浏览器面试题
浏览器面试题
- 1.常见的浏览器内核有哪些?
- 2.浏览器的主要组成部分有哪些?
- 3.说一说从输入URL到页面呈现发生了什么?
- 4.浏览器重绘域重排的区别?
- 5.CSS加载会阻塞DOM吗?
- 6.JS会阻塞页面吗?
- 7.说一说浏览器的缓存机制?
- 8.Cookie相关与HttpOnly
- 9.说说跨站请求伪造(CSRF)攻击
- 10.浏览器的存储
- 11.HTTP与HTTPS、第三方证书工作原理、以及HTTP各个版本
- react原理fiber调度算法
- React中的diff算法
1.常见的浏览器内核有哪些?
浏览器的内核分成两部分:
渲染引擎和JS引擎(⚠️注意:我们常说的浏览器内核就是指JS引擎)
FireFox 和 Chrome 使用不同的渲染引擎和 JavaScript 引擎:
-
FireFox:
- 渲染引擎: Gecko
- JavaScript 引擎: SpiderMonkey
-
Chrome (以及大多数基于Chromium的浏览器,如新的Microsoft Edge):
- 渲染引擎: Blink (注意:Blink是从WebKit分叉出来的,WebKit是早期Chrome和现在的Safari使用的渲染引擎)
- JavaScript 引擎: V8
2.浏览器的主要组成部分有哪些?
浏览器是一个复杂的应用程序,其主要组件如下:
-
用户界面 (User Interface): 这部分包括地址栏、书签栏、前进/后退按钮、刷新按钮等。简而言之,除了您在浏览页面时看到的内容外,用户界面包括了其他所有部分。
-
浏览器引擎 (Browser Engine): 该模块在用户界面和渲染引擎之间起到中介的作用,传递命令。
-
渲染引擎 (Rendering Engine): 负责显示请求的内容。如果请求的是HTML内容,渲染引擎就负责解析HTML和CSS,并将解析后的内容显示在屏幕上。
-
网络 (Networking): 用于网络调用,例如HTTP请求。它负责发送查询和下载网页、图片、其他资源。
-
JavaScript解释器 (JavaScript Engine): 解析和执行JavaScript来实现网页的动态功能。
-
数据存储 (Data Storage): 这是持久层。浏览器需要在本地存储各种数据,如cookies。HTML5引入了web storage,允许网页本地存储数据。
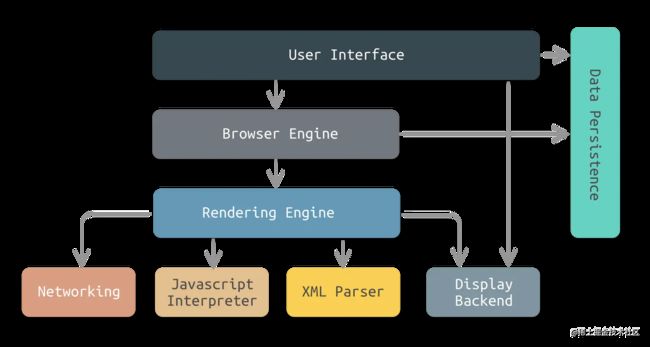
交互流程:
-
当您在地址栏中输入URL并按下Enter时,用户界面指示浏览器引擎加载请求的网页。
-
浏览器引擎告知网络模块获取该URL的内容。
-
一旦网络模块完成下载网页的主要内容(通常是HTML文件),它将数据传递给渲染引擎。
-
渲染引擎开始解析HTML,并在解析过程中遇到其他资源(如CSS文件、JavaScript文件或图片)时请求网络模块加载它们。
-
如果渲染引擎在解析HTML时遇到JavaScript,并且JavaScript没有被延迟或异步加载(deffer\async异步加载js),则渲染引擎暂停HTML解析并将控制权交给JavaScript引擎。一旦JavaScript引擎完成执行,控制权返回渲染引擎。
-
渲染引擎根据HTML和CSS创建渲染树,并在屏幕上显示内容。
-
JavaScript可以用来修改渲染后的页面,它通过DOM(文档对象模型)与页面内容交互。
-
用户与页面交互(例如点击按钮)可能会触发JavaScript代码的执行,这可能会导致页面内容的更改,进而可能会导致重新渲染部分或全部页面。
-
浏览器的数据存储模块在整个过程中也会起到作用,例如,当页面设置或查询cookie时。
⚠️注意:与大多数浏览器不同的是,谷歌(Chrome)浏览器的每个标签页都分别对应一个渲染引擎实例。每个标签页都是一个独立的进程(进程和线程)
3.说一说从输入URL到页面呈现发生了什么?
这个题可以说是面试最常见也是一道可以无限难的题了,一般面试官出这道题就是为了考察你的前端知识深度。
-
URL解析:浏览器首先会解析输入的URL,提取出协议**(如HTTP、HTTPS)**、域名(如www.example.com)和路径等信息。
-
DNS解析:浏览器会向本地DNS解析器发送一个DNS查询请求,以获取输入域名对应的IP地址。如果本地DNS缓存中存在域名的解析结果,则直接返回IP地址;否则,本地DNS解析器会向根DNS服务器、顶级域名服务器和授权域名服务器等级联查询,最终获取到域名的IP地址。
-
建立TCP连接:浏览器使用获取到的IP地址,通过TCP/IP协议与服务器建立网络连接。这个过程通常经历三次握手,确保客户端和服务器之间的可靠连接。
-
发起HTTP请求:一旦建立了TCP连接,浏览器就会发送一个HTTP请求到服务器。请求中包含了请求行(请求方法,如GET或POST,以及请求的资源路径)、请求头(如Accept、User-Agent等)和请求体(对于POST请求)等信息。
-
服务器处理请求:服务器接收到浏览器发送的HTTP请求后,会根据请求的路径和参数等信息,处理请求并生成相应的响应。
-
接收响应:浏览器接收到服务器发送的HTTP响应后,会解析响应头和响应体。响应头包含了状态码(如200表示成功,404表示资源未找到)和其他元信息,响应体包含了服务器返回的实际内容(如HTML、CSS、JavaScript、图片等)。
-
渲染页面:浏览器开始解析响应体中的HTML文档,并构建DOM(文档对象模型)树。同时,它还会解析CSS文件和JavaScript代码,并进行样式计算、布局和渲染。最终,将解析后的内容显示在用户界面上,呈现出完整的页面。
-
关闭TCP连接(四次挥手):一旦页面呈现完成,浏览器会关闭与服务器之间的TCP连接。如果页面中存在其他资源(如图片、脚本、样式表),则会继续发送相应的HTTP请求来获取这些资源,并重复执行步骤5到步骤7,直至所有资源加载完成。
4.浏览器重绘域重排的区别?
- 重排: 布局改变,重排成本高
- 重绘: 样式改变,布局没变
重绘不一定导致重排,但重排一定绘导致重绘
如何触发重绘和重排?
任何改变 用来构建渲染树的信息 都会导致一次重排或重绘:
- 添加、删除、更新DOM节点
- 通过display: none隐藏一个DOM节点-触发重排和重绘
- 通过visibility: hidden隐藏一个DOM节点-只触发重绘,因为没有几何变化
如何避免重绘或重排?
- 集中改变样式:比如使用class的方式来集中改变样式
- 使用document.createDocumentFragment():我们可以通过createDocumentFragment创建一个游离于DOM树之外的节点,然后在此节点上批量操作,最后插入DOM树中,因此只触发一次重排
- 提升为合成层
使用 CSS 的 will-change 属性将元素提升为合成层。有以下优点:交由 GPU 合成,比 CPU 处理要快 - 使用 CSS3 的 transform 和 opacity 属性来进行动画效果,它们可以利用 GPU 加速,减少重排的发生。
5.CSS加载会阻塞DOM吗?
先上结论:
- CSS不会阻塞DOM的解析,但会阻塞DOM的渲染
- CSS会阻塞JS执行,但不会阻塞JS文件的下载
为什么CSS不会阻塞DOM的解析,但会阻塞DOM的渲染?(DOM和CSSOM通常是并行构建的,所以CSS加载不会阻塞DOM的解析,前一个DOM的解析指的是HTML的解析构建DOM树,后一个DOM的渲染指的是DOM与CSSOM结合的渲染树的渲染)
CSS解析之前,由HTML解析出来的DOM已经开始构建?(并行的,但是,如果dom解析到一半,遇到js改变css样式则需要等待css被加载完毕,这也是为什么css会阻塞JS的执行)
-
DOM 构建: 当浏览器开始接收到HTML内容时,它会开始构建DOM(Document Object Model)。DOM是一个树形结构,表示页面的内容结构。DOM的构建是逐步的,也就是说,当浏览器接收到HTML内容的一部分时,它就开始构建DOM的这一部分。
-
CSSOM 构建: 同时,当浏览器遇到外部CSS文件(通过
标签)或内部样式(通过