ClickHouse MergeTree原理解析
1、MergeTree的创建方式与存储结构
MergeTree在写入一批数据时,数据总会以数据片段的形式写入磁盘,且数据片段不可修改。为了避免片段过多,ClickHouse会通过后台线程,定期合并这些数据片段,属于相同分区的数据片段会被合并成一个新的片段。这种数据片段往复合并的特点,也正是合并树名称的由来
1)、MergeTree的创建方式
创建MergeTree数据表的完整语法如下所示:
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],
...
INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1,
INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2
) ENGINE = MergeTree()
ORDER BY expr
[PARTITION BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[TTL expr [DELETE|TO DISK 'xxx'|TO VOLUME 'xxx'], ...]
[SETTINGS name=value, ...]
几个重要的参数:
- PARTITION BY【选填】:分区键,用于指定数据以何种标准进行分区。分区键可以是单个列字段、元组形式的多个列字段、列表达式。如果不声明分区键,则ClickHouse会生成一个名为all的分区。合理使用数据分区,可以有效减少查询时数据文件的扫描范围
- ORDER BY【必填】:排序键,用于指定在一个数据片段内,数据以何种标准排序。默认情况下主键(PRIMARY KEY)与排序键相同。排序键可以是单个列字段(例:
ORDER BY CounterID)、元组形式的多个列字段(例:ORDER BY (CounterID,EventDate))。当使用多个列字段排序时,以ORDER BY (CounterID,EventDate)为例,在单个数据片段内,数据首先以CounterID排序,相同CounterID的数据再按EventDate排序 - PRIMARY KEY【选填】:主键,生成一级索引,加速表查询。默认情况下,主键与排序键(ORDER BY)相同,所以通常使用ORDER BY代为指定主键。一般情况下,在单个数据片段内,数据与一级索引以相同的规则升序排序。与其他数据库不同,MergeTree主键允许存在重复数据
- SAMPLE BY【选填】:抽样表达式,用于声明数据以何种标准进行采样。抽样表达式需要配合SAMPLE子查询使用
- SETTINGS:index_granularity【选填】:索引粒度,默认值8192。也就是说,默认情况下每隔8192行数据才生成一条索引
- SETTINGS:index_granularity_bytes【选填】:在19.11版本之前,ClickHouse只支持固定大小的索引间隔(index_granularity)。在新版本中增加了自适应间隔大小的特性,即根据每一批次写入数据的体量大小,动态划分间隔大小。而数据的体量大小,由index_granularity_bytes参数控制,默认10M
- SETTINGS:enable_mixed_granularity_parts【选填】:设置是否开启自适应索引间隔的功能,默认开启
2)、MergeTree的存储结构
MergeTree的存储结构如下图所示:

如上图,一张数据表的完整物理结构分为3个层级,依次是数据表目录、分区目录及各分区下具体的数据文件
- partition:分区目录,余下各类数据文件都是以分区目录的形式被组织存放的,属于相同分区的数据最终会被合并到同一个分区目录
- checksums.txt:校验文件,使用二进制格式存储。它保存了余下各类文件的size大小及size的哈希值,用于快速校验文件的完整性和正确性
- columns.txt:列信息文件,使用明文格式存储。用于保存此数据分区下的列字段信息
- count.txt:计数文件,使用明文格式存储。用于记录当前数据分区目录下数据的总行数
- primary.idx:一级索引文件,使用二进制格式存储。用于存放稀疏索引,一张MergeTree表只能声明一次一级索引(通过ORDER BY或PRIMARY KEY)
- [Column].bin:数据文件,使用压缩格式存储,默认为LZ4压缩格式,用于存放某一列的数据。由于MergeTree采用列式存储,所以每一个列字段都拥有独立的.bin数据文件,并以列字段名称命名
- [Column].mrk:列字段标记文件,使用二进制格式存储。标记文件中保存了.bin文件中数据的偏移量信息。标记文件与稀疏索引对齐,又与.bin文件一一对应,所以MergeTree通过标记文件建立了primary.idx稀疏索引与.bin数据文件之间的映射关系。首先通过稀疏索引(primary.idx)找到对应数据的偏移量信息(.mrk),再通过偏移量直接从.bin文件中读取数据。由于.mrk标记文件与.bin文件一一对应,所以MergeTree中的每个列字段都会拥有与其对应的.mrk标记文件
- [Column].mrk2:如果使用了自适应大小的索引间隔,则标记文件会以.mrk2命名。它的工作原理和作用与.mrk标记文件相同
- partition.dat与
minmax_[Column].idx:如果使用了分区键,则会额外生成partition.dat与minmax索引文件,它们均使用二进制格式存储。partition.dat用于保存当前分区下分区表达式最终生成的值;而minmax索引用于标记当前分区下分区字段对应原始数据的最小和最大值。例如EventTime字段对应的原始数据为2019-05-01、2019-05-05,分区表达式为PARTITION BY toYYYYMM(EventTime)。partition.dat中保存的值将会是2019-05,而minmax索引中保存的值将会是2019-05-012019-05-05。在这些分区索引的作用下,进行数据查询时能够快速跳过不必要的数据分区目录,从而减少最终需要扫描的数据范围 skp_idx_[Column].idx与skp_idx_[Column].mrk:如果在建表语句中声明了二级索引,则会额外生成相应的二级索引与标记文件,它们同样也使用二进制存储
2、数据分区
在MergeTree中,数据是以分区目录的形式进行组织的,每个分区独立分开存储。借助这种形式,在对MergeTree进行数据查询时,可以有效跳过无用的数据文件,只使用最小的分区目录子集
1)、数据的分区规则
MergeTree数据分区的规则由分区ID决定,而具体到每个数据分区所对应的ID,则是由分区键的取值决定的。分区键支持使用任何一个或一组字段表达式声明,其业务语义可以是年、月、日或者组织单位等任何一种规则。针对取值数据类型的不同,分区ID的生成逻辑目前拥有四种规则:
- 不指定分区键:如果不使用分区键,即不使用PARTITION BY声明任何分区表达式,则分区ID默认取名为all,所有的数据都会被写入这个all分区
- 使用整型:如果分区键取值属于整型(兼容UInt64,包括有符号整型和无符号整型),且无法转换为日期类型YYYYMMDD格式,则直接按照该整型的字符形式输出,作为分区ID的取值
- 使用日期类型:如果分区键取值属于日期类型,或者是能够转换为YYYYMMDD格式的整型,则使用按照YYYYMMDD进行格式化后的字符形式输出,并作为分区ID的取值
- 使用其他类型:如果分区键取值既不属于整型,也不属于日期类型,例如String、Float等,则通过128位Hash算法取其Hash值作为分区ID的取值
分区ID在不同规则下的示例如下图:
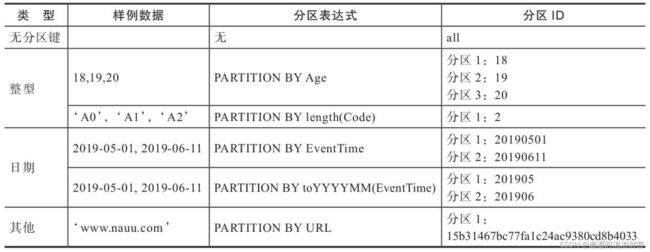
如果通过元组的方式使用多个分区字段,则分区ID依旧是根据上述规则生成的,只是多个ID之间通过-符号依次拼接。例如按照上述表格中的例子,使用两个字段分区:PARTITION BY (length(Code),EventTime)
则最终的分区ID会是下面的模样:
2-20190501
2-20190611
2)、分区目录的命名规则
一个完整分区目录的命名公式:PartitionID_MinBlockNum_MaxBlockNum_Level

- PartitionID:分区ID
- MinBlockNum与MaxBlockNum:最小数据块编号与最大数据块编号。这里的BlockNum是一个整型的自增长编号。如果将其设为n的话,那么计数n在单张MergeTree数据表内全局累加,每当新创建一个分区目录时,计数n就会+1。对于一个新的分区目录而言,MinBlockNum与MaxBlockNum取值一样,同等于n,例如201905_1_1_0、201906_2_2_0以此类推。当分区目录发生合并时,对于新产生的合并目录MinBlockNum与MaxBlockNum有着另外的取值规则
- Level:合并的层级,可以理解为某个分区被合并过的次数。对于每一个新创建的分区目录而言,其初始值均为0。以分区为单位,如果相同分区发生合并动作,则在相应分区内计数+1
3)、分区目录的合并过程
MergeTree的分区目录是在数据写入过程中被创建的。伴随着每一批数据的写入(一次INSERT语句),MergeTree都会生成一批新的分区目录。即便不同批次写入的数据属于相同分区,也会生成不同的分区目录。也就是说,对于同一个分区而言,也会存在多个分区目录的情况。在之后的某个时刻(写入后的10~15分钟,也可以手动执行optimize语句),ClickHouse会通过后台任务再将属于相同分区的多个目录合并成一个新的目录。已经存在的旧分区目录并不会立即被删除,而是在之后的某个时刻通过后台任务被删除(默认8分钟)
属于同一个分区的多个目录,在合并之后会生成一个全新的目录,目录中的索引和数据文件也会相应地进行合并。新目录名称的合并方式遵循以下规则:
- MinBlockNum:取同一分区内所有目录中最小的MinBlockNum值
- MaxBlockNum:取同一分区内所有目录中最大的MaxBlockNum值
- Level:取同一分区内最大Level值+1
分区目录的合并过程:
1)T0时刻
partition_v5表按日志字段格式分区,即PARTITION BY toYYYYMM(EventTime)。在T0时刻,分3批(3次INSERT语句)写入3条数据
INSERT INTO partition_v5 VALUES (A, c1, '2019-05-01');
INSERT INTO partition_v5 VALUES (B, c1, '2019-05-02');
INSERT INTO partition_v5 VALUES (C, c1, '2019-06-01');
上述INSERT语句会创建3个分区目录。分区目录的名称由PartitionID、MinBlockNum、MaxBlockNum和Level组成。PartitionID依次为201905、201905和201906。而对于每个新建的分区目录而言,它们的MinBlockNum与MaxBlockNum取值相同,均来源于表内全局自增的BlockNum。BlockNum初始为1,每次新建目录后累计加1。所以,3个分区目录的MinBlockNum与MaxBlockNum依次为0_0、1_1和2_2。最后是Level层级,每个新建的分区目录初始Level都是0。所以3个分区目录的最终名称分别是201905_1_1_0、201905_2_2_0和201906_3_3_0
2)T1时刻
假设在T1时刻,MergeTree的合并动作开始了,那么属于同一分区的201905_1_1_0与201905_2_2_0目录将发生合并。MinBlockNum取同一分区内所有目录中最小的MinBlockNum值,所以是1;MaxBlockNum取同一分区内所有目录中最大的MaxBlockNum值,所以是2;而Level则取同一分区内,最大Level值加1,所以是1。所以合并完成后生成一个新的分区201905_1_2_1
下图描述MergeTree分区目录从创建、合并到删除的整个过程:
从上图中可以发现,分区目录在发生合并之后,旧的分区目录并没有被立即删除,而是会存留一段时间。但是旧的分区目录已不再是激活状态(active=0),所以在数据查询时,它们会被自动过滤掉
3、一级索引
MergeTree的主键使用PRIMARY KEY定义,待主键定义之后,MergeTree会依据index_granularity间隔(默认8192行),为数据表生成一级索引并保存至primary.idx文件内,索引数据按照PRIMARY KEY排序。相比使用PRIMARY KEY定义,更为常见的是通过ORDER BY指代主键。在此种情形下,PRIMARY KEY与ORDER BY定义相同,所以索引(primary.idx)和数据(.bin)会按照完全相同的规则排序
1)、稀疏索引
primary.idx文件内的一级索引采用稀疏索引实现
稀疏索引与稠密索引的区别:

在稠密索引中每一行索引标记都会对应到一行具体的数据记录
而在稀疏索引中,每一行索引标记对应的是一段数据,而不是一行。由于稀疏索引占用空间小,所以primary.idx内的索引数据常驻内存
2)、索引粒度
index_granularity表示索引的粒度,默认8192

数据以index_granularity的粒度被标记成多个小的区间,其中每个区别最多index_granularity行数据。MergeTree使用MarkRange表示一个具体的区间,并通过start和end表示其具体的范围
3)、索引数据的生成规则
由于是稀疏索引,所以MergeTree需要间隔index_granularity行数据才会生成一条索引记录,其索引值会依据声明的主键字段获取
1)使用CounterID作为主键

该表使用年月分区(PARTITION BY toYYYYMM(EventDate)),所以2014年3月份的数据最终会被划分到同一个分区目录内。如果使用CounterID作为主键(ORDER BY CounterID),则每间隔8192行数据就会取一次CounterID的值作为索引值,索引数据最终会被写入primary.idx文件进行保存
例如第0( 8192 ∗ 0 8192*0 8192∗0)行CounterID取值57,第8192( 8192 ∗ 1 8192*1 8192∗1)行CounterID取值1635,而第16384( 8192 ∗ 2 8192*2 8192∗2)行CounterID取值3266,最终索引数据将会是5716353266
2)使用CounterID和EventDate作为主键

如果使用多个主键,例如ORDER BY(CounterID,EventDate),则每间隔8192行可以同时取CounterID与EventDate两列的值作为索引值,如上图所示
4)、索引的查询过程
假设现在有一份测试数据,共192行记录。其中,主键ID为String类型,ID的取值从A000开始,后面依次为A001、A002……直到A192为止。MergeTree的索引粒度index_granularity=3,根据索引的生成规则,primary.idx文件内的索引数据如下图所示:

根据索引数据,MergeTree会将此数据片段划分为 192 / 3 = 64 192/3=64 192/3=64个小的MarkRange,两个相邻MarkRange相距的步长为1。其中,所有MarkRange(整个数据片段)的最大数值区间为[A000, +inf),如下图所示:

索引查询其实就是两个数值区间的交集判断。其中,一个区间是由基于主键的查询条件转换而来的条件区间;而另一个区间是与MarkRange对应的数值区间
整个索引查询过程可以大致分为3个步骤:
1)生成查询条件区间
首先,将查询条件转换为条件区间,例如下面的例子
WHERE ID = 'A003'
['A003', 'A003']
WHERE ID > 'A000'
('A000', +inf)
WHERE ID < 'A188'
(-inf, 'A188')
WHERE ID LIKE 'A006%'
['A006', 'A007')
2)递归交集判断
以递归的形式,依次对MarkRange的数值区间与条件区间做交集判断。从最大区间[A000, +inf)开始
- 如果不存在交集,则直接通过剪枝算法优化此整段MarkRange
- 如果存在交集,且MarkRange步长大于8(end-start),则将此区间进一步拆分成8个子区间(merge_tree_coarse_index_granularity指定,默认值为8),并重复此规则,继续做递归交集判断
- 如果存在交集,且MarkRange不可再分解(步长小于8),则记录MarkRange并返回
3)合并MarkRange区间
将最终匹配的MarkRange聚在一起,合并它们的范围

MergeTree通过递归的形式持续向下拆分区间,最终将MarkRange定位到最细的粒度,以帮助在后续读取数据的时候,能够最小化扫描数据的范围。以上图为例,当查询条件WHERE ID='A003'的时候,最终只需要读取[A000, A003]和[A003, A006]两个区间的数据,它们对应MarkRange(start:0,end:2)范围,而其他无用的区间都被裁剪掉了。因为MarkRange转换的数值区间是闭区间,所以会额外匹配到临近的一个区间
4、二级索引
除了一级索引之外,MergeTree同样支持二级索引。二级索引又称跳数索引,由数据的聚合信息构建而成
跳数索引在默认情况下是关闭的,需要设置allow_experimental_data_skipping_indices(该参数在新版本中已被取消)才能使用:
SET allow_experimental_data_skipping_indices = 1
与一级索引一样,如果在建表语句中声明了跳数索引,则会额外生成相应的索引与标记文件(skp_idx_[Column].idx与skp_idx_[Column].mrk)
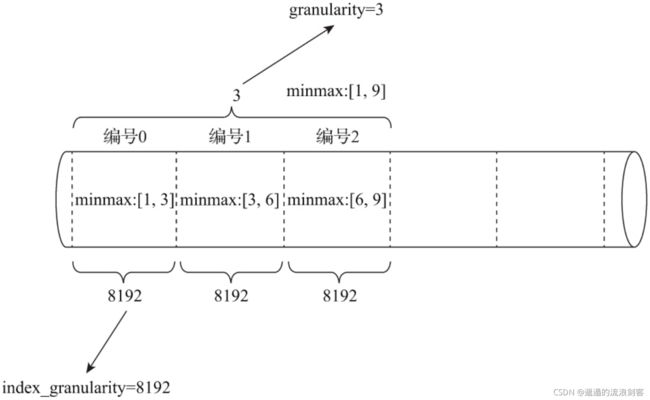
1)、granularity与index_granularity的关系
对于跳数索引而言,index_granularity定义了数据的粒度,而granularity定义了聚合信息汇总的粒度。granularity定义了一行跳数索引能够跳过多少个index_granularity区间的数据
跳数索引的数据生成规则:首先,按照index_granularity粒度间隔将数据划分为n段,总共有[0, n-1]个区间( n = t o t a l r o w s / i n d e x g r a n u l a r i t y n=total_rows/index_granularity n=totalrows/indexgranularity,向上取整)。接着,根据索引定义时声明的表达式,从0区间开始,依次按index_granularity粒度从数据中获取聚合信息,每次向前移动1步,聚合信息逐步累加。最后,当移动granularity次区间时,则汇总并生成一行跳数索引数据
以minmax索引为例,它的聚合信息是在一个index_granularity区间内数据的最小和最大极值。以下图为例,假设index_granularity=8192且granularity=3,则数据会按照index_granularity划分为n等份,MergeTree从第0段分区开始,依次获取聚合信息。当获取到第3个分区时(granularity=3),则汇总并会生成第一行minmax索引(前3段minmax极值汇总后取值为[1, 9])
2)、跳数索引的类型
1)minmax:minmax索引记录了一段数据内的最小和最大极值,其索引的作用类似分区目录的minmax索引,能够快速跳过无用的数据区间
INDEX a ID TYPE minmax GRANULARITY 5
上述示例中minmax索引会记录这段数据区间内ID字段的极值。极值的计算涉及每5个index_granularity区间中的数据
2)set:set索引直接记录了声明字段或表达式的取值(唯一值,无重复),其完整形式为set(max_rows),其中max_rows是一个阈值,表示在一个index_granularity内,索引最多记录的数据行数。如果max_rows=0,则表示无限制
INDEX b(length(ID) * 8) TYPE set(100) GRANULARITY 5
上述示例中set索引会记录数据中ID的长度*8后的取值。其中,每个index_granularity内最多记录100条
3)ngrambf_v1:ngrambf_v1索引记录的是数据短语的布隆表过滤器,只支持String和FixedString数据类型。ngrambf_v1只能够提升in、 notIn、like、equals和notEquals查询的性能,其完整形式为ngrambf_v1(n,size_of_bloom_filter_in_bytes,number_of_hash_functions,random_seed)。具体的含义如下:
- n:token长度,依据n的长度将数据切割为token短语
- size_of_bloom_filter_in_bytes:布隆过滤器的大小
- number_of_hash_functions:布隆过滤器中使用Hash函数的个数
- random_seed:Hash函数的随机种子
INDEX c(ID,Code) TYPE ngrambf_v1(3, 256, 2, 0) GRANULARITY 5
例如在上面例子中,ngrambf_v1索引会依照3的粒度将数据切割成短语token,token会经过2个Hash函数映射后再被写入,布隆过滤器大小为256字节
4)tokenbf_v1:tokenbf_v1索引是ngrambf_v1的变种,同样也是一种布隆过滤器索引。tokenbf_v1除了短语token的处理方法外,其他与ngrambf_v1是完全一样的。tokenbf_v1会自动按照非字符的、数字的字符串分割token,具体用法如下所示:
INDEX d ID TYPE tokenbf_v1(256, 2, 0) GRANULARITY 5
5、数据存储
1)、各列独立存储
在MergeTree中,数据按列存储。而具体到每个列字段,数据也是独立存储的,每个列字段都拥有一个与之对应的.bin数据文件。数据文件以分区目录的形式被组织存放,所以在.bin文件中只会保存当前分区片段内的这一部分数据。按列独立存储的设计优势显而易见:一是可以更好地进行数据压缩(相同类型的数据放在一起,对压缩更加友好),二是能够最小化数据扫描的范围
数据是经过压缩的,目前支持LZ4、ZSTD、Multiple和Delta几种算法,默认使用LZ4算法;其次,数据会事先依照ORDER BY的声明排序;最后,数据是以压缩数据块的形式被组织并写入.bin文件中的
2)、压缩数据块
一个压缩数据块由头信息和压缩数据两部分组成。头信息固定使用9位字节表示,具体由1个UInt8(1字节)整型和2个UInt32(4字节)整型组成,分别代表使用的压缩算法类型、压缩后的数据大小和压缩前的数据大小,如下图所示:

MergeTree在数据具体的写入过程中,会按照索引粒度(默认情况下,每次取8192行),按批次获取数据并进行处理。如果把一批数据的未压缩大小设为size,则整个写入过程遵循以下规则:
1)单个批次数据size < 64KB:如果单个批次数据小于64KB,则继续获取下一批数据,直至累积到size >= 64KB时,生成下一个压缩数据块
2)单个批次数据64KB <= size <= 1MB:如果单个批次数据大小恰好在64KB与1MB之间,则直接生成下一个压缩数据块
3)单个批次数据size > 1MB:如果单个批次数据直接超过1MB,则首先按照1MB大小截断并生成下一个压缩数据块。剩余数据继续依照上述规则执行。此时,会出现一个批次数据生成多个压缩数据块的情况
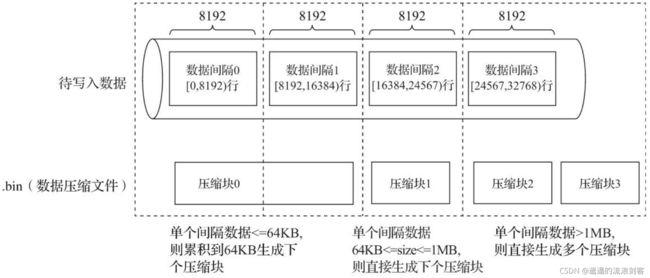
一个.bin文件是由1至多个压缩数据块组成的,每个压缩块大小在64KB~1MB之间。多个压缩数据块之间,按照写入顺序首尾相接,紧密地排列在一起
6、数据标记
1)、数据标记的生成规则

从上图中可以发现,数据标记和索引区间是对齐的,均按照index_granularity的粒度间隔
数据标记文件与.bin文件一一对应,每一个列字段[Column].bin文件都有一个与之对应的[Column].mrk数据标记文件,用于记录数据在.bin文件中的偏移量信息
一行标记数据使用一个元组表示,元组内包含两个整型数值的偏移量信息。它们分别表示此段数据区间内,在对应的.bin压缩文件中,压缩数据块的起始偏移量;以及将该数据压缩块解压后,其未压缩数据的起始偏移量

每一行标记数据都表示了一个片段的数据(默认8192行)在.bin压缩文件中的读取位置信息。标记数据与一级索引数据不同,它并不能常驻内存,而是使用LRU(最近最少使用)缓存策略加快其取用速度
2)、数据标记的工作方式
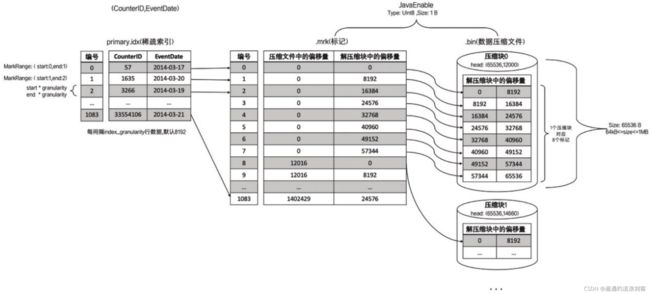
下图为为hits_v1测试表的JavaEnable字段及其标记数据与压缩数据的对应关系:
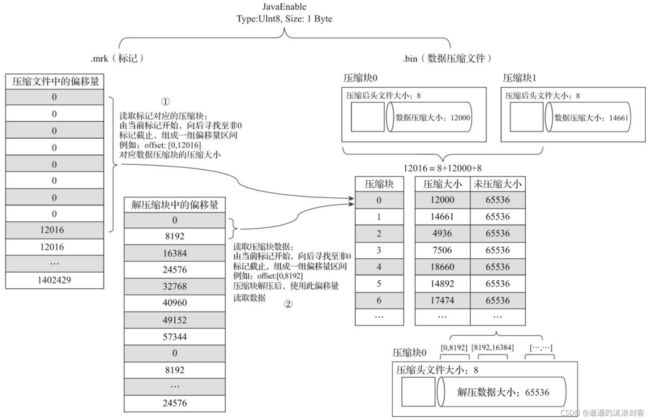
JavaEnable字段的数据类型为UInt8,所以每行数值占用1字节。而hits_v1数据表的index_granularity粒度为8192,所以一个索引片段的数据大小恰好是8192B。按照压缩数据块的生成规则,如果单个批次数据小于64KB,则继续获取下一批数据,直至累积到size >= 64KB时,生成下一个压缩数据块。因此在JavaEnable的标记文件中,每8行标记数据对应1个压缩数据块(1B*8192=8192B,64KB=65536B,65536/8192=8)。所以,从上图能够看到,其左侧的标记数据中,8行数据的压缩文件偏移量都是相同的,因为这8行标记都指向了同一个压缩数据块。而在这8行的标记数据中,它们的解压缩数据块中的偏移量,则依次按照8192B(每行数据1B,每一个批次8192行数据)累加,当累加达到65536(64KB)时则置0。因为根据规则,此时会生成下一个压缩数据块
1)读取压缩数据块
上下相邻的两个压缩文件中的起始偏移量,构成了与获取当前标记对应的压缩数据块的偏移量区间。由当前标记数据开始,向下寻找,直到找到不同的压缩文件偏移量为止。此时得到的一组偏移量区间即时压缩数据块在.bin文件中的偏移量。如上图所示,读取右侧.bin文件中[0, 12016](8+12000+8=12016)字节数据,就能获得第0个压缩数据块
压缩数据块被整个加载到内存之后,会进行解压,在这之后就进入具体数据的读取环节了
2)读取数据
在读取解压后的数据时,MergeTree并不需要一次性扫描整段解压数据,它可以根据需要,以index_granularity的粒度加载特定的一小段
上下相邻两个解压缩数据块中的起始偏移量,构成了与获取当前标记对应的数据的偏移区间。通过这个区间能够在它的压缩块被解压之后,依照偏移量按需读取数据,如上图所示,通过[0, 8192]能够读取压缩数据块0中的第一个数据片段
7、小结
1)、写入过程
数据写入的第一步是生成分区目录,伴随着每一批数据的写入,都会生成一个新的分区目录。在后续的某一时刻,属于相同分区的目录会依照规则合并到一起;接着,按照index_granularity索引粒度,会分别生成primary.idx一级索引(如果声明了二级索引,还会创建二级索引文件)、每一个列字段的.mrk数据标记和.bin压缩数据文件

从分区目录201403_1_34_3能够得知,该分区数据共分34批写入,期间发生过3次合并。在数据写入的过程中,依据index_granularity的粒度,依次为每个区间的数据生成索引、标记和压缩数据块
2)、查询过程
在最理想的情况下,MergeTree首先可以依次借助分区索引、一级索引和二级索引,将数据扫描范围缩至最小。然后再借助数据标记,将需要解压与计算的数据范围缩至最小

如果一条查询语句没有指定任何WHERE条件,或是指定了WHERE条件,但条件没有匹配到任何索引(分区索引、一级索引和二级索引),那么MergeTree就不能预先减小数据范围。在后续进行数据查询时,它会扫描所有分区目录,以及目录内索引段的最大区间。虽然不能减少数据范围,但是MergeTree仍然能够借助数据标记,以多线程的形式同时读取多个压缩数据块,以提升性能
3)、数据标记与压缩数据块的对应关系
由于压缩数据块的划分,与一个间隔(index_granularity)内的数据大小相关,每个压缩数据块的体积都被严格控制在64KB~1MB。而一个间隔(index_granularity)的数据,又只会产生一行数据标记。那么根据一个间隔内数据的实际字节大小,数据标记和压缩数据块之间会产生三种不同的对应关系
1)多对一
多个数据标记对应一个压缩数据块,当一个间隔(index_granularity)内的数据未压缩大小size小于64KB时,会出现这种对应关系
以hits_v1测试表的JavaEnable字段为例。JavaEnable数据类型为UInt8,大小为1B,则一个间隔内数据大小为8192B。所以在此种情形下,每8个数据标记会对应同一个压缩数据块
2)一对一
一个数据标记对应一个压缩数据块,当一个间隔(index_granularity)内的数据未压缩大小size大于等于64KB且小于等于
1MB时,会出现这种对应关系
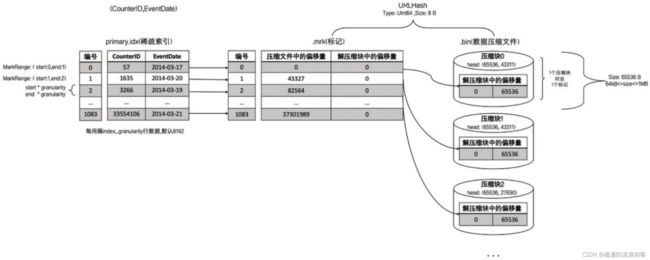
以hits_v1测试表的URLHash字段为例。URLHash数据类型为UInt64,大小为8B,则一个间隔内数据大小为65536B,恰好等于64KB。所以在此种情形下,数据标记与压缩数据块是一对一的关系
3)一对多
一个数据标记对应多个压缩数据块,当一个间隔(index_granularity)内的数据未压缩大小size直接大于1MB时,会出现
这种对应关系
以hits_v1测试表的URL字段为例。URL数据类型为String,大小根据实际内容而定

参考:
《ClickHouse原理解析与应用实践》