MySQL日志
MySQL日志
文章目录
- MySQL日志
-
- 1. 二进制日志(binary log)
-
- 1.1 二进制日志的概念
- 1.2 二进制日志的作用
- 1.3 二进制日志相关参数及作用
-
- 1.3.1 max_binlog_size
- 1.3.2 binlog_cache_size
- 1.3.3 sync_binlog
- 1.3.4 binlog_format
- 1.3.5 binlog_do_db
- 1.3.6 binlog_ignore_db
- 1.3.7 log-slave-update
- 1.3.8 相关命令
- 1.3.9 binlog 截取
- 1.3.10 GTID
-
- 介绍
- 应用
- 1.3.11 日志清理
-
- 相关参数
- 1.4 二进制日志和做日志的区别
-
- binary log
- redo log
- 2. 重做日志(redo log)
-
- 2.1 redo log 基础 - 阐述
-
- 2.1.1 重做日志的概念
- 2.1.2 重做日志的作用
- 2.1.3 重做日志的相关参数和作用
-
- innodb_log_file_size
- innodb_log_buffer_size
- innodb_log_group_home_dir
- innodb_log_files_in_group
- innodb_flush_log_at_trx_commit
- innodb_redo_log_archive_dirs
- innodb_redo_log_encrypt
- 2.1.4 redo日志和redo日志文件的格式和类型
-
- redo日志的记录格式(内存中)
- redo日志文件的格式(磁盘中)
- redo日志的类型
- 2.2 redo log 进阶
-
- 2.2.1 Mini-Transaction
-
- 以组的形式写入REDO日志
-
- MTR概念(Mini-Transaction)
- 2.2.2 REDO写入Log Buffer
-
- MTR的结构
- MTR和REDO的关系
- 单个/多个mtr是怎么并发写入Redo Log Buffer的?
- 总结
- 2.2.2 Log Buffer 写入Log File
-
- REDO的刷盘时机
- Log Sequence Number(LSN)
- flushed_to_disk_lsn
- flush链表中的LSN
- 触发checkpoint的条件
- 总结
- 2.2.3 checkpoint
- 2.2.4 崩溃恢复
-
- 2.2.4.1 什么时候执行REDO恢复
- 2.2.4.2 意外宕机下REDO的恢复流程
- 2.2.4.3 redo的“前滚操作”
- 2.3 有关redo log的问题与思考
-
- 2.3.1 在意外宕机恢复应用redo时,还会产生新的redo log 吗?
- 2.3.2两阶段提交的过程是怎样的?
-
- 为什么需要两阶段提交?
- 两阶段提交有什么问题?
- 为什么两阶段提交的磁盘 I/O 次数会很高?
- 为什么锁竞争激烈?
- 事务提交的方式——组提交
-
- 多线程复制分发原理
- 多线程复制的相关参数
- 3. 错误日志 error log
-
- 3.1 关于error log的相关概述
- 3.2 err log相关参数
-
- log_error
- 4. 通用日志 generaly log
-
- 4.1 概述
- 5. 慢日志 slow log
-
- 5.1 概述
- 5.2 相关参数
-
- 慢日志分析工具
- 慢日志分析具体如下
- 6. 回滚日志 undo log
-
- 6.1 undo log概述
-
- 6.1.1 事务id
- 6.2 undo log对事务语句的影响
-
- 6.2.1 undo log对insert语句的影响
- 6.2.2 undo log对delete语句的影响
- 6.2.3 undo log对update语句的影响
-
- 6.2.3.1 更新非主键
- 6.2.3.2 更新主键
- 6.2.4 undo log 写入过程
-
- 6.2.4.1 通用链表
- 6.2.4.2 undo log 的具体写入过程
-
- 6.2.4.2.1 FILE_PAGE_UNDO_LOG
- 6.3 MVCC
-
- 6.3.0 MVCC概述
-
- 6.3.0.1 MVCC定义
- 6.3.0.2 为什么使用MVCC
- 6.3.0.3 MVCC解决的问题
- 6.3.1 事务的隔离级
- 6.3.2 隐式字段
- 6.3.3 MVCC在不同隔离级别下对事务的影响
-
- 6.3.3.1 MVCC在RC隔离级下对事务的影响
- 6.3.3.2 MVCC在RR隔离级别下对事务的影响
- 6.3.3.3 RC隔离级别行更新的过程
- 6.3.3.4 RR隔离级别行更新过程
- 6.3.4 Read View 读视图
-
- 6.3.4.1 **ReadView** 结构
- 6.3.4.2 RC隔离级下Read View生成
- 6.3.4.3 RR隔离级下Read View生成
- 6.4 undo log相关参数
- 7. relay log
1. 二进制日志(binary log)
1.1 二进制日志的概念
binary log是逻辑日志。主要记录alter,drop,create,insert,update,delete语句
记录了对mysql数据库的执行更改操作,但是不会记录select,show语句。
但像select,show这种查询语句可以在general_log中查看。
1.2 二进制日志的作用
- 恢复
用户可以通过二进制日志进行point-in-time恢复 - 复制
常见于做主从复制 - 审计
用户可以从二进制日志中看到其他用户在此节点上执行的sql语句操作,判断是不否有对象向数据库注入攻击。
1.3 二进制日志相关参数及作用
1.3.1 max_binlog_size
这个参数的含义是binlog刷写到磁盘的最大文件大小。在mysql 5.0之后是1G。超出则会创建文件,后缀名+1的文件。
1.3.2 binlog_cache_size
此参数会记录所有未提交事务所产生的binlog大小。可以理解它就是一个binlog的缓冲区。当有commit操作时,就会将缓冲区的binlog(binlog cache)刷到binlog 文件。默认是32k. binlog_cache_size是基于会话的。如果当一个用户写入数据所产生的binlog大于binlog_cache_size时,mysql就会将缓冲中的binlog日志写入到临时文件中,所以此值不能设置的太小。
我们可以通过binlog_cache_disk_use和binlog_cache_use判断该binlog_cache_size设置的值是否合适。
binlog_cache_disk_use : 用于记录binlog采用临时文件存储日志的次数。
binlog_cache_use: 用于记录了使用缓冲写(binlog_cache_size)二进制日志的次数。
1.3.3 sync_binlog
双一参数其中的一个.用于记录binlog刷盘的时机。
- 0: 关闭。
- 1: 开启。表示同步写磁盘的方式来写二进制日志
- 大于1: 表示每写缓冲多少次就同步到磁盘。
当sync_binlog为1时,也会产生数据不一致的情况。
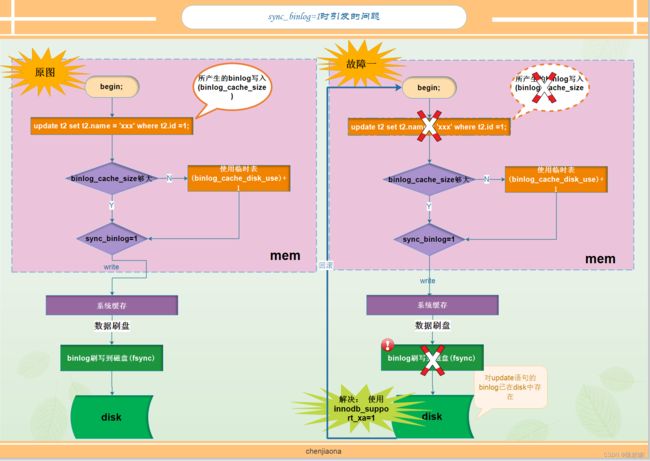
如上图所示:
当使用innodb存储引擎时,commit事物之前,由于sync_binlog=1,且设置的binlog_cache_size也足以容纳update语句所产生的binlog时,这时binlog就会马上刷写到磁盘,而假如在这时server crash,数据库在下次重启时进行恢复,会将update语句所在事务回滚,但是二进制日志已经写入,这就会造成内存和磁盘的数据不一致的情况。可以通过innodb_support_xa=1来解决。
1.3.4 binlog_format
记录binlog的格式。可选择值为STATEMENT,ROW,MIXED.在mysql5.1版本之前,没有这个参数,所有的binlog都是记录的STATEMENT。
-
STATEMENT
二进制日志文件中记录的是SQL语句。 -
ROW
在mysql5.1版本之后,默认是ROW模式,二进制日志文件中记录的是数据的变化,这是逻辑的。一般设置为ROW后,会比设置为statement文件更大。那是因为statement模式记录的只是一条sql语句,例如update t1 set t1.name = 'xx' where t1.id =1;,而row模式,则是将t1表将所有字段都显示出来(需要使用mysqlbinlog工具解析一下)。 -
MIXED
是上面两种模式的混合。MySQL采用默认的STATEMENT模式记录二进制日志,但是在某些情况下,MySQL会采用ROW模式。
a. 表的引擎为NDB
b. 使用UUID(),NOW(),CURRENT_USER()等不确定的函数
c. 使用insert delay语句
d. 使用了临时表
e. 使用了用户定义函数(UDF)
1.3.5 binlog_do_db
mysql复制相关参数,表示主库中有哪些库可以同步到从库
1.3.6 binlog_ignore_db
mysql复制相关参数,表示主库中有哪些库不可以同步到从库
1.3.7 log-slave-update
如果当前数据库是slave角色,则表示 要将从master取得并执行的二进制日志写入自己的二进制日志文件中去。
1.3.8 相关命令
-
查看当前数据库已经运行的位置点
show master status -
查看指定binlog 文件的events
show binlog events in 'mysql-bin.00001' -
查看指定binlog 文件的events
pager less: 在mysql内部使用,表示开启less的方式查看以后的内容 -
解析binlo
mysqlbinlog --base64-output=decode-rows -vv mysql-bin.00001
1.3.9 binlog 截取
场景:假如在数据库中这样一段数据
create database bin; --> positionc 4
use bin;
create table t(id int);
insert into t values (1);
insert into t values (2);
insert into t values (3); -->position 66
# 执行误操作
drop database bin;
需要恢复到删库之前的状态
- 根据position来截取binlog 命令
mysqlbinlog --start-position=4 --stop-position=66 xxx >/tmp/bak.sql
- 根据时间来截取binlog 命令
mysqlbinlog --start-datetime=xxx --stop-datetime=xxx filename > /tmp/bak.sql
- 恢复截取的文件
进入数据库后执行:set sql_log_bin=0;-- 在当前窗口中以后的操作都不记录二进制日志 source /tmp/bak.sql; set sql_log_bin=1; - 使用source恢复数据时会有一些问题
- 日志跨度时间长,量比较大
如果要恢复的日志起始点和结束点数据多,且相隔的时间比较长,DBA很难定位 。
解决方法:我们可以利用备份+日志的方式进行恢复,如果没有备份的话,就比较麻烦了- 跨多个文件
恢复的日志起始位置和结束位置横跨多个文件
解决方法:
a. 假如使用Position号恢复数据的话,需要分段恢复,比较麻烦
b. 假如按时间截取的话,恢复的日志会不准确 。因为/tmp/bak.sql里面存储的不只是这一张表的数据 ,而是有很多张表,在这一段日志中肯定会有其他表的数据,并且这个文件中包含其他表的事务也不一定是完整的。而且如果其他表没有主键的话,再恢复时也会报错。
c. 按gtid截取
d. 使用my2sql工具分析/tmp/bak.sql文件,这个工具可以将表级别的数据转换成sql
1.3.10 GTID
介绍
- 5.6版本新加的特性
- 在5.7版本中的GTID中,即使不开也会自动生成
- 相关参数
gtid-mode=on
enforce-gtid-consistency=true
log-slave-updates=1
应用
开启gtid后,截取二进制日志方法如下:
--include-gtids='xxx' # 包含哪个gtid的信息
--exclude-gtids='xxx' # 除去该gtid,将剩余的信息输出
--skip-gtids # gtid幂等性(将备份的gtid删除,开启此选项后,输出的备份文件就不会包含gtid_next的信息了。只要开启gtid,无论用哪种方式将数据导出,都要加这个选项)
position方式备份数据也要加这个参数
1.3.11 日志清理
相关参数
expire_logs_days
在mysql8.0新加了一个参数expire_logs_days(binlog 过期时间,以天为单位)binlog_expire_logs_seconds
binlog 过期时间,以秒为单位,和expire_logs_days选一个。purge binary logs to 'log name'
删除到哪个文件之前reset master
1.4 二进制日志和做日志的区别
binary log
- binary log 是逻辑日志,记录的是SQL语句
- binary log在写日志是追加式
- binary log用于数据库的备份及恢复
redo log
- redo log是物理日志,记录的是数据页的变化
- redo log在写日志是循环式
- redo log提供WAL的功能,可以做数据恢复
- redo log用于实例恢复
2. 重做日志(redo log)
2.1 redo log 基础 - 阐述
2.1.1 重做日志的概念
我们知道,innodb存储引擎是以页来存储数据的,当对页进行增删改时,首先先将相关页面加载到buffer pool中,使其成为脏页,再根据某种策略将脏页刷新到磁盘。假如在这时脏页还没有刷写到磁盘时,数据库宕机,那么修改的数据岂不就丢失了吗!!!故此,innodb存储引擎引用redo,当在buffer pool中修改数据页后,先将修改的页面日志写入到redo中(即redo里存储的是数据页的变化),即使数据库宕机,也可以利用redo log将数据库恢复。
2.1.2 重做日志的作用
redo日志会把事务在执行过程中对数据库所做的所有修改都记录下来,在这后系统因崩溃而重启后,可以把事务所做的任何修改都恢复过来。
2.1.3 重做日志的相关参数和作用
innodb_log_file_size
是指每个redo log file的大小,默认是48M。
innodb_log_buffer_size
是指在内存中redo buffer 的大小,默认是16M,innodb将redo buffer分为多个512字节大小的块,也就是有32768个这样大小的块。
innodb_log_group_home_dir
是指redo log file的家目录,也就是当前实例的数据目录
innodb_log_files_in_group
是指redo log file的个数,默认为2,最大为100。从ib_logfile0开始,以此类推。
innodb_flush_log_at_trx_commit
redo log刷写磁盘的时机,可以为0,1,2
当此值为0时:
表示当事务提交时,不做日志写入操作,而是每秒钟将日志缓冲的数据写入到os cache中并且每秒fsync到磁盘一次。意思就是说在1秒钟之内不管生成多少个事务都会将数据先写入到os cache中然后再写入到磁盘,就算是丢失数据也只是会丢失1秒钟的数据 。
当此值为1时:
每次事务提交执行commit之后就将日志写入,先从内存中写入到os cache中(这个过程叫做commit os缓冲),再将数据从os cache立即flush到磁盘。当值为1时,不会丢失数据,不过访问磁盘的次数有些增多。
当此值为2时:
每次事务提交引起写入os cache中,并每秒写入到磁盘(只要是在1秒钟生成的数据都会写入到磁盘中)
innodb_redo_log_archive_dirs
innodb_redo_log_encrypt
2.1.4 redo日志和redo日志文件的格式和类型
redo日志的记录格式(内存中)
| 字段 | 说明 |
|---|---|
| type | 这条redo的类型 |
| space ID | 表空间ID |
| page number | 页号 |
| data | 真实数据 |
- 当把一条记录插入到页面时,redo是怎么记录的呢?
- 在每个修改的地方都记录一条redo日志
- 在页面起始和页面最后修改的地方记录一条redo日志
如图所示:

InnoDB存储引擎采用的是第一种方式,因为第二种有点浪费空间了。
redo日志文件的格式(磁盘中)
我们知道,log buffer是由多个512字节大小的块组成,所以在磁盘中的log file也是由多个512字节大小的块组成,redo log写入log buffer是顺序写入的,所以从log buffer写入log file也应该是顺序写入的。

如上图所示:在log file header字段中比较重要的有:
LOG HEADER START LEN: 标记本redo 日志文件偏移量为2048字节处所对应的lsn值;
LOG BLOCK CHECKSUM: 该block块的checksum校验值 .
| 字段 | 说明 |
|---|---|
LOG CHECKPOINT NO |
服务器执行checkpoint的编号,每执行一次,该值加1 |
LOG CHECKPOINT LSN |
log buffer向log file最后刷写的lsn值,也是数据库崩溃恢复的起点 |
LOG CHECKPOINT OFFSET |
上个属性中的lsn值在redo日志文件组中的偏移量 |
LOG CHECKPOINT LOG BUF SIZE |
服务器在执行checkpoint时对应的log buffer的大小 |
LOG BLOCK CHECKSUM |
block的校验值 |
checkpoint1和checkpoint2包含的字段相同。
- redo日志文件组
和redo日志文件组相关参数有:innodb_log_file_size,innodb_log_group_dir,innodb_log_files_in_groupinnodb_log_file_size
是指每个redo log file的大小,默认是48M。innodb_log_group_dir
是指redo log file的家目录,也就是当前实例的数据目录innodb_log_files_in_group
是指redo log file的个数,默认为2,最大为100。从ib_logfile0开始,以此类推。

redo日志的类型
INNODB存储引擎一共有53种redo日志的类型。在这里只拿几种常见的举例。
-
MLOG_8BYTE
我们知道,在innodb系统表中维护一个MAX_ROW_ID的全局变量,每当向某个包含row_id的隐藏列中插入一条数据时,就会更新MAX_ROW_ID的值。当这个全局变量是256的倍数时,就会更新到表空间中页号为7的页面里,当再次引用时,就会加此次的row_id加上256得出最大的row_id.MAX_ROW_ID占用8个字节,所以在写入页面时就会记录一条redo日志,而这条redo日志的redo类型就是MLOG_8BYTE。 -
MLOG_MULTI_REC_END
把该组事务中最后一条redo日志后面加这一个特殊类型,当系统崩溃进行恢复时会检测这组事务,如果在这组事务中最后一个redo日志的类型不是MLOG_MULTI_REC_END的话,则会认为这组事务不是一个完整的事务,会回滚掉。
2.2 redo log 进阶
2.2.1 Mini-Transaction
以组的形式写入REDO日志
我们知道,当我们对表中的一条数据进行更改,例如一条insert语句在插入到数据页时,如果这个数据页的大小刚好够这条记录的话,那么InnoDB就不必再开启一个新页面了。因为开启一个新的页面,意味着需要改多处,叶子节点,内节点(会产生页分裂),可能还需要改槽,这种“牵一发而动全身”的做法在数据库的领域称为“悲观插入”,前者称为“乐观插入”。
在页面上写数据也就是在一棵B+树上写数据。当我们创建了一张表,表中多少个索引,就代表多少个B+树,当对B+树中的叶子节点进行更新时,同理也要更新内节点的信息,否则我们就会认为这棵B+树的状态是不正确的。
我们都知道,redo是为了数据库的崩溃恢复而提出的,如果在悲观插入的过程中,只记录一部分的redo日志,那么在重启时B+树会是一个不正确的状态。那么我们通过什么来保证redo日志的原子性呢?
有一种redo日志类型,叫MLOG_MULTI_REC_END,在前面我们已经说过这种类型的含义了,在此就不在赘述了。