牛客网刷题之SQL篇:非技术快速入门39T
导航
- 前序
- 一、简单的关键字练习 1-10
- 二、知识点复习之 ==运算符==
-
- 1、算数运算符
- 2、比较运算符
- 3、逻辑运算符
- 4、位运算符
- 三、10-28T
-
- 0、简单题总结
- 1. SQL18 ==分组计算==练习题
- 2. SQL19 ==分组过滤==练习题
- 3. SQL22 统计==每个学校==的答过题的==用户的平均答题数==
- 4. SQL23 统计每个学校各难度的用户平均刷题数
- 5、SQL24 统计每个用户的平均刷题数
- 6、SQL25 查找山东大学或者性别为男生的信息
- 7、SQL26 计算25岁以上和以下的用户数量
- 8、SQL27 查看不同年龄段的用户明细 ==case_when==
- 9、SQL28 计算用户==8月每天的练题数量==
- 四、知识点复习之==内外连接==
- 五、知识点复习之union
- 六、29-39T
-
- 1、***** SQL29 计算用户的平均次日留存率
- 2、SQL32 截取出年龄
- 3、SQL33 找出每个学校GPA最低的同学
- 4、SQL34 统计复旦用户8月练题情况
- 5、SQL35 浙大不同难度题目的正确率
前序
SQL 运算符 包括:算术运算符、比较运算符、逻辑运算符、位运算符、
- 牛客网刷题之SQL篇:非技术快速入门39T
一、简单的关键字练习 1-10
SQL3-查询结果去重:distinct 关键字
SQL4-查询结果限制返回行数:limit关键字
SQL5-将查询后的列重新命名:as 关键字 or 空格
SQL6-查找学校是北大的学生信息:where、limit
SQL7 查找年龄大于24岁的用户信息:比较运算符
SQL8 查找某个年龄段的用户信息:比较运算符
SQL10 用where过滤空值练习:is not
二、知识点复习之 运算符
1、算数运算符
| 中文 | 运算符 |
|---|---|
| 加 | + |
| 减 | - |
| 乘 | * |
| 除 | / |
| 求余 | % |
2、比较运算符
| 运算符 | 作用 | mybatis语法 |
|---|---|---|
| = | 等于,相等返回值为1,否则返回值为0,1个或2个null返回null,string与int比较则string自动转int | |
| <=> | 安全等于,与=的区别是,两个同时为null时返回1,当一个为null,返回值为0 | |
| <>(!=) | 不等于,相等返回值为0,不相等返回值为1 | |
| <= | 小于等于,如果小于等于则返回值为1,否则返回值为0 | <= |
| >= | 大于等于,如果大于等于则返回值为1,否则返回值为0 | >= |
| > | 大于 ,如果大于则返回值为1,否则返回值为0 | > |
| < | 小于 ,如果小于则返回值为1,否则返回值为0 | < |
| is null | 判断是否为null,如果是null,则返回值为1,否则返回值为0 | |
| is not null | 判断是否不为null | |
| least | 在有两个或多个参数返回最小值 | |
| greatest | 在有两个或多个参数返回最大值 | |
| between and | 判断一个值是否落在两个值之间 | |
| in | 判断一个值在不在列表里 | |
| not in | 判断一个值不是在列表里 | |
| like | 通配符匹配,’ % ‘匹配任何数目的字符,’ _ ’ 匹配一个字符 | |
| regexp | 正则表达式匹配,如果满足则返回1 '^ '匹配以该字符后面的字符开头的字符 ’ $ ‘匹配以该字符后面的字符结尾的字符 ’ . ‘匹配任何一个字符 ’ [0-9 a-z] ’ 匹配0-9 a-z’ * '匹配任何一个字符 |
3、逻辑运算符
所有逻辑运算符的求值结果均为TRUE(1) FALSE()0 NULL
| 运算符 | 作用 |
|---|---|
| not( ! ) | 非 |
| and( && ) | 与 |
| or ( || ) | 或 |
| xor | 异或 |
4、位运算符
位运算符是在二进制数上进行计算的运算符,位运算符会先将操作数变成二进制数,然后进行位运算,最后将计算结果从二进制变回十进制数

| 运算符 | 作用 |
|---|---|
| | | 位或 |
| & | 位与 |
| ^ | 位异或 |
| << | 位左移 |
| >> | 位右移 |
| ~ | 位取反,反转所有比特 |
三、10-28T
0、简单题总结
SQL14 操作符混合运用:and 和 or 的用法
SQL15 查看学校名称中含北京的用户:like
SQL16 查找GPA最高值:计算函数 max()
SQL17 计算男生人数以及平均GPA:计算函数 count()、avg()
SQL20 分组排序练习题:group、order、avg()
SQL21 浙江大学用户题目回答情况:left join
1. SQL18 分组计算练习题
现在运营想要对每个学校不同性别的用户活跃情况和发帖数量进行分析,请分别计算出每个学校每种性别的用户数、30天内平均活跃天数和平均发帖数量。
题目链接
##请分别计算出每个学校每种性别的用户数、30天内平均活跃天数和平均发帖数量。
select
gender,
university,
count(id) as user_num,
avg(active_days_within_30) as avg_active_day,
avg(question_cnt) as avg_question_cnt
from user_profile
group by university,gender
2. SQL19 分组过滤练习题
题目:现在运营想查看每个学校用户的平均发贴和回帖情况,寻找低活跃度学校进行重点运营,请取出平均发贴数低于5的学校或平均回帖数小于20的学校。
题目链接
select
university,
avg(question_cnt) as avg_question_cnt,
avg(answer_cnt) as avg_answer_cnt
from user_profile
group by university
having avg_question_cnt < 5 or avg_answer_cnt <20
3. SQL22 统计每个学校的答过题的用户的平均答题数
运营想要了解每个学校答过题的用户平均答题数量情况,请你取出数据。
题目链接
重点:
每个学校:group by university
用户的平均答题数:count(b.result) / count(distinct b.device_id)
使用left join 还是inner join
select
a.university,
count(b.result) / count(distinct b.device_id) as avg_answer_cnt
from user_profile a
inner join question_practice_detail b on a.device_id = b.device_id
group by a.university
order by a.university
4. SQL23 统计每个学校各难度的用户平均刷题数
题目:运营想要计算一些参加了答题的不同学校、不同难度的用户平均答题量,请你写SQL取出相应数据
select
university,
difficult_level,
count(b.result) / count(distinct b.device_id) as avg_answer_cnt # 用户平均答题量
from user_profile a
inner join question_practice_detail b on a.device_id = b.device_id
inner join question_detail c on b.question_id = c.question_id
group by university, difficult_level
5、SQL24 统计每个用户的平均刷题数
题目:运营想要查看参加了答题的山东大学的用户在不同难度下的平均答题题目数,请取出相应数据
select
university,
difficult_level,
count(result) / count(distinct b.device_id) as avg_answer_cnt
from user_profile a
left join question_practice_detail b on a.device_id = b.device_id
left join question_detail c on b.question_id = c.question_id
where university = '山东大学'
group by difficult_level
6、SQL25 查找山东大学或者性别为男生的信息
题目:现在运营想要分别查看学校为山东大学或者性别为男性的用户的device_id、gender、age和gpa数据,请取出相应结果,结果不去重。
select
device_id,
gender,
age,
gpa
from user_profile
where university = '山东大学'
union all
select
device_id,
gender,
age,
gpa
from user_profile
where gender = 'male'
7、SQL26 计算25岁以上和以下的用户数量
题目:现在运营想要将用户划分为25岁以下和25岁及以上两个年龄段,分别查看这两个年龄段用户数量
本题注意:age为null 也记为 25岁以下
select
case when age>=25 then '25岁及以上' else '25岁以下' end as age_cut,
count(device_id) as number
from user_profile
group by age_cut
8、SQL27 查看不同年龄段的用户明细 case_when
题目:现在运营想要将用户划分为20岁以下,20-24岁,25岁及以上三个年龄段,分别查看不同年龄段用户的明细情况,请取出相应数据。(注:若年龄为空请返回其他。)
select
device_id,
gender,
case when age < 20 then "20岁以下"
when age >=20 and age <= 24 then "20-24岁"
when age >=25 then "25岁及以上"
else "其他" end as age_cut
from user_profile
9、SQL28 计算用户8月每天的练题数量
题目:现在运营想要计算出2021年8月每天用户练习题目的数量,请取出相应数据。
select
day(date) as day,
count(question_id) as question_cnt
from question_practice_detail
where month(date)=8 and year(date)=2021
group by day
## 这里 group by date 也可以
--法一:like运算符
select
day(date) as day,
count(question_id) as question_cnt
from question_practice_detail
where date like '2021-08%'
group by day(date);
--法二:regexp运算符
select
day(date) as day,
count(question_id) as question_cnt
from question_practice_detail
where date regexp '2021-08'
group by day(date);
--法三:substring提取日期
select
day(date) as day,
count(question_id) as question_cnt
from question_practice_detail
where substring(date,1,7) = '2021-08'
group by day(date);
函数:
year('2022-12-22') = ‘2022’
month('2022-12-22') = ‘12’
day('2022-12-22') = ‘22’
四、知识点复习之内外连接
五、知识点复习之union
六、29-39T
- SQL29 计算用户的平均次日留存率: *****
- SQL30 统计每种性别的人数:
substring_index() 字符串函数 - SQL31 提取博客URL中的用户名:
substring_index() 字符串函数 - SQL32 截取出年龄:
substring_index() 字符串函数 - SQL33 找出每个学校GPA最低的同学
- SQL35 浙大不同难度题目的正确率:*****
- SQL36 查找后排序:easy
order by - SQL37 查找后多列排序:同上
- SQL38 查找后降序排列:
默认 asc、desc
10.SQL39 21年8月份练题总数:year(date) = 2021 and month(date) = 8
1、***** SQL29 计算用户的平均次日留存率
描述
题目:现在运营想要查看用户在某天刷题后第二天还会再来刷题的平均概率。请你取出相应数据。
question_practice_detail
| id | device_id | quest_id | result | date |
|---|---|---|---|---|
| 1 | 2138 | 111 | wrong | 2021-05-03 |
| 2 | 3214 | 112 | wrong | 2021-05-09 |
| 3 | 3214 | 113 | wrong | 2021-06-15 |
| 4 | 6543 | 111 | right | 2021-08-13 |
| 5 | 2315 | 115 | right | 2021-08-13 |
| 6 | 2315 | 116 | right | 2021-08-14 |
| 7 | 2315 | 117 | wrong | 2021-08-15 |
根据示例,你的查询应返回以下结果:
| avg_ret |
|---|
| 0.3000 |
select
count(date2) / count(date1) as avg_ret
from (
select
distinct a.device_id,
a.date as date1,
b.date as date2
from question_practice_detail as a
left join (
select distinct device_id, date
from question_practice_detail
) as b
on a.device_id = b.device_id
and date_add(a.date, interval 1 day) = b.date
) as c
##解法2
select avg(if(datediff(date2, date1)=1, 1, 0)) as avg_ret
from (
select
distinct device_id,
date as date1,
lead(date) over (partition by device_id order by date) as date2
from (
select distinct device_id, date
from question_practice_detail
) as uniq_id_date
) as id_last_next_date
问题分解:
- 限定条件:第二天再来。
- 解法1:表里的数据可以看作是全部第一天来刷题了的,那么我们需要构造出第二天来了的字段,因此可以考虑用left join把第二天来了的拼起来,限定第二天来了的可以用date_add(date1, interval 1 day)=date2筛选,并用device_id限定是同一个用户。
- 解法2:用lead函数将同一用户连续两天的记录拼接起来。先按用户分组partition by device_id,再按日期升序排序order by date,再两两拼接(最后一个默认和null拼接),即lead(date) over (partition by device_id order by date)
- 平均概率:
- 解法1:可以count(date1)得到左表全部的date记录数作为分母,count(date2)得到右表关联上了的date记录数作为分子,相除即可得到平均概率
- 解法2:检查date2和date1的日期差是不是为1,是则为1(次日留存了),否则为0(次日未留存),取avg即可得平均概率。
附:lead用法,date_add用法, datediff用法, date函数
细节问题:
- 表头重命名:as
- 去重:需要按照devece_id,date去重,因为一个人一天可能来多次
- 子查询必须全部有重命名
2、SQL32 截取出年龄
1、LOCATE(substr , str ):返回子串 substr 在字符串 str 中第一次出现的位置,如果字符substr在字符串str中不存在,则返回0;
2、POSITION(substr IN str ):返回子串 substr 在字符串 str 中第一次出现的位置,如果字符substr在字符串str中不存在,与LOCATE函数作用相同;
3、LEFT(str, length):从左边开始截取str,length是截取的长度;
4、RIGHT(str, length):从右边开始截取str,length是截取的长度;
5、SUBSTRING_INDEX(str ,substr ,n):返回字符substr在str中第n次出现位置之前的字符串; substring_index用法
例子:
str=www.wikibt.com
substring_index(str,'.',1)
结果是:www
substring_index(str,'.',2)
结果是:www.wikibt
如果count是`正数`,那么就是从左往右数,第N个分隔符的左边的所有内容
如果count是`负数`,那么就是从右往左数,第N个分隔符的右边的所有内容
6、SUBSTRING(str ,n ,m):返回字符串str从第n个字符截取到第m个字符;
7、REPLACE(str, n, m):将字符串str中的n字符替换成m字符;
8、LENGTH(str):计算字符串str的长度。
3、SQL33 找出每个学校GPA最低的同学
注意 : inner join. 和 right join 可以,left就不行
select
a.device_id,
a.university,
a.gpa
from user_profile a
inner join
(
select university, min(gpa) as gpa
from user_profile
group by university
) as b
on a.university=b.university and a.gpa=b.gpa
order by a.university
4、SQL34 统计复旦用户8月练题情况
描述
题目: 现在运营想要了解复旦大学的每个用户在8月份练习的总题目数和回答正确的题目数情况,请取出相应明细数据,对于在8月份没有练习过的用户,答题数结果返回0.
示例:用户信息表user_profile

示例:question_practice_detail

根据示例,你的查询应返回以下结果:
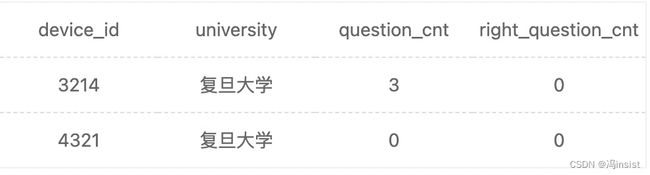
select
a.device_id,
'复旦大学' as university,
count(question_id) as question_cnt,
sum(if(b.result = 'right', 1, 0)) as right_question_cnt
from user_profile a
left join question_practice_detail b on a.device_id = b.device_id and month(date) = 8 ## 注意,month(date) = 8 只能放在这儿
where university = '复旦大学'
group by a.device_id
5、SQL35 浙大不同难度题目的正确率
题目链接
描述
题目:现在运营想要了解浙江大学的用户在不同难度题目下答题的正确率情况,请取出相应数据,并按照准确率升序输出。
示例: user_profile
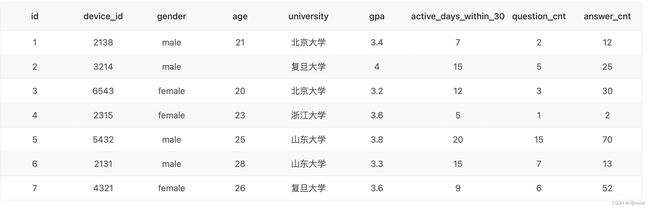
示例: question_practice_detail

示例: question_detail

根据示例,你的查询应返回以下结果:
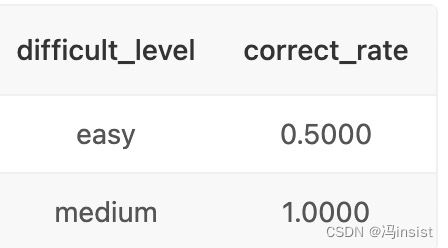
select
difficult_level,
sum(if(b.result = 'right', 1, 0)) / count(result) as correct_rate
from user_profile a
inner join question_practice_detail b on a.device_id = b.device_id
inner join question_detail c on b.question_id = c.question_id
where university = '浙江大学'
group by difficult_level
order by correct_rate asc