自学Python 69 Selenium八大元素定位方法(新版BY方法)
Python Selenium八大元素定位方法(新版BY方法)
文章目录
- Python Selenium八大元素定位方法(新版BY方法)
- 前言
- 一、常用的八种定位方法(新旧对比)
- 二、查看网页元素
- 三、八大元素定位示例
-
- 1、id定位
- 2、name定位
- 3、class定位
- 4、tag定位
- 5、link定位
- 6、partial_link定位
- 7、xpath定位
- 8、CSS定位
前言
在学习使用Selenium对网页元素进行定位时,发现很多教程依然使用老版的元素定位方法,但是对于新版selenium来说,已经弃用了之前的元素定位方法,所以在使用的时候会发现有报错,会被一条横线划掉。所以今天来总结一下新版selenium对网页元素进行定位的操作方法。
一、常用的八种定位方法(新旧对比)
先介绍一下selenium定位元素的一些常见方法
| 定位方法 | 新版 | 旧版 |
|---|---|---|
| by_id | find_element(By.ID,value=’’) | find_element_by_id() |
| by_name | find_element(By.NAME,value=" ") | find_element_by_name() |
| by_class_name | find_element(By.CLASS_NAME,value=" ") | find_element_by_class_name() |
| by_tag_name | find_element(By.TAG_NAME,value=" ") | find_element_by_tag_name() |
| by_link_text | find_element(By.LINK_TEXT,value=" ") | find_element_by_link_text() |
| by_partial_link_text | find_element(By.PARTIAL_LINK_TEXT,value=" ") | find_element_by_partial_link_text() |
| by_css_selector | find_element(By.CSS_SELECTOR,value=" ") | find_element_by_xpath() |
| by_xpath | find_element(By.XPATH,value=" ") | find_element_by_xpath() |
Selenium八大元素定位方法的优缺点对比如下:
● 1. ID定位
优点:ID是唯一的,定位速度快。
缺点:有些元素没有ID,不适用。
● 2. Name定位
优点:Name属性通常是唯一的,定位速度快。
缺点:有些元素没有Name属性,不适用。
● 3. Class Name定位
优点:Class Name属性通常是唯一的,定位速度快。
缺点:有些元素没有Class Name属性,不适用。
● 4. Tag Name定位
优点:Tag Name属性通常是唯一的,定位速度快。
缺点:有些元素没有Tag Name属性,不适用。
● 5. Link Text定位
优点:Link Text属性通常是唯一的,定位速度快。
缺点:只适用于链接。
● 6. Partial Link Text定位
优点:Partial Link Text属性通常是唯一的,定位速度快。
缺点:只适用于链接。
● 7. CSS Selector定位
优点:CSS Selector可以通过多个属性组合定位元素,定位灵活。
缺点:CSS Selector语法较为复杂,学习成本较高。
● 8. XPath定位
优点:XPath可以通过多个属性组合定位元素,定位灵活。
缺点:XPath语法较为复杂,定位速度较慢。
二、查看网页元素
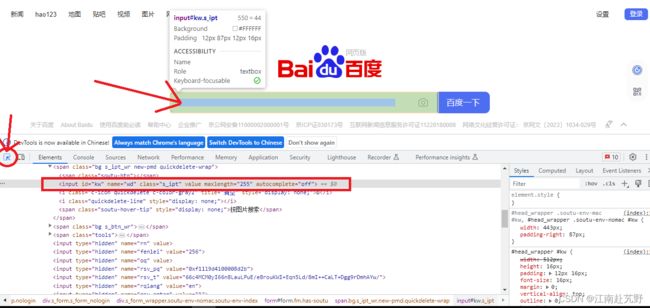
以谷歌浏览器打开百度为例,点击右上角>更多工具>开发者工具,或者点击鼠标右键选择>检查,就可以看到整个页面的html代码了。

点击框中左上角的箭头图标,移动鼠标到百度搜索框,就可以自动定位到百度搜索框的HTML代码了,查看到搜索框的属性,我们可以看到搜索框有id,name,class等属性。
三、八大元素定位示例
代码前置操作,导库和包,创建浏览器对象并打开想要用Selenuim操作的网页。
# 导入selenium库
from selenium import webdriver
# 导入time库
import time
# 导入By类,用于指定元素定位方式
from selenium.webdriver.common.by import By
# 创建Chrome浏览器对象
driver = webdriver.Chrome()
# 设置要访问的网址
url = 'http:www.baidu.com'
# 打开网址
driver.get(url = url)
1、id定位
从上面定位到的搜索框属性中,有个id="kw"的属性,我们可以通过这个id定位到这个搜索框。

代码:
driver.find_element(By.ID, 'kw').send_keys('Selenuim')
该行代码实现在百度搜索框中输入“Selenuim”。
2、name定位
从上面定位到的搜索框属性中,有个name="wd"的属性,我们可以通过这个name定位到这个搜索框。
代码:
driver.find_element(By.NAME,'wd').send_keys('selenium')
该行代码实现name定位搜索框,并输入selenium。
3、class定位
从上面定位到的搜索框属性中,有个class="s_ipt"的属性,我们可以通过这个class定位到这个搜索框。
代码:
driver.find_element(By.CLASS_NAME,'s_ipt').send_keys('selenium')
该行代码实现class定位搜索框,并输入selenium。
4、tag定位
如果懂HTML知识,我们就知道HTML是通过tag来定义功能的,比如input是输入,table是表格,等等…每个元素其实就是一个tag,一个tag往往用来定义一类功能,我们查看百度首页的html代码,可以看到有很多div,input,a等tag,所以很难通过tag去区分不同的元素。基本上在我们工作中用不到这种定义方法,仅了解就行。下面代码仅做参考,运行时必定报错。
代码:
driver.find_element(By.TAG_NAME,'input').send_keys("selenium")
该行代码实现tag定位搜索框,并输入selenium, 此处必报错。
5、link定位
此种方法是专门用来定位文本链接的,比如百度首页右上角有“新闻”,“hao123”,“地图”等链接。

代码:
driver.find_element(By.LINK_TEXT,'新闻').click()
该行代码实现link定位"新闻"这个链接并点击。
6、partial_link定位
有时候一个超链接的文本很长很长,我们如果全部输入,既麻烦,又显得代码很不美观,这时候我们就可以只截取一部分字符串,用这种方法模糊匹配了。
代码:
driver.find_element(By.PARTIAL_LINK_TEXT,'闻').click()
该行代码实现partial_link定位"新闻"这个链接并点击。
7、xpath定位
前面介绍的几种定位方法都是在理想状态下,有一定使用范围的,那就是:在当前页面中,每个元素都有一个唯一的id或name或class或超链接文本的属性,那么我们就可以通过这个唯一的属性值来定位他们。
但是在实际工作中并非有这么美好,有时候我们要定位的元素并没有id,name,class属性,或者多个元素的这些属性值都相同,又或者刷新页面,这些属性值都会变化。那么这个时候我们就只能通过xpath或者CSS来定位了。
xpath获取方法:定位到百度搜索框的HTML代码,单击鼠标右键>Copy>Copy XPath

代码:
driver.find_element(By.XPATH,"//*[@id='kw']").send_keys('selenium')
该行代码实现xpath定位搜索框,并输入selenium
8、CSS定位
这种方法相对xpath要简洁些,定位速度也要快些,但是学习起来会比较难理解,这里只做下简单的介绍。
代码:
driver.find_element(By.CSS_SELECTOR,'#kw').send_keys('selenium')
该行代码实现CSS定位搜索框,并输入selenium