sparkCore-核心、算子、持久化算子
一、Spark核心
1.RDD
1)概念:
RDD(Resilient Distributed Dateset),弹性分布式数据集
2)RDD的五大特性
1.RDD是由一系列的partition组成的。
2.函数是作用在每一个partition(split)上的。
3.RDD之间有一系列的依赖关系。
4.分区器是作用在K,V格式的RDD上的。
5.RDD提供一系列最佳的计算位置。
3)RDD的理解图:
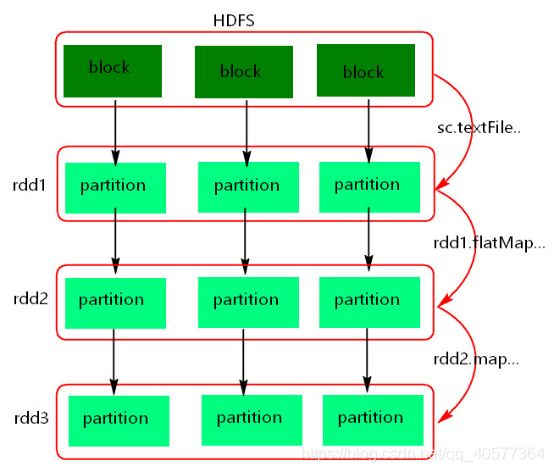
4)注意:
1.textFile方法底层封装的是读取MR读取文件的方式,读取文件之前先split,默认split大小为一个block大小。
2.RDD实际上不存储数据,为了方便理解,暂时理解为存储数据。
3.什么是K,V格式的RDD?
如果RDD里面存储的数据都是二元组对象,那么就将这个RDD称为K,V格式的RDD。
4.哪里体现RDD的弹性(容错)?
partition数量,大小没有限制,体现了RDD的弹性(容错)
RDD之间存在依赖关系,可以基于上一个RDD重新计算出RDD。
5.哪里体现RDD的分布式?
RDD是由partition组成的,partitiong是分部在不同节点上的。
6.RDD提供计算最佳位置,体现了数据本地化,体现了大数据中“计算移动数据不移动”的理念。
2.Java和Scala中创建RDD的方式
Java:
sc.textFile("./xxx",numPartitions) //其中./xxx表示文件存储位置,numPartitions表示分区数
sc.paralleliza(集合,num)
sc.parallelizaPairs(Tuple2集合,num)
Scala:
sc.textFile("./xxx",numPartitions) //其中./xxx表示文件存储位置,numPartitions表示分区数
sc.paralleliza(集合,num)
sc.makeRDD(集合,num)
3.Spark执行任务的原理
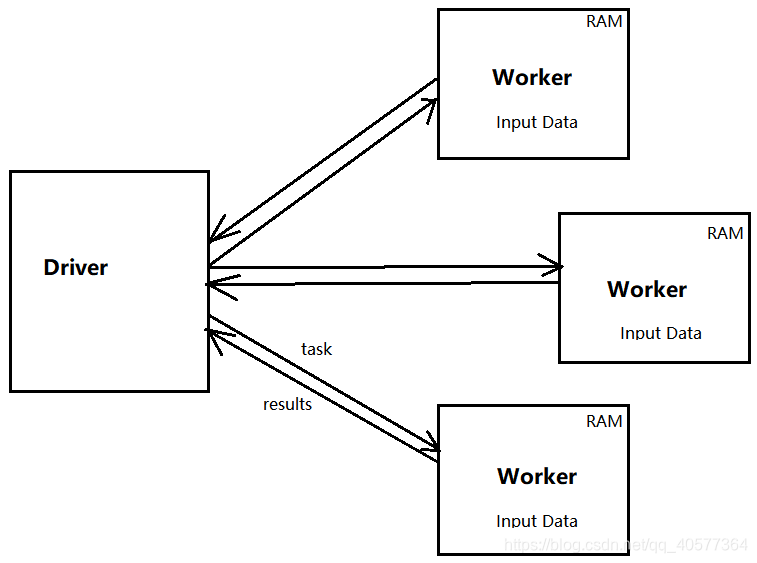
如上图:有四个机器节点,Driver和Worker是启动在节点上的进程,运行在JVM中的进程。
1.Driver与集群节点之间有频繁的通信。
2.Driver负责任务(tasks)的分发和结果的回放。任务的调度。如果task的计算结果非常大就不需要回收,如果回收,会造成oom。
3.Worker是Standalone资源调度框架里面资源管理的从节点。也是JVM的进程。
4.Master是Standalone资源调度框架里面资源管理的主节点。也是JVM的进程。
二、Spark转换算子和行动算子
1.Transformations转换算子
1)概念
Tansformations类算子是一类算子(函数),叫做转换算子,如:map,flatMap,reduceByKey等。
Transformations算子是延迟执行,也叫懒加载执行。
2)Transformations类算子
filter:过滤符合条件的记录数,true保留,false过滤掉
val rdd1 = sc.parallelize(List[String]("java","java","spark","hadoop","hive"))
rdd1.filter(word=>"hive".equals(word)).foreach(println)
结果打印输出为:
hive
map:将一个RDD中的每个数据项,通过map中的函数映射变为一个新的元素。特点:输入一条,输出一条数据。
val rdd1 = sc.parallelize(List[String]("java","java","spark","hadoop","hive"))
rdd1.map(word=>{"hello "+ word}).foreach(println)
输出结果为:
hello java
hello java
hello spark
hello hadoop
hello hive
flatMap:先map后flat。与map类似,每个输入项可以映射为0到多个输出项。
val rdd1 = sc.parallelize(List[String]("java spark hadoop hive sqoop"))
rdd1.flatMap(word=>word.split(" "))foreach(println)
输出结果为:
java
spark
hadoop
hive
sqoop
sample:随机抽样算子,根据传进去的小数按比例进行有放回或者无放回的抽样。
sample(有无放回抽样,抽样比例,抽样种子): 抽样种子是将第一次抽样的种子作为后面每次抽样的种子,进而保证抽样最终得到的结果保持不变
val rdd1 = sc.parallelize(List[Int](1,2,3,4,5,6,7,8,9,10))
rdd1.sample(true,0.5,10L).foreach(println)
输出结果为:
2
7
9
9
reduceByKey:将相同的key根据相应的逻辑进行处理。
val rdd1 = sc.parallelize(List[(String, Int)](
("1", 10),
("1", 20),
("2", 18),
("3", 10),
("3", 30),
("4", 18)
))
rdd1.reduceByKey((v1,v2)=>{v1+v2}).foreach(println)
输出结果为:
(4,18)
(2,18)
(3,40)
(1,30)
sortByKey/sortBy:作用在K,V格式的RDD上,对key进行升序或者降序排序
sortByKey:
val rdd1 = sc.parallelize(List[(String, Int)](
("1", 10),
("1", 20),
("2", 18),
("3", 10),
("3", 30),
("4", 18)
))
rdd1.sortByKey(true).foreach(println) //参数true为升序排序
输出结果为:
(1,10)
(1,20)
(2,18)
(3,10)
(3,30)
(4,18)
sortBy:
val rdd1 = sc.parallelize(List[(String, Int)](
("1", 10),
("1", 20),
("2", 18),
("3", 10),
("3", 30),
("4", 18)
))
rdd1.sortBy(_._2,true).foreach(println) //通过value值进行升序排序
2.Action行动算子
1.概念:
Action类算子也是一类算子(函数)叫做行动算子。
如:foreach,collect,count等。
Transformations类算子是延迟执行的,Action类算子是触发执行。一个application应用程序中有几个Action类算子执行,就有几个job运行。
2.Action类算子
count:返回数据集中的元素。会在结果计算完成后回收到Driver端。
val rdd1 = sc.parallelize(List[Int](1,2,3,4,5,6,7,8,9,10))
println(rdd1.count())
输出结果为:
10
take(n):返回一个包含数据集前n个元素的集合。
val rdd1 = sc.parallelize(List[Int](1,2,3,4,5,6,7,8,9,10))
rdd1.take(4).foreach(println)
输出结果为:
1
2
3
4
first:first=take(1),返回数据集中的第一个元素。
foreach:遍历循环数据集中的元素,运行响应的逻辑
collect:将计算结果返回给Driver端
三、Spark持久化算子
1.控制算子
概念:
控制算子有三种,cache,persist,checkpoint,以上算子都可以讲RDD持久化,持久化的单位是partition。
cache和persist都是懒执行的。必须有一个action类算子触发执行。
checkpoint算子不仅能将RDD持久化到磁盘,还能切断RDD之间的依赖关系。
cache:默认将RDD中的数据持久化到内存中。cache是懒执行。
注意:cache() = persist() = persist(StorageLevel.Memory_Only)
persist:可以指定持久化的级别。最常用的是MEMORY_ONLY和MEMORY_AND_DISK."_2"表示有副本数。
2.cache和persist的注意事项
1.cache和persist都是懒执行,必须有一个action类算子触发执行。
2.cache和persist算子的返回值可以赋值给一个变量,在其他job中之季节使用这个这个变量就是使用持久化数据了。
持久化的单位是partition。
3.cache和persist算子后不能立即紧跟action算子。
错误:rdd.cache().count() 返回的不是持久化的RDD,而是一个数值了。
4.cache和persist算子持久化的数据,当application执行完成后会被清除。
3.checkpoint:checkpoint将RDD持久化到磁盘,还可以切断RDD之间的依赖关系。checkpoint目录数,当application执行完成后,不会被清除。
1) persist(StorageLevel.DISK_ONLY)与Checkpoint的区别?
a).checkpoint需要指定额外的目录存储数据,checkpoint数据是由外部的存储系统管理,不是Spark框架管理,当application完成之后,不会被清空。
b).cache()和persist()持久化的数据是由Spark框架管理,当application完成之后,会被清空。
c).checkpoint多用于保存状态。
2) checkpoin的执行原理
a).当RDD的job执行完成后,会从finalRDD从后往前回溯。
b).当回溯到某一个RDD调用了checkpoint方法,会对当前的RDD做一个标记。
c).Spark框架会自动启动一个新的job,重新计算这个RDD的数据,将数据持久化到HDFS上。
3) checkpoint的优点:
对RDD执行checkpoint之前,最好对这个RDD先执行cache,这样新启动的job只需要将内存中的数据拷贝到HDFS上即可,省去了重新计算。