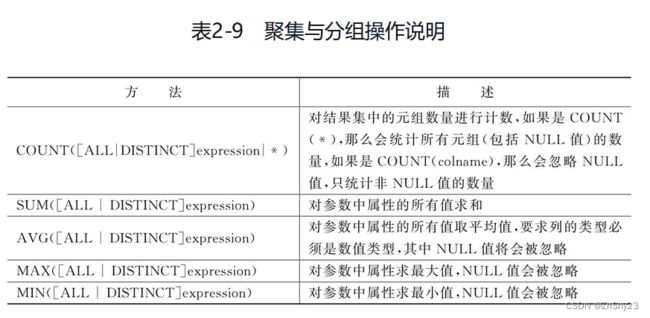
8.1 COUNT - 计数
- 对于
COUNT函数,可以将参数指定为“*”,这样就会统计所有的元组数量,即使元组中包含NULL值,仍然会进行统计。
例2-34: 对t1表的所有元组数量进行统计SELECT COUNT(*) FROM t1; count ------- 3 (1 row) - 如果给
COUNT函数的参数指定为表达式(或列值),则只统计表达式结果为非NULL值的个数。
例2-35: 对t1表的c2列中的非NULL值的个数进行统计SELECT COUNT(c2) FROM t1; count ------- 2 (1 row) - 如果在参数中指定了
DISTINCT关键字,则先对结果中的值去掉重复值,然后再统计数量,如果不指定DISTINCT,则默认为ALL。
**例2-36:**对t1表的c1列中的非NULL值的个数进行统计,去掉重复值。SELECT COUNT(DISTINCT t1.c1) FROM t1; count ------- 2 (1 row)
8.2 SUM - 求和
例2-37: 对表t1的c1列做求和操作。
SELECT SUM(c1) FROM t1;
sum
-----
4
(1 row)
8.3 AVG - 平均值
**例2-38:**对表t1的c1列求平均值。
SELECT AVG(c1) FROM t1;
avg
--------------------
1.3333333333333333
(1 row)
8.4 MAX - 最大值
SELECT MAX(c1) FROM t1;
max
-----
2
(1 row)
8.5 MIN - 最小值
SELECT MIN(c1) FROM t1;
min
-----
1
(1 row)
8.6 GROUP BY - 分组
在实际场景中,可能会统计每个组织所包含的人数,假设有一个组织成员信息表:
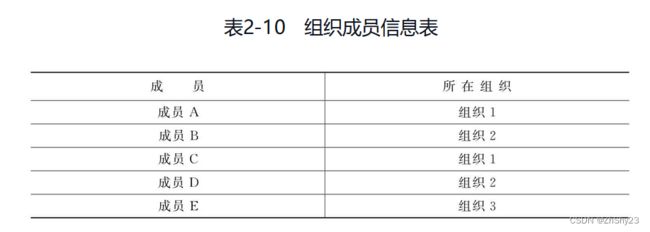
那么要获得每个组织的人数就需要执行多次查询才能实现
SELECT COUNT(*) FROM 成员 WHERE 成员组织 = 1;
SELECT COUNT(*) FROM 成员 WHERE 成员组织 = 2;
...
使用分组方法可以方便地解决这个问题,分组方法使用GROUP BY关键字来指定,通常形式如下:
GROUP BY column1, column2, ...
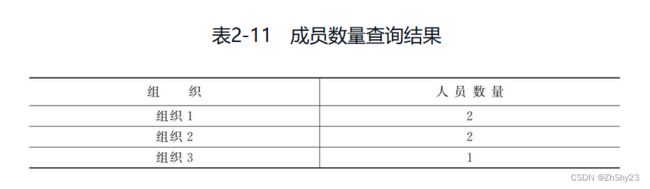
如果要简化上面的多条语句,则可以通过GROUP BY方法来实现,下面的方法可以统计每个组织中成员的数量:
SELECT 组织, COUNT(*) FROM 成员 GROUP BY 成员组织;
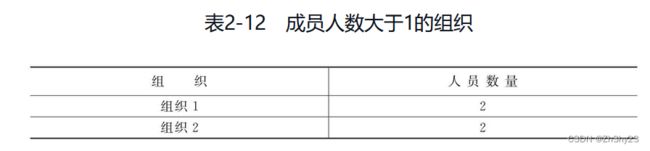
另外还可以考虑使用HAVING操作帮助筛选出符合条件的成员(找出成员人数大于1的成员组织)
SELECT 组织, COUNT(*) FROM 成员 GROUP BY 成员组织 HAVING COUNT(*) > 1;
例2-39: 根据表t1的c2列做分组,求每个分组内c1的个数。
SELECT c2, COUNT(c1) FROM t1 GROUP BY c2;
c2 | count
----+-------
| 1
2 | 2
(2 rows)
例2-40: 根据表t1的c2列做分组,求每个分组内c1的个数,将个数大于1的分组投影出来。
SELECT c2, COUNT(c1) FROM t1 GROUP BY c2 HAVING COUNT(c1) > 1;
c2 | count
----+-------
2 | 2
(1 row)