ThreadLocal内存泄漏分析以及Dubbo使用ThreadLocal时的优化
一、基本作用
总的来说ThreadLocal就是作为一个名字或者说key,用来在各个线程私有的ThreadLocalMap中存储各自的value,而使其互不影响,做到线程隔离。
ThreadLocal还有另外一个作用就是在线程内传值,某一个方法内set,在另一个方法中get,避免通过方法参数显示传递(有些场景还不方便传参),这种用法可以不重写initialValue方法(默认初始值是 null)。
ThreadLocal<String> threadLocal = new ThreadLocal<String>(){
@Override
protected String initialValue() {
return "abc";
}
};
创建ThreadLocal对象时可以复写它的initialValue()方法,它的作用是,无论在某个线程内如何修改,在另一个线程内第一次调用ThreadLocal的get方法时,获取到的值就是initialValue()方法的返回值。这样每个线程就可以在自己的本地内存中维护自己的变量副本。源码如下:
public T get() {
Thread t = Thread.currentThread();
//线程内第一次获取map时是null
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
//先初始化
return setInitialValue();
}
private T setInitialValue() {
T value = initialValue();
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
//创建map
createMap(t, value);
return value;
}
//在ThreadLocal对象创建时复写时设置的值
protected T initialValue() {
return null;
}
void createMap(Thread t, T firstValue) {
t.threadLocals = new ThreadLocalMap(this, firstValue);
}
ThreadLocalMap是Thread的一个成员变量,它的权限是default,也就是说线程的threadLocals变量必须都过ThreadLocal对象来访问。
/* ThreadLocal values pertaining to this thread. This map is maintained
* by the ThreadLocal class. */
ThreadLocal.ThreadLocalMap threadLocals = null;
测试代码
ThreadLocal<String> threadLocal = new ThreadLocal<String>(){
@Override
protected String initialValue() {
return "abc";
}
};
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
String s = threadLocal.get();
System.out.println(Thread.currentThread().getName()+" : "+threadLocal.get());
threadLocal.set("bcd");
}
});
t1.start();
try {
t1.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
new Thread(new Runnable() {
@Override
public void run() {
String s = threadLocal.get();
System.out.println(Thread.currentThread().getName()+" : "+threadLocal.get());
threadLocal.set("efg");
}
}).start();
引用关系如下
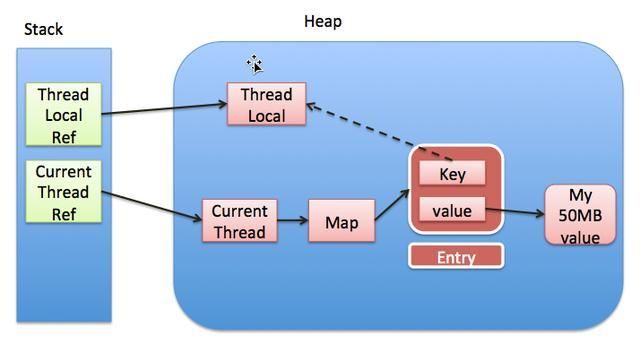
二、内存泄漏
- 内存泄漏: 程序中已经动态分配的堆内存由于某种原因不会再次访问了或者无法访问了,但对象依然是可达的(存在从GC root出发的引用链),无法被GC,造成系统内部的浪费, 导致程序运行速度减缓甚至系统崩溃等严重结果. 内存泄漏的堆积终将导致内存溢出。
2.1 ThreadLocalMap的结构
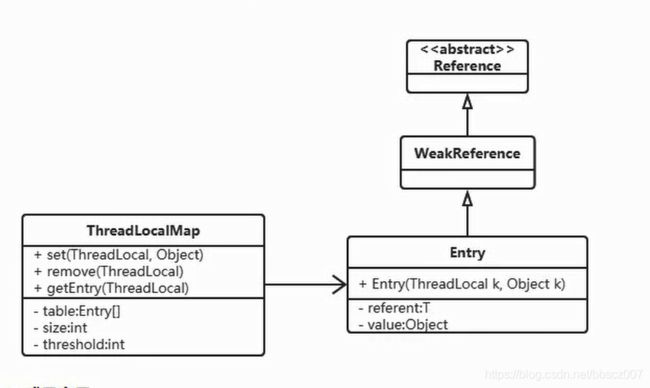
ThreadLocalMap是ThreadLocal的静态内部类, 没有实现Map接口, 用独立的方式实现了Map的功能, 其内部的Entry也是独立实现,且继承了WeakReference,下面我们分析为什么要用弱引用。
/**
* ThreadLocalMap is a customized hash map suitable only for
* maintaining thread local values. No operations are exported
* outside of the ThreadLocal class. The class is package private to
* allow declaration of fields in class Thread. To help deal with
* very large and long-lived usages, the hash table entries use
* WeakReferences for keys. However, since reference queues are not
* used, stale entries are guaranteed to be removed only when
* the table starts running out of space.
*/
static class ThreadLocalMap {
/**
* The entries in this hash map extend WeakReference, using
* its main ref field as the key (which is always a
* ThreadLocal object). Note that null keys (i.e. entry.get()
* == null) mean that the key is no longer referenced, so the
* entry can be expunged from table. Such entries are referred to
* as "stale entries" in the code that follows.
*/
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
2.2 如果Entry没有继承弱引用
大前提:正如前面所说,ThreadLocalMap是Thread的一个成员变量,它的权限是default,也就是说线程的threadLocals变量必须都过ThreadLocal对象来访问。
如图,Entry里的key是一个指向ThreadLocal的强引用。当栈上对ThreadLocal对象的引用在代码中出了作用域(栈上没有指针指向该对象),如果当前线程没有被销毁还在运行,那么ThreadLocalMap对象就不会被回收,Entry对象也不会被GC,它的key引用了堆里的ThreadLocal对象,这将导致堆里的ThreadLocal对象对象无法被GC,value也不会被GC,可同时又无法在程序中访问到它们,也就造成内存泄漏。
可见,如果Entry没有继承弱引用,那么造成内存泄漏的大小有整个Entry对象。
2.3 如果Entry继承弱引用
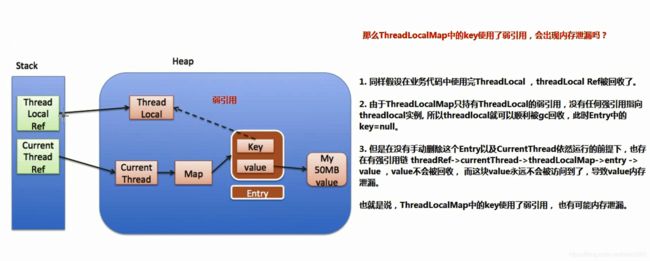
如图,Entry里的key是一个指向ThreadLocal的强引用。当栈上对ThreadLocal对象的引用在代码中出了作用域(简单地理解为删除了图里那个指针),如果当前线程没有被销毁还在运行,那么ThreadLocalMap对象就不会被回收,Entry对象也不会被GC,但由于它的key若引用了堆里的ThreadLocal对象,GC的时候ThreadLocal对象会被回收,也就是key会变为null,此时value依旧不会被回收,仍然有内存泄漏。
可见,如果Entry继承弱引用,那么造成内存泄漏的大小只有Entry对象里的value大小。
2.4 内存泄漏的真实原因
比较以上两种情况,我们就会发现:内存泄漏的发生跟 ThreadLocalIMap 中的 key 是否使用弱引用是没有关系的。在以上两种内存泄漏的情况中,都有两个前提:
- 没有手动删除这个 Entry
- Current Thread 依然运行
第一个很好解决,只要在使用完下 ThreadLocal ,调用其 remove 方法翻除对应的 Entry ,就能避免内存泄漏。
第二个,由于ThreadLocalMap 是 Thread 的一个成员变量,被当前线程所引用,所以它的生命周期跟 Thread 一样长。那么在使用完 ThreadLocal 的使用,如果当前Thread 也随之执行结束, ThreadLocalMap 自然也会被 GC回收,从根源上避免了内存泄漏,然而,这在实际开发中这是很难做到的。
综上, ThreadLocal 内存泄漏的根源是:由于ThreadLocalMap 的生命周期跟 Thread 一样长,而 Thread与ThreadLocal 的生命周期不一样长, 如果没有手动删除对应 key 就会导致内存泄漏。
此外,回答此类问题最好再补充ThreodLocalMap 是 Thread 的一个被default修饰的属性,必须都过ThreadLocal对象来访问。
2.5 为什么要用弱引用
无论 ThreadLocalMap 中的 key 使用哪种类型引用都无法完全避免内存泄漏,跟使用弱引用没有关系。
要避免内存泄漏有两种方式:
- 使用完 ThreadLocal ,调用其
remove方法删除对应的 Entry - 使用完 ThreadLocal ,当前 Thread 也随之运行结束
相对第一种方式,第二种方式显然更不好控制,特别是使用线程池的时候,线程结束时不一定会销毁。 也就是说,只要记得在使用完ThreadLocal 及时的调用 remove,就不会内存泄漏。
那为什么还要用弱引用?
因为这是JDK为了避免内存泄漏而做的特殊设计,用了弱引用,即使没有手动调用remove方法,ThreadLocal 对象也会被回收,也就是Entry对象的key会变为null,而在ThreadLocal中调用set/get/remove的时候最终都会调用expungeStaleEntry方法删除key为null的Entry对象(有多少个ThreadLocal对象就有多少个Entry对象),多了一层保障。
private int expungeStaleEntry(int staleSlot) {
Entry[] tab = table;
int len = tab.length;
// expunge entry at staleSlot
tab[staleSlot].value = null;
tab[staleSlot] = null;
size--;
// Rehash until we encounter null
Entry e;
int i;
for (i = nextIndex(staleSlot, len);
(e = tab[i]) != null;
i = nextIndex(i, len)) {
ThreadLocal<?> k = e.get();
if (k == null) {
//值设为null
e.value = null;
//hash表的相应位置设为null
tab[i] = null;
size--;
} else {
int h = k.threadLocalHashCode & (len - 1);
if (h != i) {
tab[i] = null;
// Unlike Knuth 6.4 Algorithm R, we must scan until
// null because multiple entries could have been stale.
while (tab[h] != null)
h = nextIndex(h, len);
tab[h] = e;
}
}
}
return i;
}
三、几个常见问题
3.1 ThreadLocalMap如何解决Hash冲突?
ThreadLocalMap中解决Hash的方法并非链表式,而是采用线性探测的方法,一种开放寻址法,一个不行找下一个。
private void set(ThreadLocal<?> key, Object value) {
// We don't use a fast path as with get() because it is at
// least as common to use set() to create new entries as
// it is to replace existing ones, in which case, a fast
// path would fail more often than not.
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
for (Entry e = tab[i];
e != null;
//如果当前位置不能放,就找下一个
/*
private static int nextIndex(int i, int len) {
return ((i + 1 < len) ? i + 1 : 0);
}
*/
e = tab[i = nextIndex(i, len)]) {
ThreadLocal<?> k = e.get();
if (k == key) {
e.value = value;
return;
}
if (k == null) {
replaceStaleEntry(key, value, i);
return;
}
}
tab[i] = new Entry(key, value);
int sz = ++size;
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}
3.2 为什么ThreadLocal 对象建议使用 static 修饰
在阿里的开发手册里建议使用ThreadLocal 时用 static 修饰。这个变量是针对一个线程内所有操作共享的,设置为静态变量,所有此类实例共享此静态变量 ,也就是说在类第一次被使用时装载,只分配一块存储空间,所有此类的对象(只要是这个线程内定义的)都可以操控这个变量。不然每次创建ThreadLocal 对象所在类的对象时,会导致创建了很多重复的ThreadLocal 对象,因为对于当前线程来说它的ThreadLocalMap对象只会初始化一次,也就导致了有多个Entry对象,造成浪费。
另一个原因是使用static修饰可以让我们在任何位置都可以快速的获取到当前线程对应的ThreadLocal对象。
四、Dubbo使用ThreadLocal时的优化
使用Dubbo时可以通过 RpcContext的 setAttachment 和 getAttachment 在服务消费方和提供方之间进行参数的隐式传递。

在旧版本中是利用ThreadLocal实现的,而在新版本中已经优化为InternalThreadLocal,基于数组存储,读写效率比HashMap好。源码中写道
Although seemingly very subtle, it yields slight performance advantage over using a hashtable, and it is useful when accessed frequently.
意思就是尽管看起来改动非常小,但是在频繁读写的场景里相比Hash表还是有非常显著的性能优化的。
有意思的是源码中写了这个类参考自netty。

RpcContext的部分源码
// FIXME REQUEST_CONTEXT
private static final InternalThreadLocal<RpcContext> LOCAL = new InternalThreadLocal<RpcContext>() {
@Override
protected RpcContext initialValue() {
return new RpcContext();
}
};
// FIXME RESPONSE_CONTEXT 服务端想给消费端返回的数据
private static final InternalThreadLocal<RpcContext> SERVER_LOCAL = new InternalThreadLocal<RpcContext>() {
@Override
protected RpcContext initialValue() {
return new RpcContext();
}
};
//存储数据是放在attachment这个成员变量上。
private final Map<String, String> attachments = new HashMap<>();
-
对于普通Thread ,最后用的还是ThreadLocal,这个对象是
InternalThreadLocalMap的静态变量slowThreadLocalMapprivate static ThreadLocal<InternalThreadLocalMap> slowThreadLocalMap = new ThreadLocal<InternalThreadLocalMap>();每一个Thread 对应一个它自己的ThreadLocalMap,它的其中一个key就是
slowThreadLocalMap,value是这个线程对应的InternalThreadLocalMap对象,而InternalThreadLocalMap对象有一个Object数组,这个数组初始都被同一个Object对象填充。至于某个值存在数组的哪个索引位置取决于创建
InternalThreadLocal对象是从InternalThreadLocalMap获取到的全局唯一index,这个值会保存在InternalThreadLocal对象里。要注意的是Object数组的0位置已经被提前占用,用于记录要删除的InternalThreadLocal对象,所以真正存放数据是从1位置开始的,比如RpcContext的成员变量LOCAL里初始化的RpcContext对象放在1位置,SERVER_LOCAL的RpcContext对象放在2位置。用
InternalThreadLocalMap作value的好处是:在一个ThreadLocal里保存多个数据时,如果value用Map,那么多一次hash计算的消耗,如果用数组或集合的话,我们需要手动维护记录哪个位置存的是谁。而用InternalThreadLocalMap的话,需要保存多个数据时我们只需要创建多个InternalThreadLocal即可,创建的同时就确定了在数组里的索引位置。
大概的引用关系如下:
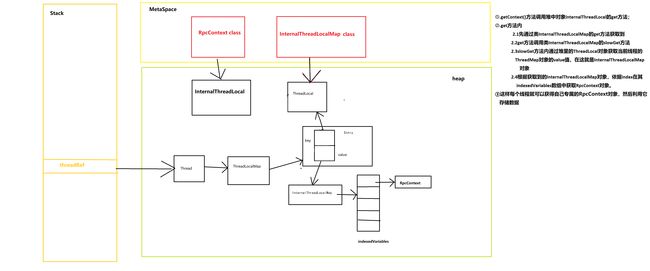
- 对于Dubbo自己定义的线程类
InternalThread,每一个InternalThread对象对应一个InternalThreadLocalMap对象,每创建一个InternalThreadLocal对象,它的初始值就会存放在InternalThreadLocalMap内Object数组对应的索引位置。相比传统的ThreadLocal它减少了hash计算的消耗。
public class InternalThread extends Thread {
private InternalThreadLocalMap threadLocalMap;
public InternalThread() {
}
}
下面是普通线程Thread里调用RpcContext的get方法的流程。

测试代码
InternalThreadLocal<String> stringInternal = new InternalThreadLocal<String>();
InternalThreadLocal<String> stringInternal2 = new InternalThreadLocal<String>();
String s = stringInternal.get();
System.out.println(s);
new InternalThread() {
public void run() {
//可以借此观察数据在InternalThreadLocalMap里存放的索引位置
RpcContext context = RpcContext.getContext();
System.out.println(context);
stringInternal.set("111");
stringInternal2.set("333");
System.out.println(stringInternal.get());
}
}.start();
new Thread() {
public void run() {
RpcContext context = RpcContext.getContext();
RpcContext serverContext = RpcContext.getServerContext();
System.out.println(context);
stringInternal.set("111");
stringInternal2.set("333");
System.out.println(stringInternal.get());
}
}.start();
new Thread() {
public void run() {
RpcContext context = RpcContext.getContext();
System.out.println(context);
stringInternal.set("222");
System.out.println(stringInternal.get());
}
}.start();
String s2 = stringInternal.get();
System.out.println(s2);
参考:
Java中引用类型 和 ThreadLocal,内容整理自视频教程:ThreadLocal