简单的实战演练:维基百科爬虫(附带爬虫样例代码)
written by: 东篱下の悠然
此项目基于python语言实现,需要一定的python编程基础~
1. 什么是网页爬虫:
当我们在浏览维基百科或百度网页时,在浏览过程中可以单击文章中的链接从某一页到另一网页,重复几次会发现所浏览的内容越来越离奇,与我们需要查找的资源越来越不相干而容易使人分心。比如我在维基百科中文版主页上搜索“煎饼果子”关键字时,正文中第一个链接是“煎饼”,点击它会转到“煎饼”词条的百科页面。而弹出的新页面中找到第一个链接是“中国”,点击中国。转到的新页面中,第一个链接是“东亚”,点击东亚。转到新页面,找到第一个链接是"亚洲"。。。。可以这样一直持续很长时间,但这时呈现的资源与我们一开始要查找的“煎饼果子”已经没有任何关系了。现在试一试转到自己感兴趣的维基百科页面,或者一个随机页面维基百科英文版主页,单击第一个链接。然后在该页面单击文章主体上的第一个链接,然后继续。可以多次尝试不同的页面,看看能否出现相同内容。
使用维基百科时,有时单击和阅读所有文章需要很多时间。 爬虫将致力于使这一过程实现自动化,借助于一个为我们查阅维基百科的程序,跟踪每个页面上的第一个链接,以及看到这些链接的导向位置。
2. 了解一点点网页搭建基础:
为了实现维基百科Crawl自动化,我们需要了解网络页面的工作原理和我们可以用于与网络和网络内容交互的一些 Python 工具。
网络爬虫是一个与网站进行交互的程序。网络爬虫用于创建搜索引擎索引和归档页面,现在的例子中用于探索维基百科。编写爬虫前,我们需要先了解网页的工作原理。特别是,需要了解一些 HTML。不需要太多,简单了解就好:
HTML 或超文本标记语言是网页的源代码。HTML 文档是描述页面内容的文本文档。其包括文本内容、页面上图像和视频的 URL 以及关于内容排列和样式的信息。网页浏览器会收到原始 HTML,并相应提供格式整齐的多媒体网页。
这是一个简单页面的源码,了解一下如何构建 HTML网页:
My Website
"introduction">
欢迎来到我的小站!
"image-gallery">
This is my cat!
 "cat.jpg" alt="Meow!">
"https://en.wikipedia.org/wiki/Cat">了解猫猫的更多知识
"cat.jpg" alt="Meow!">
"https://en.wikipedia.org/wiki/Cat">了解猫猫的更多知识
这块代码就可以组成一个完整而又简单的网页,解析后的效果为:打开后显示一行欢迎字样,换行,显示“This is my cat!”,后面跟一个小猫的图片,接下来就是一个超链接,点击会转到地址为“https://en.wikipedia.org/wiki/Cat”的新的页面中去。
HTML 源代码由嵌套标签组织而成,这很重要。第一个标签是标题标签,< title >和结束标签< /title >之间的文本用作页面标题。p 是 “段落” 的缩写。< p > 和其结束标签 < /p > 之间的文本是提供 HTML 时,显示在屏幕上的内容。可以将该段落称为 div 标签(嵌套在其中)的 “子类”。同样,div 是段落的 “父类”。总而言之,这种父类标签和子类标签的排列创建了一个树结构。
如需爬取网页,还需要了解一个标签类型,即锚标签。我们已经看到一个锚标签:
"https://en.wikipedia.org/wiki/Cat">一起学猫叫
锚标签(用< a >< /a >表示),用于创建链接。此示例创建了这样一个链接,效果如下:点击一下试试吧~
一起学猫叫
在 href 属性中指定链接目的,开始和结束标签之间的文本“一起学猫叫”即链接的文本。
在真实的网页中,要查看源码的可以按ctrl + u快捷键,即可在一个新页面中查看该网页的源码。密密麻麻没有缩进,不像python那样整洁。因为HTML语言不需要像python那样用缩进组织代码块。
在维基百科中文版主页上按ctrl + u后产生的界面:

往下拉会发现一些刚刚介绍过的标签,< title >和结束标签< /title >,< p > 和其结束标签 < /p >,href 等等
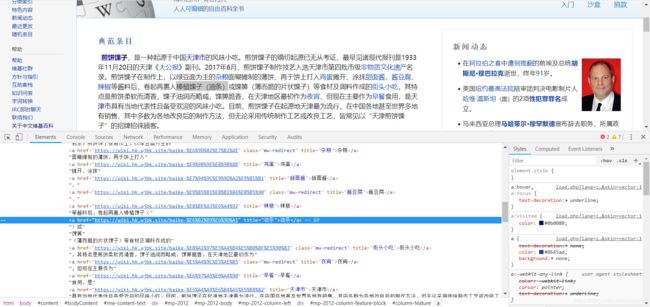
要在源码中找到你要Crawl的链接,先回到前端网页,选中要操作的链接所在的文字,右击->审查元素(ctrl + shift + I)在弹出的开发者工具中就可以看到选中链接的URL,右侧可以看到很多小的三角形来显示链接所在标签的层次结构(即上面说的树状结构)。正因为每张网页都属于这种结构,就可以用这些标签信息做网页抓取工具~
展示一下如何在开发者工具中找到选中文字的url,其实只有“油条”两个字带着超链接,为了更明显就扩选了一下下~
3. 用Python获取HTML网页:(Python3及以上)
懒人同学的python下载链接*-*
运行python,因为request不是python标准库的一部分,所以首先安装具有pip的request包。安装很简单,直接输入:
$ pip3 install requests
回车,即可完成request安装。
查看网页的HTML源码可以通过打印输出response中的text获取:
>>> response = requests.get('https://en.wikipedia.org/wiki/Dead_Parrot_sketch')
>>> print(response.text)
>>> print(type(response.text))
回车,即可看到get后链接里的HTML代码。没错,就是刚刚按 ctrl + u后看到的,带有< title > < /title >,< p > < /p >的网页源码~
这里还输出了一下response.text的类型,在所有输出结果的最末尾应该有一行是< class ‘str’ >,表明response.text只是包含该维基页面的HTML信息的字符串。
有了HTML源代码,接下来了解一下如何解析出 HTML代码中各种标签。由于 HTML 只是字符串文本,我们可以使用已经了解的工具对其进行解析:循环和字符串方法。但HTML 是一种非常灵活的语言,很难正确解析。此前的程序员已经解决了这个问题,我们只需要安装一个名字叫 Beautiful Soup的库即可在一大堆HTML中提取你想要的标签所在的行,根据库说明文档(附Beautiful Soup的英文文档和中文文档),安装只需要输入:
$ pip3 install beautifulsoup4
回车,即可安装完成安装。
PS: 当接触一个新库时,可以对照文档说明在交互式shell上尝试它的各种命令,达到快速熟悉这个库的使用目的。
引用伪代码描述查找链接的实现步骤:
页面 = 一个随机起始页
article_chain = [] #用一个列表存放找到的URL
而页面标题不是“我想要的链接”,而且我们还没有发现循环:
将页面添加到 article_chain
下载页面内容
在内容中查找第一个链接
页面=该链接
暂停片刻
那最后一步为什么要暂停片刻呢??是因为≖‿≖✧
Python程序不像人一样一边浏览一边向服务器获取资源,程序循环速度将与页面下载速度一样快。虽然节省时间,但是用快速重复的请求敲击网络服务器显得无礼粗鲁。如果不减慢循环速度,服务器可能会认为我们是试图超载服务器的攻击者而阻止我们。服务器可能是对的!如果代码中有一个错误,我们可能会进入一个无限循环,并且大量的资源请求将淹没服务器。为了避免此种情况,我们应该在主循环中故意暂停几秒显得友好一点。
现在展示的程序是一个名叫continue_crawl的函数,功能是辨别在各种不同情况下,程序会停止请求维基页面:
def continue_crawl(search_history, target_url, max_steps=25):
if search_history[-1] == target_url:
print("We've found the target article!")
return False
elif len(search_history) > max_steps:
print("The search has gone on suspiciously long, aborting search!")
return False
elif search_history[-1] in search_history[:-1]:
print("We've arrived at an article we've already seen, aborting search!")
return False
else:
return True
continue_crawl函数完成了。接下来用while循环来控制上方的代码是否执行(因为不知道具体执行次数所以不能用for循环),while中包括:一,在 article_chain 中下载最后一篇文章的 html网页(用请求包就可以从维基百科获取 html 的命令)。二,查找该 html 中的第一个链接,用 BeautifulSoup方法解析该 html网页,即可获取第一个链接的 URL。三,将下一篇文章的第一个链接赋给article_chain。四,暂停片刻。
将一和二两个功能封装在一个函数中,函数名叫find_first_link,传入一个字符串调用该函数找到有用的第一个链接,并将这个链接返回并加入到article_chain列表中:
为了能使程序找到正文中有效的链接(比如脚注链接,发音指南链接,点一下只会教你怎么发音一个字符;帮助链接,这些都可以是链接,但这不是我们想要的。我们只要找可以连接到普通维基百科文章的链接),在下方总结了需要在python程序中用到的方法:
- 导入需要的库:
import requests回车;from bs4 import BeautifulSoup回车 - 寻找id标签:find_all方法或children方法均可
- get方法可以去除a herf上的其它参数而只保留url,用herf作为get方法中查询的键值(在文档中可查阅)
find_all方法实现根据id找html标签:
content_div = soup.find(id="mw-content-text").find(class_="mw-parser-output")
for element in content_div.find_all("p", recursive=False):
if element.a:
first_relative_link = element.a.get('href')
break
第一行代码查找到包含文章正文的 div标签。 如果该标签是 div 的子类,则下一行在 div 中循环每个p标签。从文档了解到“如果想让 Beautiful Soup 只考虑div的直接子类,可以按照recursive=False进行传递”。循环主体可以查看段落中是否存在 a 标签。如果成立,就从链接中获取 url,并将其存储在 first_relative_link 中并结束循环。
find方法中的recursive = False 选项用来过滤无效链接:
content_div = soup.find(id="mw-content-text").find(class_="mw-parser-output")
for element in content_div.find_all("p", recursive=False):
if element.find("a", recursive=False):
first_relative_link = element.find("a", recursive=False).get('href')
break
综上所述,展示完整的find_first_link函数:
def find_first_link(url):
response = requests.get(url)
html = response.text
soup = bs4.BeautifulSoup(html, "html.parser")
# 这个div标签包含了网页的主体部分,因为我们要找的链接都出自文章正文部分,直接在正文中开始查找
content_div = soup.find(id="mw-content-text").find(class_="mw-parser-output")
# 在存储项目中找到的第一个链接,若项目不包含链接,就将此值保持为空
article_link = None
# 查找div标签的所有的直接子段落
for element in content_div.find_all("p", recursive=False):
# 查找链接,并判断是不是我们需要的有效链接,若不是,则查找下一个链接并判断
if element.find("a", recursive=False):
article_link = element.find("a", recursive=False).get('href')
break
if not article_link:
return
# 从查找出的链接中生成完整的url,并赋给first_link,由它带回并输出
first_link = urllib.parse.urljoin('https://en.wikipedia.org/', article_link)
return first_link
因为维基百科的链接是相对url,这里需要返回一个 直接可用的绝对url,直接引用urllib.parse.urljoin方法即可转换成绝对url并输出。如果感兴趣啥是“相对/绝对url”请自行百度,这不是重点,注意下这个细节即可~
4. 完整的维基百科爬虫代码:
WikipediaCrawler.py
import time
import urllib
import bs4
import requests
start_url = "https://en.wikipedia.org/wiki/Special:Random"
target_url = "https://en.wikipedia.org/wiki/Philosophy"
def find_first_link(url):
response = requests.get(url)
html = response.text
soup = bs4.BeautifulSoup(html, "html.parser")
# 这个div标签包含了网页的主体部分,因为我们要找的链接都出自文章正文部分,直接在正文中开始查找
content_div = soup.find(id="mw-content-text").find(class_="mw-parser-output")
# 在存储项目中找到的第一个链接,若项目不包含链接,就将此值保持为空
article_link = None
# 查找div标签的所有的直接子段落
for element in content_div.find_all("p", recursive=False):
# 查找链接,并判断是不是我们需要的有效链接,若不是,则查找下一个链接并判断
if element.find("a", recursive=False):
article_link = element.find("a", recursive=False).get('href')
break
if not article_link:
return
# 从查找出的链接中生成完整的url,并赋给first_link,由它带回并输出
first_link = urllib.parse.urljoin('https://en.wikipedia.org/', article_link)
return first_link
def continue_crawl(search_history, target_url, max_steps=25):
if search_history[-1] == target_url:
print("We've found the target article!")
return False
elif len(search_history) > max_steps:
print("The search has gone on suspiciously long, aborting search!")
return False
elif search_history[-1] in search_history[:-1]:
print("We've arrived at an article we've already seen, aborting search!")
return False
else:
return True
article_chain = [start_url]
while continue_crawl(article_chain, target_url):
print(article_chain[-1])
first_link = find_first_link(article_chain[-1])
if not first_link:
print("We've arrived at an article with no links, aborting search!")
break
article_chain.append(first_link)
time.sleep(2) # 延迟两秒,实现上面讲的“友好”功能
其实这里又改了一点点:将输出url的print语句加在了while语句中而不是在程序末尾,让程序一旦找到有效的url就立即输出,找到一个就输出一个。而不是找到后先存入article_chain列表,等程序全部运行完后统一全部输出。