python非递归前序遍历二叉树_二叉树非递归dfs——简单思路搞定前中后序遍历
前言:相信很多同学都被二叉树非递归dfs的前中后序遍历方法弄的头疼。网上的答案,什么前中后序遍历各有一套写法,还有什么一个栈的写法,两个栈的写法。看起来能理解,一闭眼自己写都记不住。今天介绍一种用一种简单方法解决前中后序遍历的方法。
重点:二叉树非递归算法就是对递归算法的模拟。对于二叉树的深度优先搜索,其实前中后序遍历,它的搜索路径是一样的,区别就是在于节点的打印时机
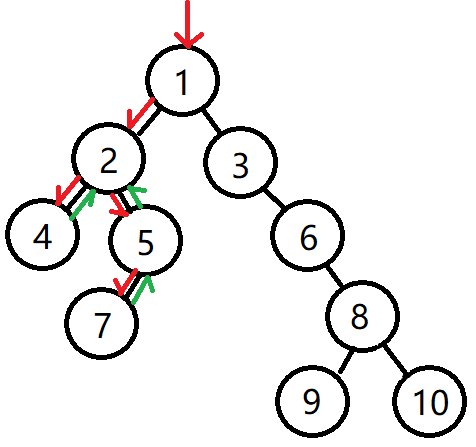
比如如上图示,该二叉树遍历顺序是,1 2 4 2 5 7 5 2 1 ......
对于一个有左右叶子结点的节点2,它被路线中出现过3次,第一次从1节点到2节点,第二次从4节点到2节点,第三次从5节点到2节点。
对于一个缺失左右叶子节点的节点,如5,7,可以添加叶子结点None,此时该节点在路线上的也是被经过3次,如下图节点5
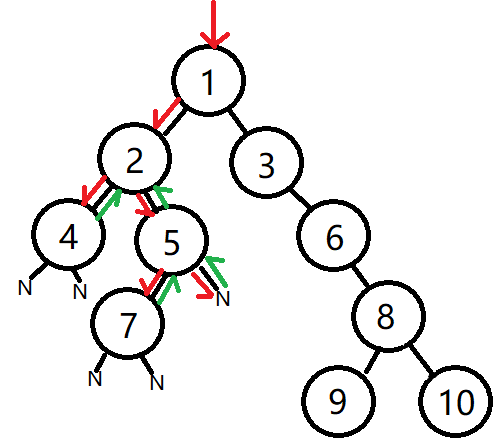
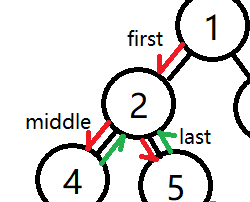
所有第一次进入该节点(从父节点进入)就被打印的,叫先序遍历,第二次进入该节点(从左子叶进入)被打印的叫中序遍历,第三次进入该节点(从右子叶进入)被打印的叫后序遍历
于是,我们可以把整个遍历过程记录下来,如下:
(1, 'first'), (2, 'first'), (4, 'first'), (4, 'middle'), (4, 'last'), (2, 'middle'), (5, 'first'), (7, 'first'), (7, 'middle'), (7, 'last'), (5, 'middle'), (5, 'last'), (2, 'last'), (1, 'middle').....
其中,first,middle,last是对这个节点第几次进入的一个标识flag,first代表第一次进入该节点,middle代表第二次进入该节点,last代表第三次进入该节点。这个遍历过程,其实已经完全表达了二叉树图形与遍历顺序,同时,first,middle,last又可以表示先序、中序、后序遍历的顺序
如果我们有了这个遍历顺序的list,然后按照first这个flag去过滤这个list,就能得到先序遍历的顺序。同理,按middle,last这个flag过滤,就能得到中序、后序遍历的顺序
遍历过程的获得:
1、初始化:建立一个临时temps= [],最终遍历顺序outputs = [],当前节点cur = None, 起始temps压入1节点和它的标识(1节点, 'first')
当前节点cur = None
最终outputs = []
临时temps= [(1节点, 'first')]
2、temps头部pop出 (1节点, 'first'), 将此节点压入outputs ,当前节点cur=(1节点, 'first'), 判断flag=‘first’,代表第一次访问,将[(2节点, 'first'), (1节点, 'middle'), (3节点, 'first'),(1节点, 'last')]压入temps的头部
cur = (1节点, 'first')
outputs = [(1节点, 'first')]
temps= [(2节点, 'first'),(1节点, 'middle'), (3节点, 'first'), (1节点, 'last')]
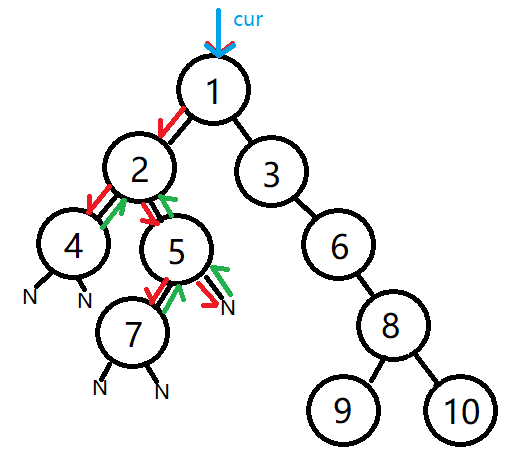
3、第二次,循环重复2步骤,temps头部pop出 (2节点, 'first'), 将此节点压入outputs.....,temps压入[(4节点, 'first'), (2节点, 'middle'), (5节点, 'first'),(2节点, 'last')]
cur = (2节点, 'first')
outputs = [(1节点, 'first'), (2节点, 'first')]
temps= [(4节点, 'first'), (2节点, 'middle'), (5节点, 'first'),(2节点, 'last'),(1节点, 'middle'), (3节点, 'first'), (1节点, 'last')]
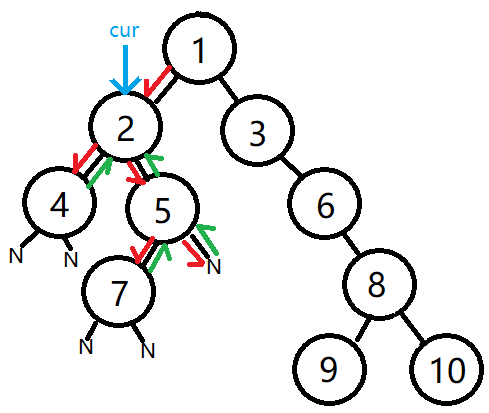
4、第三次,循环重复,但由于节点4下没有子节点,只要压入[(4节点, 'middle'),(4节点, 'last')]
cur = (4节点, 'first')
outputs = [(1节点, 'first'), (2节点, 'first'), (4节点, 'first'),]
temps= [(4节点, 'middle'),(4节点, 'last'),(2节点, 'middle'), (5节点, 'first'),(2节点, 'last'),(1节点, 'middle'), (3节点, 'first'), (1节点, 'last')]
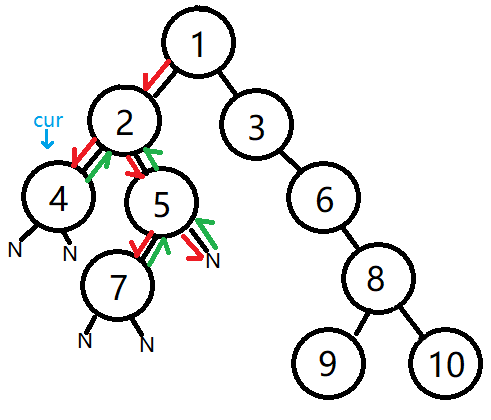
5、第四次,当前节点cur的flag是middle或者是last时,直接将cur压入outputs即可
cur = (4节点, 'middle')
outputs = [(1节点, 'first'), (2节点, 'first'), (4节点, 'first'),(4节点, 'middle')]
temps= [(4节点, 'last'),(2节点, 'middle'), (5节点, 'first'),(2节点, 'last'),(1节点, 'middle'), (3节点, 'first'), (1节点, 'last')]
第五次:
cur = (4节点, 'last')
outputs = [(1节点, 'first'), (2节点, 'first'), (4节点, 'first'),(4节点, 'middle'),(4节点, 'last')]
temps= [(2节点, 'middle'), (5节点, 'first'),(2节点, 'last'),(1节点, 'middle'), (3节点, 'first'), (1节点, 'last')]
6、重复如上步骤,直到temps为空
树的定义:
class Node:
def __init__(self,value=None,left=None,right=None):
self.value=value
self.left=left #左子树
self.right=right #右子树
tree = Node(1, Node(2, Node(4, ), Node(5, Node(7, ), None)), Node(3, None, Node(6, None, Node(8, Node(9, ), Node(10, )))))
核心代码:
def dfs(root):
temps = [(root, 'first')]
outputs = []
while temps:
cur_q = temps.pop()
cur_node = cur_q[0]
flag = cur_q[1]
outputs.append(cur_q)
if flag == 'first':
temps.append((cur_node, 'last'))
if cur_node.right != None:
temps.append((cur_node.right, 'first'))
temps.append((cur_node, 'middle'))
if cur_node.left != None:
temps.append((cur_node.left, 'first'))
return outputs
outputs = dfs(tree)
#深度优先的遍历过程
all_values = [(i[0].value, i[1]) for i in outputs]
#先序遍历
pre_order = [i[0] for i in all_values if i[1] == 'first']
#中序遍历
middle_order = [i[0] for i in all_values if i[1] == 'middle']
#后序遍历
last_order = [i[0] for i in all_values if i[1] == 'last']
print(all_values)
print(pre_order)
print(middle_order)
print(last_order)
结果:
all_values:
[(1, 'first'), (2, 'first'), (4, 'first'), (4, 'middle'), (4, 'last'), (2, 'middle'), (5, 'first'), (7, 'first'), (7, 'middle'), (7, 'last'), (5, 'middle'), (5, 'last'), (2, 'last'), (1, 'middle'), (3, 'first'), (3, 'middle'), (6, 'first'), (6, 'middle'), (8, 'first'), (9, 'first'), (9, 'middle'), (9, 'last'), (8, 'middle'), (10, 'first'), (10, 'middle'), (10, 'last'), (8, 'last'), (6, 'last'), (3, 'last'), (1, 'last')]
#先序遍历
[1, 2, 4, 5, 7, 3, 6, 8, 9, 10]
#中序遍历
[4, 2, 7, 5, 1, 3, 6, 9, 8, 10]
#后序遍历
[4, 7, 5, 2, 9, 10, 8, 6, 3, 1]
核心代码也就十几行,关键是模拟遍历的顺序,再从中提取先中后序遍历顺序。
本文地址:https://blog.csdn.net/doufuxixi/article/details/109629820
希望与广大网友互动??
点此进行留言吧!