MySQL表的CURD
CRUD : Create(创建), Retrieve(读取),Update(更新),Delete(删除)
Create
语法
INSERT [INTO] table_name
[(column [, column] ...)]
VALUES (value_list) [, (value_list)] ...
value_list: value, [, value] ...
示例:
-- 创建一张学生表
CREATE TABLE students (
id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT,
sn INT NOT NULL UNIQUE COMMENT '学号',
name VARCHAR(20) NOT NULL,
qq VARCHAR(20)
);
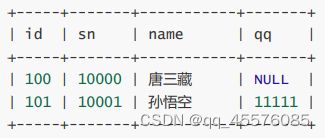
单行数据+全列插入
INSERT INTO students VALUES (100, 10000, '唐三藏', NULL);
INSERT INTO students VALUES (101, 10001, '孙悟空', '11111');
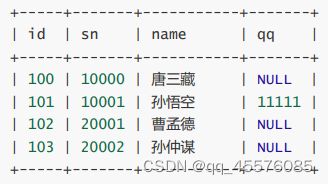
多行数据+指定列插入
INSERT INTO students (id, sn, name)
VALUES (102, 20001, '曹孟德'),
(103, 20002, '孙仲谋');
Retrieve
语法
SELECT
[DISTINCT] {* | {column [, column] ...}
[FROM table_name] [WHERE ...]
[ORDER BY column [ASC | DESC], ...]
LIMIT ...
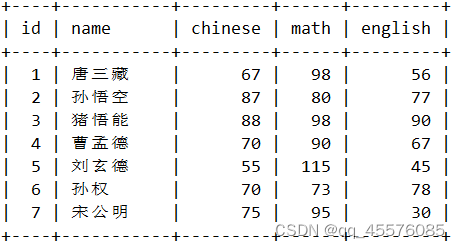
全列查询
SELECT * FROM exam_result;
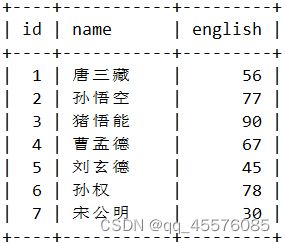
指定列查询
SELECT id, name, english FROM exam_result;
查询字段为表达式
SELECT id, name, math+chinese+english FROM exam_result;

为查询结果指定别名
语法
SELECT column [AS] alias_name [...] FROM table_name;
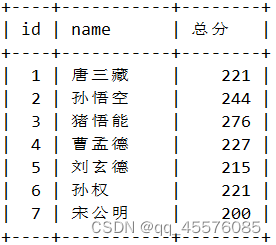
SELECT id, name, math+chinese+english as 总分 FROM exam_result;
查询结果去重
SELECT DISTINCT math FROM exam_result;
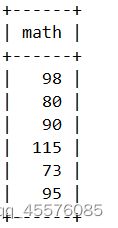
where条件
比较运算符
| 运算符 | 说明 |
| >, >=, <, <= | 大于,大于等于,小于,小于等于 |
| = | 等于,NULL 不安全,例如 NULL = NULL 的结果是 NULL |
| <=> | 等于,NULL 安全,例如 NULL NULL 的结果是 TRUE(1) |
| !=, <> | 不等于 |
| BETWEEN a0 AND a1 | 范围匹配,[a0, a1],如果 a0 <= value <= a1,返回 TRUE(1) |
| IN (option, ...) | 如果是 option 中的任意一个,返回 TRUE(1) |
| IS NULL | 是 NULL |
| IS NOT NULL | 不是 NULL |
| LIKE | 模糊匹配。% 表示任意多个(包括 0 个)任意字符;_ 表示任意一个字符 |
逻辑运算符
| 运算符 | 说明 |
| AND | 多个条件必须都为 TRUE(1),结果才是 TRUE(1) |
| OR | 任意一个条件为 TRUE(1), 结果为 TRUE(1) |
| NOT | 条件为 TRUE(1),结果为 FALSE(0) |
结果排序
语法
-- ASC 为升序(从小到大)
-- DESC 为降序(从大到小)
-- 默认为 ASC
SELECT ... FROM table_name [WHERE ...] ORDER BY column [ASC|DESC], [...];
筛选分页结果
语法
-- 起始下标为 0
-- 从 0 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n;
-- 从 s 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT s, n;
-- 从 s 开始,筛选 n 条结果,比第二种用法更明确,建议使用
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n OFFSET s;
多表查询
内连接

外连接
外连接分为左外连接和右外连接

Update
语法
UPDATE table_name SET column = expr [, column = expr ...]
[WHERE ...] [ORDER BY ...] [LIMIT ...]
Delete
语法
DELETE FROM table_name [WHERE ...] [ORDER BY ...] [LIMIT ...]
聚合函数
| 函数 | 说明 |
| COUNT([DISTINCT] expr) | 返回查询到的数据的 数量 |
| SUM([DISTINCT] expr) | 返回查询到的数据的 总和,不是数字没有意义 |
| AVG([DISTINCT] expr) | 返回查询到的数据的 平均值,不是数字没有意义 |
| MAX([DISTINCT] expr) | 返回查询到的数据的 最大值,不是数字没有意义 |
| MIN([DISTINCT] expr) | 返回查询到的数据的 最小值,不是数字没有意义 |
group by子句的使用
select column1, column2, .. from table group by column;
having和group by配合使用,对group by结果进行过滤
where过滤表中的数据,having过滤分组的数据。先执行where过滤出表中的数据,再对过滤出的数据进行分组,其次执行查询的列名,最后执行having子句进行最后的数据过滤。