【无标题】数据仓库-学习
1、数据仓库基础知识
1.1什么是数仓
数仓的概念:
- 数据仓库简称数仓,在《建立数据仓库》中是这样定义数据仓库的:数据仓库是面向主题的,数据集成的,相对稳定的(非易失的),反映历史变化(时变)的数据集合,用于支持管理决策。
- 数据仓库是决策支持系统的结构化数据环境。决策支持系统基于数据仓库进行联机分析处理。
- 应用场景:满足企业中所有数据的统一化存储,通过规范化的数据处理来实现企业的数据分析应用。
1.2为什么有数仓
数仓的由来: 为了更好的分析数据
- 1、公司建立、开展业务
- 2、业务数据存储(事务支持)---->数据库DB
- 3、经营发展中想赚更多的钱
- 4、分析业务数据
- 5、DB直接分析影响读性能,干扰业务开展,得不偿失
- 6、其他系统、类型的数据也需要一起分析 彼此异构
- 7、搭建统一、集成化数据分析平台
- 8、建立模型和规范 愉快的进行各种分析
1.3数仓的特点是什么
面向主题性
主题是在较高层次上将企业信息系统中某一分析对象(重点是分析的对象)的数据进行整合、归类并分析的一种范围,属于一个抽象概念(太tm抽象了)
数据仓库:面向主题划分数据,以分析需求为导向组织数据:
商品主题
供应商注意
顾客主题
订单主题
集成性
数据仓库不生产数据也不使用数据,只实现数据的存储和加工。
因为同一个主题的数据可能来自不同的数据源,它们之间会存在着差异(异构数据):字段同名不同意、单位不统一、编码不统一;
因此在集成的过程中需要进行ETL(Extract抽取 Transform转换 load加载)
非易失性
操作型数据库如mysql主要服务与日常的业务操作,使得数据库需要不断的实时更新,以便迅速获得当前最新的数据。
数仓数据仓库中只要保存过去的业务数据,上面的数据几乎没有修改操作,都是查询分析的操作。数仓是分析数据规律的平台,不是创造数据分析的平台。
数据非易失性主要是针对应用而言。
注意:改指的是数据之间的规律不能修改。
时变性=
数据仓库中包含各种粒度的历史数据。数据仓库的目的是通过分析企业过去一段时间业务的经营状况,挖掘其中隐藏的模式。虽然数据仓库的用户不能修改数据,但并不是说数据仓库的数据是永远不变的。分析的结果只能反映过去的情况,当业务变化后,挖掘出的模式会失去时效性。因此数据仓库的数据需要更新,以适应决策的需要。从这个角度讲,数据仓库建设是一个项目,更是一个过程 。数据仓库的数据随时间的变化表现在以下几个方面。 (1)数据仓库的数据时限一般要远远长于操作型数据的数据时限。 (2)操作型系统存储的是当前数据,而数据仓库中的数据是历史数据。 (3)数据仓库中的数据是按照时间顺序追加的,它们都带有时间属性。
1.4 OLTP和OLAP系统区别(数据库和数仓的区别)
OLTP:
- 概念:即联机事物处理。也称为面向交易的处理过程
- 核心:事物支持
- 特点:
- 数据安全
- 数据完整
- 操作响应效率、时间
- 并发支持
- CRUD操作
- 用户:业务操作人员
- 典型代表:
- ROBMS关系型数据库管理系统,如MySQL,Oracle
OLAP:
- 概念:联机分析处理系统,有时也称为决策支持系统(DSS)
- 核心:分析支持
- 特点
- 数据量大
- 事务性要求不高
- 支持满足不同程度分析需求
- 查询操作
- 用户:数据分析人员
- 典型代表:
- 数据仓库、数据集市、面向分析的数据库系统

- 数据仓库、数据集市、面向分析的数据库系统
2、数仓系统的架构与核心流程
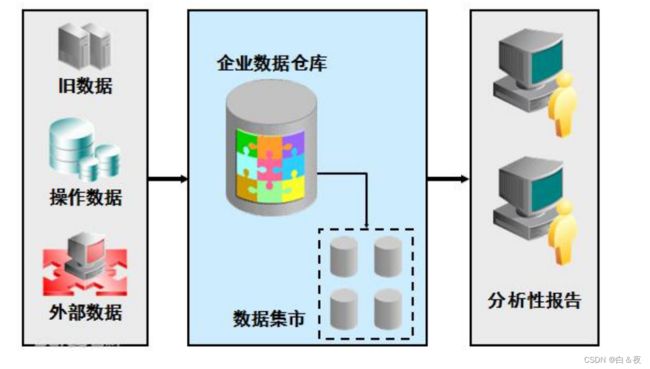
数据仓库提供企业决策分析的数据环境,数据从哪里获取?数据如何存储到数据仓库?决策分
析系统如何从数据仓库获取数据进行分析?我们可以把数据从获取、存储到数据仓库、数据分析的
所有部分称为一个数据仓库系统。
下图是数据仓库系统的结构图:

执行流程:
- 1、确定分析所依赖的源数据。
- 2、通过ETL将源数据采集到数据仓库。
- 3、数据按照数据仓库提供的主题结构进行存储。
- 4、根据各部门的业务分析要求创建数据集市(数据仓库的子集)。
- 5、决策分析、报表等应用系统从数据仓库查询数据、分析数据。
- 6、用户通过应用系统查询分析结果、报表
源数据:
源数据是指用于分析的原始数据,这一步主要是根据分析需求确定源数据,这个数据分布在内
部系统和外部分系统中,内部数据主要是企业ERP系统、外部数据是指企业外部分系统所产生的数
据,通常是指行业数据。源数据最大的特点是格式不统一,如果要对源数据进行分析需要经过ETL
对数据进行集中获取、过虑、转换等处理
数据粒度:
细粒度:分组的单位更小
粗粒度:分组的单位更大
数据仓库和数据集市:
数据仓库是用于企业整体分析的数据集合。
数据集市是用于部门分析的数据集合。从范围上将,数据集市是属于数据仓库的子集。数据集市基于数据仓库。可以认为数据集市就是对数仓中的数据进行分类归纳
数据仓库和数据集市具有什么区别?
1、范围的区别
数据仓库是针对企业整体分析数据的集合。
数据集市是针对部门级别分析的数据集合。
2、数据粒度不同
数据仓库通常包括粒度较细的数据明细。
数据集市则会在数据仓库的基础上进行数据聚合,这些聚合后的数据就会直接用于部门业务分
析
2.1 核心1:ETL
ETL(Extra, Transfer, Load)包括数据抽取、数据转换、数据装载三个过程。
1、抽取
数据抽取是从各各业务系统、外部系统等源数据处采集源数据。
2、转换
采集过来的源数据如果要存储到数据仓库需要按照一定的数据格式对源数据进行转换,常
见的转换方式有数据类型转换、格式转换、缺失值补充、数据综合等。
3、装载
转换后的数据就可以存储到数据仓库中,这个过程要装载。数据装载通常是按一定的频率
进行的,比如每天装载当天的订单数据、每星期装载客户信息等
2.2 核心2:数仓分层
将各种数据的处理流程进行规范化,例如下图:

分层的实现:
当使用hive作为数据仓库根据的时候,分层是在hive中逻辑划分实现的。
常见的做法:不同的分层常见不同的database
3、 维度分析
指标和维度
**指标:**衡量事物发展的标准,也叫度量。多为行为事实数据;指标可以求和、平均值等计算。
- 指标分为绝对指标和相对指标:
- 绝对指标:反映具体的大小和多少,如价格,销量等 ----普通数字
- 相对数值:反映一定程度,如购买率,及格率。 ----百分比
指标的功能:通过指标来衡量事实的结果,反映事实的好坏。
维度: 维度是事物的特征,如颜色、区域、时间等,可以根据不同的维度来对指标进行分析对比。例如可以根据区域维度来分析不同地区产品的销量。通俗的解释:维度就是看待和分析事物的角度
维度的功能:细化指标 ,不同角度审视指标,更加精确的发现问题。
上卷Roll-up、下钻Drill-down
上卷:获取更高级别的汇总信息的过程称为上卷。 由细粒度到粗粒度是上卷。
下钻:获取低级别的明细信息的过程叫下钻。由粗粒度到细粒度是下钻
在sql层面上,维度和指标的关系:在sql层面上理解,指标就是sql语句中聚合统计分析的一个结果,数值;维度就是分组的字段。
4、数仓模型
4.1 概述
数据仓库建模的方法常用的有两种:三范式建模法,维度建模法。三范式建模法一般用于传统的企业级数据仓库,一般使用关系型数据库实现。应用于自顶向下的数据仓库框架。维度建模法是基于维度分析来创建模型,应用于自下想上的数据仓库模型。
维度建模,简称DM。维度数据模型是一种趋向于支持最终用户对数据仓库进行查询的设计技术,是围绕性能和易理解性构建的。是面
向最终用户的。也就是说,维度模型是按照用户看待或分析数据的角度来组织数据。
4.2 事实表
4.2.1 概念:
- 事实表一般是类似ER图中多个实体的关系表
- 事实表是将多个实体进行关联,描述他们之间的发生的事实行为
- 一般情况下事实表是由很多的外键组成。
4.2.2事实表的分类:
- 事务事实表:在应用中,大部分的事实表都属于事务事实表,其描述的每一个操作行为,一个行为就是事实表中的一行记录。且一旦事物被提交,将不再发生更改,其更新方式为增量更新。
- 周期快照事实表:用于记录一段时间的统计结果。具有规律性的可预见的时间间隔来记录事实。事实表的数据一旦插入就不能更改,其更新方法为增量更新。
- 累计快照事实表:该事实表刚开始数据不稳定,需要随着时间的推移,事实表中的数据才能不断的补全。其记录的的不确定的周期的数据。
- 无事实事实表:该事实表描述的是,当前还没有发送的事实(这个概念太抽象了吧!)没有事实发生,表面看没有事实的事实表是没有意义的,但是无事实的事实表却有其他的用途:
讲述不同维度之间的对应关系,帮助业务模型落地到数据模型过程中,更好地梳理维度之间的对应
关系,并且能更快获得关系数据。
最常见的例子就是维度与维度之间的关系表,或者说是多对多表的中间表。
表面上没有一个可分析的度量值,所以被称为“无事实”的事实表。但实际上这样的事实表中都
会隐藏着一个count的信息,因此它也可以作为一个事实表来进行统计

4.3 维度表
概念:维度是指观察数据的角度。
分类:
**高基数维度表:**一般是用户资料表、商品资料表类似的资料表。数据量可能是千万级或
者上亿级别
低基数维度表:一般是配置表,比如枚举值对应的中文含义,或者日期维表、地理维表
等。数据量可能是个位数或者几千条几万条。
4.4 建模模型
4.4.1常见模型
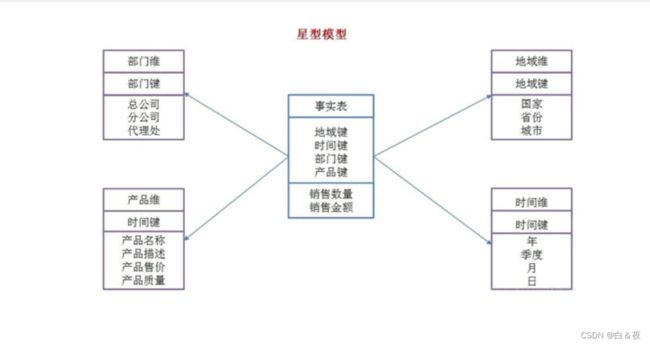
星型模型:一个事物表为中心,多个维度表环绕周围。
模型特点:
- 只有一个事实表
- 所有维度表环绕在事实表周围
- 星型模型一般只用于数仓分析的初级阶段,到后期该模型已经不能满足实际需求。
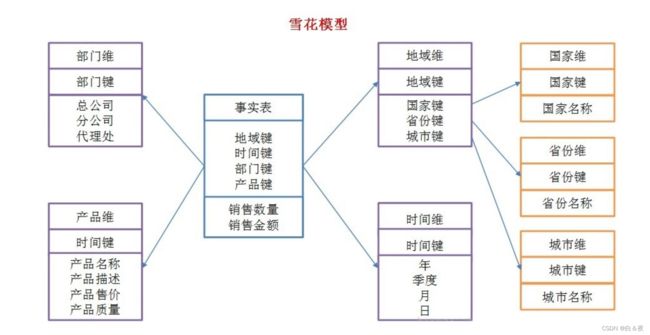
 雪花模型:当有一个或多个维表没有直接连接到事实表上,而是通过其他维表连接到事实表上时,就像多个雪花连接在一起,故称雪花模型。雪花模型是对星型模型的扩展,是对星型模型的维度表做进一步规范化处理后形成的,这些被分解的表都连接到主维度表而不是事实表。
雪花模型:当有一个或多个维表没有直接连接到事实表上,而是通过其他维表连接到事实表上时,就像多个雪花连接在一起,故称雪花模型。雪花模型是对星型模型的扩展,是对星型模型的维度表做进一步规范化处理后形成的,这些被分解的表都连接到主维度表而不是事实表。
特点:
- 只有一个事实表
- 事实表周围环绕维度表,而维度表又关联其他的维度表
- 该模型在应用时,由于要进行大片的join操作,所以模型基本不用。
如何将维度表进行规范化处理呢?
即把低基数(重复比较多、辨识度比较低)的属性从维度表中移除并形成单独的表。基数指的
是一个字段中不同值的个数,比如主键列具有唯一值,所以具有最高的基数,而性别枚举值(日期、地区等)这样的列的基数就很低。
规范化的影响
规范化的过程是将维度表中重复度比较高的字段组成一个新表,所以规范化不可避免增加了表
的数量,减少了数据的存储空间,提高了数据更新的效率。但是查询时就需要连接更多的表。
折中的方式
底层使用雪花模型,上层用表连接建立视图来模拟星型模型。这样既通过规范化节省了存储空
间,又降低了用户查询数据的复杂性。但是当外部查询条件不需要连接整个维度表时,该方法将会带来性能损失。
总结,雪花模型中,一个维度被规范化成多个关联的表,星型模型中,每个维度由一个单一的维度表所表示。
5.数据仓库分层
5.1 为什么分层
所谓的数仓分层实际是在数据处理的不同阶段,创建不同的数据库,把相同阶段的数据存储在同一个数据库中。
如果数仓没有分层,将所有阶段的数据表混合在一起,则无法实现很清晰的处理逻辑。
那为啥要分层?因为作为一名数据的规划者,我们希望自己的数据能够有秩序的流转,数据的整个生命周期能够明确清晰的被设计者和使用者感知到。
这是我们希望的:
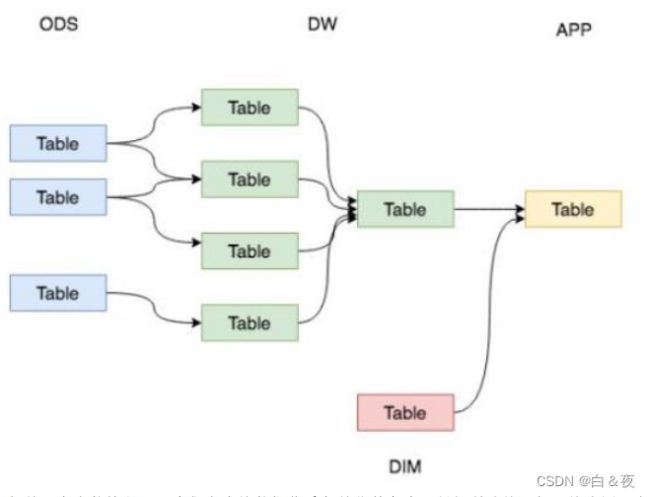
但我们事实上的数据体系(下面这个是不是看起来混乱、复杂。)
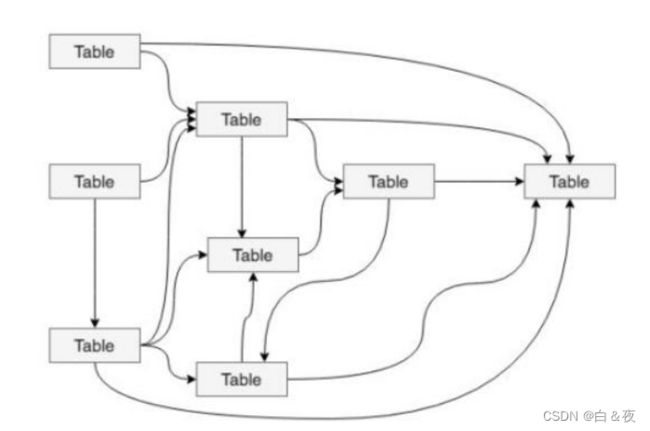
数据分层的好处:
- 清晰数据结构:每一个数据分层都有它的作用域,在使用表的时候能更方便地定位和理解。
- 减少重复开发:规范数据分层,开发一些通用的中间层数据,能够减少极大的重复计算
- 便于维护:当数据出现问题之后,可以不用修复所有的数据,只需要从有问题的步骤开始修
复。 - 统一数据口径:通过数据分层,提供统一的数据出口,统一对外输出的数据口径
- 复杂问题简单化::将一个复杂的任务分解成多个步骤来完成,每一层解决特定的问题
- 数据血缘追踪:简单来说,我们最终给业务呈现的是一个能直接使用业务表,但是它的来源有很多,如果有一张来源表出问题了,我们希望能够快速准确地定位到问题,并清楚它的危害范围。
5.2 分层方法
5.2.1 源数据层(ODS)
ODS是hive数仓中的一个逻辑分层。此层数据无任何更改,直接沿用外围系统数据结构和数据,不对外开放;为临时存储层,是接口数据的临时存储区域,为后一步的数据处理做准备,
5.2.2 数据仓库层(DW)
DW层的数据由ODS层数据加工而成,主要完成数据加工和整合。DW层的数据应该是一致的、准确的、干净的数据。
实际应用中,会对DW层进行更加细化的分层,如下:
- 1.明细层DWD(Data Warehouse Detail):存储明细数据,此数据是最细粒度的事实数据。
该层一般保持和ODS层一样的数据粒度,并且提供一定的数据质量保证。同时,为了提高数据明细
层的易用性,该层会采用一些维度退化手法,将维度退化至事实表中,减少事实表和维表的关联。 - 2.中间层DWM(Data WareHouse Middle):存储中间数据,为数据统计需要创建的中间
表数据,此数据一般是对多个维度的聚合数据,此层数据通常来源于DWD层的数据。 - 3.业务层DWS(Data WareHouse Service):存储宽表数据,此层数据是针对某个业务领域
的聚合数据,应用层的数据通常来源与此层,为什么叫宽表,主要是为了应用层的需要在这一层将
业务相关的所有数据统一汇集起来进行存储,方便业务层获取。此层数据通常来源与DWD和DWM
层的数据。
在实际计算中,如果直接从DWD或者ODS计算出宽表的统计指标,会存在计算量太大并且维
度太少的问题,因此一般的做法是,在DWM层先计算出多个小的中间表,然后再拼接成一张DWS
的宽表。由于宽和窄的界限不易界定,也可以去掉DWM这一层,只留DWS层,将所有的数据在放
在DWS亦可。
注:更细化一点可以分为:数仓明细层DWD、数仓基础数据层DWB、数仓服务数据层DWS、数据集市层DM、维度数据层DIM。
5.2.3 数据应用层(DA或APP)
前端应用直接读取的数据源;根据报表,专题分析的需求而计算生成的数据。
5.2.4 维表层
维表层一般包含俩部分数据:
- 1.高基数维度数据
- 2.低基数维度数据
最后放一个正在做的项目的数仓分层

6.渐变维(SCD)
6.1 渐变维概念
维度可以根据变化的剧烈程度主要分为无变化维度、缓慢变化维度,剧烈变化维度。例如一个人的相关信息,身份证号、姓名和性别等信息数据属于不变的部分,政治面貌和婚姻状态属于缓慢变化部分,而工作经历、工作单位和培训经历等在某种程度上属于急剧变化字段。
大多数的维度表随时间的迁移的缓慢变化的。
SCD有三种分类:
* SCD1(缓慢渐变类型1):通过更新维度记录直接覆盖已存在的值。
* SCD2(缓慢渐变类型2):在源数据发生变化的时候,给维度记录建立一个新的“版本”记录,从而维护维度历史。SCD2不删除、不修改已存在的数据。SCD2也叫拉链表(后面详细说这个拉链表)
* SCD3(缓慢渐变类型3):实际上SCD1和SCD2可以满足大多数需求,但还有其他的解决方案,比如说:SCD3。SCD3希望只维护更少的历史记录。
6.2拉链表
拉链表可以解决缓慢渐变维的问题。
拉链表不存储冗余的数据,只有某行的数据发生变化,才需要保存下来,相比每次全量同步会节省存储空间
可以查询到历史快照
概念:
* 拉链表是将历史数据和最新数据拉链到一张表中
* 拉链表和普通表的最大区别是,在表的最后多出俩个字段:start_date,end_date,一个表示改行数据的生效日期,一个表示改行数据的失效日期。
下面用一个demo展示拉链表的作用。
二、拉链表-Demo
-- 1、MySQL创建商品表
-- 创建数据库
drop database if exists demo;
CREATE DATABASE demo CHARACTER SET utf8 COLLATE utf8_general_ci; -- 创建商品表
create table if not exists demo.product(
goods_id varchar(50), -- 商品编号
goods_status varchar(50), -- 商品状态
createtime varchar(50), -- 商品创建时间
modifytime varchar(50) -- 商品修改时间
) ;
--2、Hive-ODS层建表
-- 创建表
drop database if exists demo cascade;
create database if not exists demo;
-- 创建ods层表
create table if not exists demo.ods_product(
goods_id string, -- 商品编号
goods_status string, -- 商品状态
createtime string, -- 商品创建时间
modifytime string -- 商品修改时间
)
partitioned by (dt string) --按照天分区
row format delimited fields terminated by '\t';
--3、Hive dw层创建拉链表
-- 创建拉链表
create table if not exists demo.dwd_product(
goods_id string, -- 商品编号
goods_status string, -- 商品状态
createtime string, -- 商品创建时间
modifytime string, -- 商品修改时间
dw_start_date string, -- 生效日期
dw_end_date string -- 失效日期
)
row format delimited fields terminated by '\t';
--4、MySQL数据库导入12月20日数据(4条数据)
insert into demo.product(goods_id, goods_status, createtime, modifytime) values
('001', '待审核', '2020-12-18', '2020-12-20'),
('002', '待售', '2020-12-19', '2020-12-20'),
('003', '在售', '2020-12-20', '2020-12-20'),
('004', '已删除', '2020-12-15', '2020-12-20');
--5、使用sqoop进行全量同步MySQL数据到Hive ods层表,创建Hive分区,并导入mysql的数据
-- 创建分区
alter table demo.ods_product add partition (dt='2020-12-20');
--将mysql数据导入Hive
sqoop import \
--connect jdbc:mysql://hadoop01:3306/demo \
--username root \
--password 123456 \
--table product \
--m 1 \
--delete-target-dir \
--fields-terminated-by '\t' \
--target-dir /user/hive/warehouse/demo.db/ods_product/dt=2020-12-20
--6 编写SQL从ods导入dw当天最新的数据,第一次构建拉链表
-- 从ods层导入dw当天最新数据
insert overwrite table demo.dwd_product
select
goods_id, -- 商品编号
goods_status, -- 商品状态
createtime, -- 商品创建时间
modifytime, -- 商品修改时间
modifytime as dw_start_date, -- 生效日期
'9999-12-31' as dw_end_date -- 失效日期
from
demo.ods_product
where
dt = '2020-12-20';
--7、增量导入2019年12月21日数据- MySQL数据库导入12月21日数据(6条数据)
--模拟更新数据
UPDATE demo.product SET goods_status = '待售', modifytime = '2020-12-21' WHERE goods_id = '001';
INSERT INTO demo.product(goods_id, goods_status, createtime, modifytime) VALUES
('005', '待审核', '2020-12-21', '2020-12-21'),
('006', '待审核', '2020-12-21', '2020-12-21');
--8、使用sqoop开发增量同步MySQL数据到Hive ods层表
--Hive创建分区
alter table demo.ods_product add partition (dt='2020-12-21');
--增量导入
sqoop import \
--connect jdbc:mysql://hadoop01:3306/demo \
--username root \
--password 123456 \
--target-dir /user/hive/warehouse/demo.db/ods_product/dt=2020-12-21 \
--query "select * from product where modifytime = '2020-12-21' and \$CONDITIONS" \
--delete-target-dir \
--fields-terminated-by '\t' \
--m 1
--8、编写SQL处理dw层历史数据,重新计算之前的dw_end_date
create temporary table if not exists demo.tmp_dwd_product(
goods_id string, -- 商品编号
goods_status string, -- 商品状态
createtime string, -- 商品创建时间
modifytime string, -- 商品修改时间
dw_start_date string, -- 生效日期
dw_end_date string -- 失效日期
)
row format delimited fields terminated by '\t';
insert overwrite table demo.tmp_dwd_product
select
t1.goods_id, -- 商品编号
t1.goods_status, -- 商品状态
t1.createtime, -- 商品创建时间
t1.modifytime, -- 商品修改时间
t1.dw_start_date, -- 生效日期(生效日期无需重新计算)
case when (t2.goods_id is not null and t1.dw_end_date = '9999-12-31' )
then '2020-12-20'
else t1.dw_end_date
end as dw_end_date -- 更新生效日期(需要重新计算)
from
demo.dwd_product t1
left join
(select * from demo.ods_product where dt='2020-12-21') t2
on t1.goods_id = t2.goods_id
union all
select
goods_id, -- 商品编号
goods_status, -- 商品状态
createtime, -- 商品创建时间
modifytime, -- 商品修改时间
modifytime as dw_start_date, -- 生效日期
'9999-12-31' as dw_end_date -- 失效日期
from
demo.ods_product where dt='2020-12-21';
select * from demo.tmp_dwd_product;
-- 将临时表的数据插入到最终的拉链表
insert overwrite table demo.dwd_product
select * from demo.tmp_dwd_product;
-- 查询最终的拉链表是否可用
select * from demo.dwd_product;
--10、拉链表查询
-- 查询2020-12-20数据
select * from dwd_product where dw_start_date <= '2020-12-20' and dw_end_date >= '2020-12-20' order by goods_id;
-- 查询当前订单的最新状态
select * from dwd_product where dw_end_date = '9999-12-31' order by goods_id ;