RWKV:在Transformer时代重新定义循环神经网络
论文地址:https://arxiv.org/abs/2305.13048
参考:https://www.zhihu.com/question/602564718/answer/3041307432
RWKV: Reinventing RNNs for the Transformer Era
RWKV:在Transformer时代重新定义循环神经网络
Abstract 摘要
Transformer已经彻底改变了几乎所有自然语言处理(NLP)任务,但其在序列长度上的内存和计算复杂度呈二次方增长。相比之下,循环神经网络(RNN)在内存和计算需求上呈线性扩展,但由于并行化和可扩展性的限制,难以达到Transformer相同的性能。我们提出了一种新颖的模型架构,即Receptance Weighted Key Value(RWKV),将Transformer的高效可并行训练与RNN的高效推理相结合。我们的方法利用了线性注意机制,并使得模型既可以作为Transformer,也可以作为RNN来构建,从而实现了在训练过程中的计算并行化,并在推理过程中保持恒定的计算和内存复杂度,这使得它成为第一个可以扩展到数百亿参数的非Transformer架构。我们的实验结果显示,RWKV的性能与大小相似的Transformer相当,这表明未来的工作可以利用这种架构创建更高效的模型。这项工作在平衡序列处理任务中的计算效率和模型性能之间的权衡方面迈出了重要的一步。
1 Introduction 前言
深度学习技术在人工智能领域取得了重大突破,在各种科学和工业应用中发挥了关键作用。这些应用通常涉及复杂的序列数据处理任务,包括自然语言理解、对话人工智能、时间序列分析,甚至可以被重新构建为序列的间接形式,如图像和图形(Brown等,2020年;Ismail Fawaz等,2019年;Wu等,2020年;Albalak等,2022年)。在这些技术中,循环神经网络(RNNs)、卷积神经网络(CNNs)和Transformer模型(Vaswani等,2017年)占据主导地位。
每种技术都有其独特的缺点,限制了它们在特定场景下的效率。RNNs在训练长序列时容易出现梯度消失问题,使得训练变得困难。此外,在训练过程中无法在时间维度上进行并行化,限制了其可扩展性(Hochreiter,1998年;Le和Zuidema,2016年)。另一方面,CNNs只擅长捕捉局部模式,这限制了它们处理长距离依赖关系的能力,而这对于许多序列处理任务非常重要(Bai等,2018年)。
Transformer模型由于其处理局部和长距离依赖关系的能力以及并行化训练的能力而成为一种强大的替代方案(Tay等,2022年)。最近的模型,如GPT-3(Brown等,2020年),ChatGPT(OpenAI,2022年;Kocon等,2023年),GPT-4(OpenAI,2023年),LLaMA(Touvron等,2023年)和Chinchilla(Hoffmann等,2022年),展示了这种架构的能力,推动了自然语言处理领域的前沿。尽管取得了这些重大进展,Transformer中固有的自注意机制也带来了独特的挑战,主要是由于其二次复杂度。这种复杂度使得架构在涉及长输入序列或资源受限情况下的任务中具有计算成本高和占用内存多的特点。这些限制已经激发了大量的研究,旨在改进Transformer的扩展性能,往往以牺牲其某些有效性为代价(Wang等,2020年;Zaheer等,2020年;Dao等,2022a年)。
为了解决这些挑战,我们引入了Receptance Weighted Key Value(RWKV)模型,这是一种新颖的架构,有效地结合了RNNs和Transformer的优势,同时规避了关键的缺点。RWKV经过精心设计,旨在缓解与Transformer相关的内存瓶颈和二次扩展问题(Katharopoulos等,2020年),以更高效的线性扩展来取而代之,同时仍保留了使Transformer成为该领域主导架构的丰富和表达性质。
RWKV的一个显著特点是其能够提供类似Transformer的并行化训练和强大的可扩展性。此外,我们重新构思了RWKV中的注意机制,引入了一种线性注意的变体,放弃了传统的点积令牌交互方式,而选择更有效的通道导向注意。这种方法与传统的Transformer架构有很大的不同,传统的架构中特定的令牌交互主导了注意力。在RWKV中,线性注意的实现没有进行近似,这在效率上带来了明显的改进,并增强了可扩展性,详见表1。
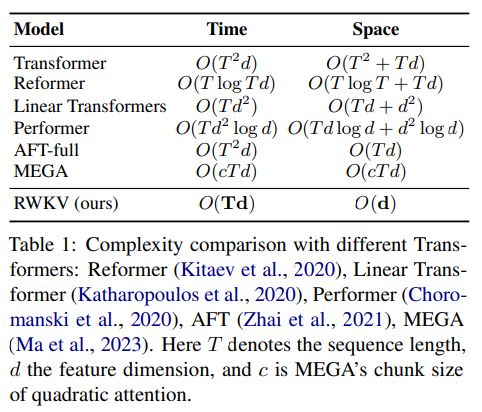
表 1: 与不同Transformer的复杂度比较:Reformer(Kitaev等,2020)、Linear Transformer(Katharopoulos等,2020)、Performer(Choromanski等,2020)、AFT(Zhai等,2021)、MEGA(Ma等,2023)。这里T表示序列长度,d表示特征维度,c表示MEGA的二次注意力的块大小。
开发RWKV的主要动机是弥合神经网络架构中计算效率和表达能力之间的差距。它为处理涉及数十亿参数的大规模模型的任务提供了一种有前景且可行的解决方案,以较低的计算成本展现出竞争性能。我们的实验结果表明,RWKV可以成为解决跨各个领域的AI模型扩展和部署中持续存在的挑战的有价值工具,特别是涉及序列数据处理的任务。因此,RWKV为下一代更可持续和计算效率更高的序列处理任务的AI模型铺平了道路。
本文的贡献如下:
- 我们引入了RWKV网络架构,结合了RNNs和Transformer的优点,同时缓解了它们已知的限制。
- 我们提出了一种新的注意机制改进,得到了线性注意,避免了标准Transformer模型所带来的二次复杂度。
- 我们在基准数据集上进行了一系列全面的实验,展示了RWKV在处理涉及大规模模型和长距离依赖关系的任务时的性能、效率和扩展能力。
- 我们发布了在Pile数据集(Gao等,2020年)上训练的预训练模型,参数规模从1.69亿到140亿不等。
2 Related Work相关工作
最近,已经提出了许多技术来解决Transformer的局限性。
2.1 Optimizing Attention Mechanism 优化注意机制
为了降低Transformer的复杂性,引入了许多变体(“x-formers”)(Tay等,2022年),包括稀疏注意力(Beltagy等,2020年;Kitaev等,2020年;Guo等,2022年)、近似全注意力矩阵(Wang等,2020年;Ma等,2021年;Choromanski等,2020年)、将分块注意力与门控相结合(Ma等,2023年)以及其他高效方法(Katharopoulos等,2020年;Jaegle等,2021年)。
一些最近的工作,如FlashAttention(Dao等,2022a年)和其他工作(Rabe和Staats,2022年;Jang等,2019年),与RWKV的分块计算方案类似。尽管它们在内存效率方面表现出色,但其时间复杂度仍然是二次的,或者包含分块大小作为一个隐含因子。相比之下,RWKV通过将线性注意力构建为一个RNN,在推理过程中实现了更好的空间和时间复杂度。
2.2 Attention Free Models 无注意力模型
另一条研究线路是用其他模块替代注意力机制以处理长序列。MLP-Mixer和其他模型(Tolstikhin等,2021年;Liu等,2021年)在计算机视觉任务中提出了用多层感知机(MLPs)替代注意力的方法。Attention Free Transformer(AFT)(Zhai等,2021年)用一个计算效率高的替代方案取代了点积自注意力,可以看作是每个特征维度对应一个头的多头注意力。受到AFT的启发,RWKV采取了类似的方法,但通过修改交互权重以实现RNN的形式来简化。与此同时,递归组件也被修改以增加上下文长度,例如Recurrent Memory Transformer(Bulatov等,2022年;2023年)和线性循环单元(Orvieto等,2023年)。还提出了像S4(Gu等,2022年)及其变体(Dao等,2022b年;Poli等,2023年)这样的状态空间模型(SSM)。
值得注意的是,准循环神经网络(QRNN)(Bradbury等,2017年)在时间步和通道之间使用卷积层和循环汇聚函数。虽然QRNN使用具有固定大小的卷积滤波器,但RWKV使用时间混合模块作为具有时间衰减因子的注意力机制。与QRNN中的逐元素汇聚不同,RWKV包括一个参数化的通道混合模块(见图1c中的绿色块),可以并行化处理。
以上是对相关工作的概述。下一部分将详细介绍背景知识,包括循环神经网络(RNNs)和Transformer及AFT模型的基本原理。
3 Background 背景
在这一部分,我们简要回顾了循环神经网络(RNNs)和Transformer的基础知识。
3.1 循环神经网络(RNNs)
流行的RNN架构,如LSTM(Hochreiter和Schmidhuber,1997年)和GRU(Chung等,2014年),具有以下形式(以LSTM为例,其他类似推导):

RNN的数据流程如Figure 1 (a)所示。尽管RNN可以分解为两个线性块(W和U)和一个特定于RNN的块(1)-(6),正如Bradbury等人(2017年)所指出的那样,依赖于先前时间步的数据依赖关系禁止对这些典型RNN进行并行化。

图1:RWKV与QRNN和RNN(Vanilla,LSTM,GRU等)架构的计算结构比较。颜色编码:橙色表示时间混合、卷积或矩阵乘法,连续的块表示这些计算可以同时进行;蓝色表示在通道或特征维度上同时进行的无参数函数(逐元素)。绿色表示通道混合。
3.2 Transformer和AFT
Transformer是由Vaswani等人(2017年)引入的一类神经网络,已成为多个NLP任务中的主导架构。与RNN逐步操作序列不同,Transformer依靠注意机制捕捉所有输入和输出令牌之间的关系:
![]()
这里为方便起见省略了多头性和缩放因子 1/√dk 。作为核心的 QK^T 乘积是序列中每个token之间的pairwise attention scores的集合,可以分解为向量操作:

在AFT(Zhai等,2021年)的论文中,这个公式可以替换为:

其中 {w_{t,i}} ∈ R^{T×T} 是学习到的逐对位置偏置,每个 w_{t,i} 是一个标量。
受到AFT的启发,我们让RWKV中的每个 w_{t,i} 成为一个channel-wise的时间衰减向量,与从当前时间追溯并衰减的相对位置相乘:

这里 w ∈ (R≥0)^d ,其中 d 是通道数。我们要求 w 是非负的,以确保 e^{w_{t,i}} ≤ 1 ,并且每个通道的权重向后衰减。
4 The Receptance Weighted Key Value (RWKV) Model
RWKV架构的命名源自时间混合和通道混合块中使用的四个主要模型元素:
- R:作为过去信息的接受程度的接受向量。
- W:位置权重衰减向量。可训练的模型参数。
- K:键向量,类似于传统注意力机制中的K。
- V:值向量,类似于传统注意力机制中的V。
每个时间步的主要元素之间的交互是乘法形式的,如Figure 2所示。

图2:RWKV模块元素(左)和用于语言建模的RWKV残差块及最终头部(右)架构。
4.1 High-Level Summary 高级摘要
RWKV架构由一系列堆叠的残差块组成,每个残差块由时间混合子块和通道混合子块组成,具有循环结构。
循环性质既可以被表达为当前输入和上一个时间步的输入之间的线性插值(我们将其称为时间偏移混合或令牌偏移,如Figure 3中的对角线所示),对于每个输入嵌入的线性投影(例如,时间混合中的R、K、V以及通道混合中的R、K)可以单独调整,也可以表达为WKV的时间相关更新,其在方程式14中进行了形式化。WKV的计算类似于AFT(Zhai等,2021年),但是W现在是一个通道级向量乘以相对位置,而不是AFT中的pairwise矩阵。我们还引入了向量 U ,用于独立地关注当前令牌,以补偿W的潜在退化(更多详细信息请参见附录G)。

Time Mix块表示如下:

其中 WKV计算, wkv_{t},在不引入二次复杂度的情况下,扮演了Transformer中 Attn(Q, K, V) 的角色,因为交互是在标量之间进行的。直观地说,随着时间 t 的增加,向量 o_t依赖于一个长的历史,由逐渐增加的项之和表示。对于目标位置 t ,RWKV在位置间隔 [1, t]内进行加权求和,然后乘以接受度 σ®。因此,在给定时间步内,交互是在不同时间步上进行乘法操作并进行求和。

我们采用了平方ReLU激活函数(So等,2021年)。需要注意的是,在时间混合和通道混合中,通过对接受度进行sigmoid操作,我们直观地将其作为“遗忘门”,以消除不必要的历史信息。
4.2 Transformer-like Parallelization 类Transformer的并行化
RWKV可以以我们称之为“时间并行模式”的方式高效地并行化,类似于Transformer。在单个层中处理一批序列的时间复杂度为 O(BTd^2)) ,主要由矩阵乘法W,其中 W ∈ {r, k, v, o} (假设有 B 个序列,T个最大令牌和 d个通道)组成。同时,更新注意力得分 wkv_t需要进行串行扫描(详见附录B),复杂度为 O(BTd) 。
矩阵乘法可以像传统Transformer中的W,其中 W ∈ {Q, K, V, O} 一样进行并行化。逐元素的 WKV计算是时间相关的,但可以沿着其他两个维度轻松并行化(Lei等,2018年)。如果序列非常长,则可以使用更复杂的方法,如Martin和Cundy(2017年),可以在序列长度上进行并行化。
此外,通过使用PyTorch(Paszke等,2019年)库中的nn.ZeroPad2d((0,0,1,-1)),我们将标记的偏移实现为每个块在时间维度上的简单偏移。
4.3 RNN-like Sequential Decoding 类似RNN的序列解码
在循环网络中,通常会将状态 tt的输出作为状态 t+1的输入。这在语言模型的自回归解码推理中尤为常见,要求在将每个标记输入到下一步之前计算它,这使得RWKV可以利用其类RNN的结构,称为时间顺序模式。在这种情况下,RWKV可以方便地在推理过程中以递归的方式进行解码,如附录B所示。该模式利用了每个输出标记仅依赖于最新状态的优势,而最新状态的大小是恒定的,与序列长度无关。
在这种模式下,RWKV的行为类似于RNN解码器,在序列长度方面,它具有恒定的速度和内存占用,从而更高效地处理更长的序列。相比之下,自注意力机制通常需要随着序列长度线性增长的键值缓存,导致效率降低,内存占用和时间消耗随着序列的增长而增加。
4.4 Software Implementation 程序实现
RWKV最初使用PyTorch深度学习库(Paszke等,2019)和用于WKV计算的自定义CUDA核心进行实现。虽然RWKV是一个通用的循环网络,但当前的实现重点是语言建模任务(RWKV-LM)。模型架构包括一个嵌入层,按照第4.7节中描述的设置进行配置,并且多个相同的残差块按顺序应用,如图2和图3所示,遵循第4.6节中概述的原则。在最后一个块之后,使用由LayerNorm(Ba等,2016)和线性投影组成的简单输出投影头来获取用于下一个标记预测任务的logits,并在训练过程中计算交叉熵损失。在后续的NLP任务中,生成在最后一个残差块后的嵌入和logits也可以被使用。训练是在时间并行模式(第4.2节)下进行的,而自回归推理和潜在的对话界面则利用了时间顺序模式(第4.3节)。
4.5 Gradient Stability and Layer Stacking 梯度稳定性和层叠情况
RWKV架构被设计为Transformer和RNN的融合,相比传统RNN,它具有Transformer的梯度稳定性和更深的架构的优势,同时在推理过程中高效。
先前的工作尝试通过多种技术来解决RNN中的梯度稳定性问题,包括使用非饱和激活函数(Chandar等,2019)、门控机制(Gu等,2019)、梯度裁剪(Pascanu等,2012)和添加约束条件(Kanai等,2017;Miller和Hardt,2018)。尽管这些技术的成功较少,但RWKV通过将softmax与RNN风格的更新相结合,从本质上避免了这个问题。
RWKV模型采用了单步更新注意力类似分数的过程,其中包括时间相关的softmax操作,有助于数值稳定性并防止梯度消失(详见附录F的严格证明)。直观地说,这个操作确保梯度沿着最相关的路径传播。层归一化(Ba等,2016)是架构的另一个关键方面,通过稳定梯度来增强深度神经网络的训练动力学,解决梯度消失和梯度爆炸的问题。
这些设计元素不仅有助于RWKV架构的稳定性和学习能力,还能够以超越任何现有RNN的方式堆叠多个层。通过这样做,模型能够在不同的抽象级别上捕捉到更复杂的模式(详见附录G)。
4.6 Harnessing Temporal Structure for Sequential Data Processing 利用时间结构进行序列数据处理
RWKV通过三种机制(循环、时间衰减和标记位移)的组合来捕捉和传播序列信息。
在RWKV的时间混合块中,recurrence是模型捕捉序列元素之间复杂关系并通过时间传播局部信息的基础。
time decay机制(方程式14中的 e^{-w} 和 e^u)保持对序列元素之间的位置关系的敏感性。通过逐渐减小过去信息对时间的影响,模型保留了时间局部性和进展的感知,这对于序列处理至关重要。这种对序列数据中位置信息的处理与Attention with Linear Biases (ALiBi)模型(Press等,2022)类似,其中线性偏差有助于输入长度的外推。在这个背景下,RWKV架构可以被看作是ALiBi的可训练版本,无需显式编码即可无缝地整合位置信息。它也可以被视为Zhai等人(2021)中引入的门控卷积对完整序列长度进行扩展的扩展。
token shift或time-shift mixing(图3中的对角箭头)也有助于模型适应序列数据。通过在当前输入和上一个时间步骤输入之间线性插值,模型自然地聚合和控制输入通道中的信息。时间位移混合的整体结构类似于WaveNet(van den Oord等,2016)中没有扩张的因果卷积,这是一种用于预测时间序列数据的经典架构。
4.7 Additional Optimizations 附加优化
Custom Kernels 自定义核心
为了解决使用标准深度学习框架时,由于任务的顺序性而导致WKV计算的低效问题,我们实现了一个自定义的CUDA核心,以便在训练加速器中启动单个计算核心。模型的所有其他部分都是矩阵乘法和逐元素操作,这些操作已经可以有效地并行化。
FFN with R gate 带有R门的FFN
先前的研究(Tolstikhin等,2021;Liu等,2021;Yu等,2022)表明,在基于Transformer的视觉任务中,自注意力可能并不像之前想象的那样重要。尽管自注意力为我们提供了一些见解,但在自然语言任务中完全替换自注意力可能过于激进。在我们的研究中,我们通过将固定的QKV公式替换为KV,并引入新的时间衰减因子W,部分解构了注意机制。这种方法使我们能够将类似于MLP-mixer(Tolstikhin等,2021)的标记和通道混合组件以及类似于gMLP(Liu等,2021)的门控单元R整合到我们的RWKV模型中,从而提升了性能。
Small Init Embedding 小初始嵌入
在训练Transformer模型(Vaswani等,2017)的初始阶段,我们观察到嵌入矩阵变化缓慢,这给模型摆脱初始噪声嵌入状态带来了挑战。为了缓解这个问题,我们提出了一种方法,即使用较小的值初始化嵌入矩阵,然后再应用额外的LayerNorm操作。通过实施这种技术,我们加速并稳定了训练过程,使得能够对具有后续LayerNorm组件的深层架构进行训练。该方法的有效性在图8中得到了证明,该图表明它能够通过使模型快速从初始小嵌入状态转变,从而促进了更好的收敛性。这是通过在单个步骤之后进行小的变化,进而在LayerNorm操作之后产生重大的方向改变和显著的变化来实现的。
Custom Initialization自定义初始化
在之前的研究基础上(He等,2016;Jumper等,2021),我们将参数初始化为尽可能接近标识映射的值,同时打破对称性,以确保清晰的信息传递路径。大多数权重初始化为零。线性层不使用偏置。具体的公式请参见附录D。我们发现初始化选择对收敛速度和质量具有重要影响(请参见附录E)。
5 Evaluations 评估
在本节中,我们将重点评估以回答以下问题:
- RQ1:在参数数量和训练标记数相等的情况下,RWKV是否与二次复杂度的Transformer架构相竞争?
- RQ2:当增加参数数量时,RWKV是否仍然与二次复杂度的Transformer架构相竞争?
- RQ3:当RWKV模型训练的上下文长度超过大多数开源的二次复杂度Transformer的有效处理范围时,增加RWKV的参数是否会产生更好的语言建模损失?
针对RQ1和RQ2,从图4中可以看出,在六个基准测试(Winogrande、PIQA、ARC-C、ARC-E、LAMBADA和SciQ)上,RWKV与主要的开源二次复杂度Transformer模型(Pythia、OPT和BLOOM)相比具有很强的竞争力(参见附录H中的详细信息)。在四个任务(PIQA、OBQA、ARC-E和COPA)中,RWKV甚至超过了Pythia和GPT-Neo。至于RQ3,图5显示增加上下文长度会导致在Pile数据集上的测试损失降低,这表明RWKV能够有效地利用长上下文信息。


6 Inference Experiments 推理实验
我们根据大小和类型进行推理需求的基准测试。具体而言,我们在典型的计算平台上,包括CPU(x86)和GPU(NVIDIA A100 80GB),评估文本生成速度和内存需求。在所有实验中,我们使用float32精度。参数计数包括嵌入层和非嵌入层的所有模型参数。不同量化设置下的性能留待进一步研究。更多结果请参见附录I。
此外,我们对RWKV-4、ChatGPT和GPT-4进行了比较研究,详见附录J。研究结果显示,RWKV-4对于提示工程非常敏感。当将提示从适用于GPT的提示调整为适用于RWKV的提示时,F1度量性能甚至从44.2%提高到74.8%。
7 Future Work 未来工作
对于RWKV架构,存在几个有前景的未来工作方向:
- 通过改进时间衰减公式和在保持效率的同时探索初始模型状态,提高模型表达能力。
- 通过在 wkv_t步骤中应用并行扫描,将计算成本降低到 O(B log(T)d),进一步提高RWKV的计算效率。
- 研究将RWKV应用于编码器-解码器架构,并潜在替代交叉注意机制。这对于seq2seq或多模态设置具有适用性,在训练和推理中提高效率。
- 利用RWKV的状态(或上下文)进行序列数据的可解释性、可预测性和安全性研究。通过操作隐藏状态,还可以指导行为并通过提示调整实现更大的可定制性。
- 在特定设置中探索微调模型,以增强与人类的交互(Ouyang等,2022)。特别有趣的是在不同数据集和特定用例下的性能表现。
- 采用LoRA(Hu等,2022)等参数高效的微调方法,并对所提出的架构在不同量化方案下的行为进行表征。
8 Conclusions 结论
我们引入了RWKV,一种利用基于时间的混合组件潜力的新型RNN模型方法。RWKV引入了几个关键策略,使其能够捕捉局部性和长程依赖关系,并通过以下方式解决了当前架构的局限性:
(1)将二次的QK注意力替换为具有线性成本的标量形式,
(2)重新构建递归和顺序归纳偏差,以解锁有效的训练并行化和高效推理,
(3)使用自定义初始化增强训练动力学。
我们在各种自然语言处理任务中对所提出的架构进行了基准测试,并展示了与SOTA相当的性能以及更低的成本。在表达能力、可解释性和扩展性方面的进一步实验展示了模型的能力,并在RWKV和其他LLM之间绘制了行为上的相似之处。
RWKV为在序列数据中建模复杂关系提供了一种可扩展和高效的架构。尽管已经提出了许多与Transformer类似的替代方案,声称具有类似的优势,但我们是第一个通过拥有数百亿参数的预训练模型来支持这些主张的。
9 Limitations 限制
虽然我们提出的RWKV模型在训练和推理过程中展现出了有希望的结果,具有较高的训练和内存效率,但在未来的工作中应该承认并解决一些限制。首先,RWKV的线性注意力虽然带来了显著的效率提升,但也可能限制了模型在需要在非常长的上下文中回忆细节信息的任务上的性能。这是因为相比标准Transformer的二次注意力所保持的全部信息,RWKV通过单个向量表示在许多时间步上进行信息传递。换句话说,相对于传统的自注意机制,模型的循环架构本质上限制了其“回望”之前标记的能力。虽然学习的时间衰减有助于防止信息丢失,但与完全的自注意力机制相比,它在机械上存在一定的限制。
本工作的另一个限制是与标准Transformer模型相比,提示工程的重要性增加了。RWKV中使用的线性注意机制限制了提示中将传递给模型继续处理的信息。因此,精心设计的提示可能对模型在任务上的表现更加关键。