ClickHouse进阶(十一):Clickhouse数据字典-1

进入正文前,感谢宝子们订阅专题、点赞、评论、收藏!关注IT贫道,获取高质量博客内容!
个人主页:含各种IT体系技术,IT贫道_Apache Doris,大数据OLAP体系技术栈,Kerberos安全认证-CSDN博客
订阅:拥抱独家专题,你的订阅将点燃我的创作热情!
点赞:赞同优秀创作,你的点赞是对我创作最大的认可!
⭐️ 收藏:收藏原创博文,让我们一起打造IT界的荣耀与辉煌!
✏️评论:留下心声墨迹,你的评论将是我努力改进的方向!
博主个人B栈地址:豹哥教你大数据的个人空间-豹哥教你大数据个人主页-哔哩哔哩视频
目录
1. 字典创建
2. 字典查询
2.1 元数据查询
2.2 数据查询
3. 字典删除
4. 分布式字典表
数据字典是clickhouse提供一种非常简单、实用的存储媒介,他以键值和属性映射的形式定义数据。字典中的数据会主动或者被动加载到内存并支持动态更新。由于字典数据常驻内存的特性,所以非常适合保存常量或经常使用的维度表数据,以避免不必要的JOIN查询。
数据字典分为内置与扩展两种形式,内置字典是clickhouse默认自带的字典,外部字典是用户通过自定义配置实现的字典。clickhouse目前只有一种内置字典:Yandex.Metrica字典,这个字典是clickhouse自家产品上的字典,设计目的是快速存取地理数据,但是clickhouse没有将地理数据公布出来,内置字典默认是禁用状态,想要使用内置字典还需要模拟数据然后开启,功能十分有限。在使用clickhouse 字典时,外部扩展字典才是更加常用的功能。
在正常情况下,字典中的数据只能通过字典函数访问,clickhouse设置了一类字典函数,专门用于字典数据的取用。我们也可以通过字典表将字典数据挂载到一张代理的数据表下,从而访问字典中的数据,也可以实现数据表与字典数据的join查询。
1. 字典创建
在clickhouse20版本之前创建外部数据字典需要创建大量的xml文件来实现,在clickhouse20.1版本之后引入了“Create dictionary”语句创建数据字典,创建字典表举例操作如下:
#创建新的库并使用
create database dic_test_db;
use dic_test_db;
#创建普通MergeTree表,描述地理位置表
CREATE TABLE loc_info(
uuid String,
local_id UInt64,
local_name String
)engine=MergeTree()
order by uuid;
#创建 数据字典表
CREATE DICTIONARY dic_loc_info(
local_id UInt64,
local_name String
)PRIMARY KEY local_id
SOURCE(clickhouse(
HOST 'node1'
PORT 9000
USER 'default'
TABLE 'loc_info'
PASSWORD ''
DB 'dic_test_db'
))
LIFETIME (MIN 1 MAX 10)
LAYOUT(HASHED());
注意:以上创建字典表的参数解释如下:
HOST:指定clickhouse节点名称
PORT:指定clickhouse端口,默认9000
USER:连接clickhouse用户名
PASSWORD:连接clickhouse用户名对应密码
TABLE:此字典表映射的表名,字典表中的列名与映射表中列名一致。
DB:字典表映射表所在的库
LIFETIME:字典的自动更新频率
LAYOUT:字典的类型,决定了数据在内存中以何种结构组织和存储。目前扩展字典共拥有7种类型。
#创建普通用户表
CREATE TABLE person_info(
person_id String,
name String,
age UInt8,
loc_id UInt64
)engine=MergeTree()
order by person_id;
#向表loc_info中插入以下数据:
insert into loc_info values ('uuid1',100,'北京'),('uuid2',101,'上海'),('uuid3',102,'广州');
#向表 person_info中插入以下数据:
insert into person_info values ('1','张三',18,102),('2','李四',19,101),('1','王五',20,100);
2. 字典查询
2.1 元数据查询
通过system.dictionaries系统表可以查询扩展字典的元数据信息。查询语句如下:
select name,type,key,attribute.names,attribute.types,source from system.dictionaries;![]()
注意:以上查询字段的意义如下:
name:字典的名称,使用字典函数时需要通过字典名称访问数据。
type:字典所属类型。
key:字典的key值,数据通过key值定位。
attribute.names:属性名称,以数组形式保存。
attribute.types:属性类型,以数组形式保存。
source:数据源信息。
2.2 数据查询
字典数据使用时可以通过字典函数获取,如下:“dictGetString”就是字典函数,查询使用字典如下:
#使用dic查询数据
select person_id,name,age,loc_id,dictGetString('dic_test_db.dic_loc_info','local_name',loc_id) as local_name from person_info;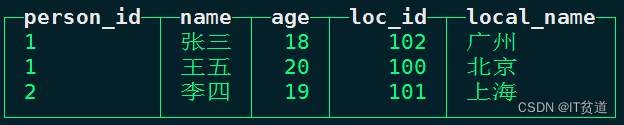
dictGet('字典名称','获取的值','查询的值(参数)'),如果字典类型是复合型key(参照字典类型complex_key_hashed/complex_key_cache)对应字典类型,在使用dicGet时需要使用元组作为参数,例如:dicGetString('字典名称','获取的值',tuple(col1,col2))。
除了dictGetString外,clickhouse还提供了一系列以dictGet为前缀的字典函数,具体如下:
- 获取整形数据的函数:
dictGetUInt8,dictGetUInt16,dictGetUInt32,dictGetUInt64,dictGetInt8,dictGetInt16,dictGetInt32,dictGetInt64。
- 获取浮点数据的函数:
dictGetFloat32,dictGetFloat64
- 获取日期数据的函数:
dictGetDate,dictGetFloat64
- 获取字符串数据的函数:
dictGetString,dictGetUUID
我们在使用时,也可以直接使用dictGet(xx)传入对应的参数即可。
3. 字典删除
删除字典语法如下:
DROP DICTIONARY dic_name;
#将dic_loc_info删除
node1 :) drop dictionary dic_loc_info;4. 分布式字典表
字典表也是支持分布式,创建语句如下,在clickhouse中我们可以像创建分布式表一样使用字典表。
CREATE DICTIONARY [IF NOT EXISTS] [db.]dictionary_name [ON CLUSTER cluster]
(
key1 type1 [DEFAULT|EXPRESSION expr1] [IS_OBJECT_ID],
key2 type2 [DEFAULT|EXPRESSION expr2] ,
attr1 type2 [DEFAULT|EXPRESSION expr3] [HIERARCHICAL|INJECTIVE],
attr2 type2 [DEFAULT|EXPRESSION expr4] [HIERARCHICAL|INJECTIVE]
)
PRIMARY KEY key1, key2
SOURCE(SOURCE_NAME([param1 value1 ... paramN valueN]))
LAYOUT(LAYOUT_NAME([param_name param_value]))
LIFETIME({MIN min_val MAX max_val | max_val})使用案例如下:
#在node1节点上创建表 loc_info并插入数据
CREATE TABLE loc_info(
uuid String,
local_id UInt64,
local_name String
)engine=MergeTree()
order by uuid;
insert into loc_info values ('uuid1',100,'北京');
#在node2节点上创建表 loc_info 并插入数据
CREATE TABLE loc_info(
uuid String,
local_id UInt64,
local_name String
)engine=MergeTree()
order by uuid;
insert into loc_info values ('uuid2',101,'上海');
#在node3节点上创建表 loc_info 并插入数据
CREATE TABLE loc_info(
uuid String,
local_id UInt64,
local_name String
)engine=MergeTree()
order by uuid;
insert into loc_info values ('uuid3',102,'广州');
#在clickhoiuse集群中创建分布式字典dic_loc_info
CREATE DICTIONARY dic_loc_info on cluster clickhouse_cluster_3shards_1replicas(
local_id UInt64,
local_name String
)PRIMARY KEY local_id
SOURCE(ClickHouse(
HOST 'localhost' --注意这里写localhost
PORT 9000
USER 'default'
TABLE 'loc_info'
PASSWORD ''
DB 'default'
))
LIFETIME (MIN 1 MAX 10)
LAYOUT(HASHED());
注意:以上在clickhouse集群中创建字典表的本质就是在clickhouse集群每台节点上创建对应的字典表。
#创建分布式字典表
Create table xxx on cluster clickhouse_cluster_3shards_1replicas (
local_id UInt64,
local_name String
)engine = Distributed(ClickHouse_cluster_3shards_1replicas,default,dic_loc_info,local_id);
#在node1,node2,node3任意节点上查看分布式字典表数据
node1 :) select * from xxx;
如需博文中的资料请私信博主。