OpenCV之Googlenet图像分类
- 个人主页:风间琉璃
- 版权: 本文由【风间琉璃】原创、在CSDN首发、需要转载请联系博主
- 如果文章对你有帮助、欢迎关注、点赞、收藏(一键三连)和订阅专栏哦
目录
前言
一、加载网络模型
二、构建输入
三、执行推理
四、解析输出
前言
GoogLeNet是google推出的基于Inception模块的深度神经网络模型,在2014年的ImageNet竞赛中夺得了冠军,在随后的两年中一直在改进,形成了Inception V2、Inception V3、Inception V4等版本。

使用OpenCV DNN模块部署需要下载Caffe模型文件和描述文件
bvlc_googlenet.caffemodel模型的下载地址:http://dl.caffe.berkeleyvision.org/
bvlc_googlenet.prototxt文件下载地址:opencv_extra/testdata/dnn/bvlc_googlenet.prototxt at master · opencv/opencv_extra · GitHub
一、加载网络模型
在使用Caffe学习框架中已经预训练好的GoogLeNet网络,需要相应的模型权重文件(.caffemodel)以及模型配置文件(.prototxt)。
下面看一下相应的代码并对载入模型的部分进行解释。
string model_bin = "F:/data/CQU/VS/Googllenet_Classification/bvlc_googlenet.caffemodel";
string model_txt = "F:/data/CQU/VS/Googllenet_Classification/bvlc_googlenet.prototxt";
//加载网络模型
Net net = readNetFromCaffe(model_txt, model_bin);
if(net.empty())
{
printf("加载网络模型失败...\n");
return -1;
}使用OpenCV DNN中的 readNet() 函数来加载所需的网络模型的模型权重文件(.caffemodel)和模型配置文件(.prototxt)。除了 readNet() 函数之外, DNN模块还提供了从特定学习框架中载入模型的函数。这些函数无需提供 framework 参数,如readNetFromCaffe(),readNetFromTensorflow(),readNetFromTorch(),readNetFromDarknet(),readNetFromONNX()。
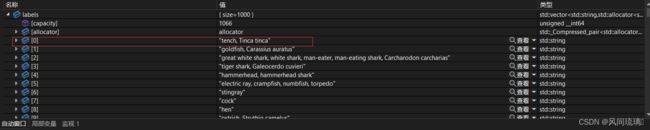
同时,所使用的 GoogLeNet模型已经在1000中类别的ImageNet数据集合进行预训练过。所以需要将这1000个类别调入内存这样便于访问它们,通常这些类别信息存储在txt文件中。 其中一个这种文件为:synset_words.txt文件。包含有所有的类别名称,格式如下:
n01440764 tench, Tinca tinca
n01443537 goldfish, Carassius auratus
n01484850 great white shark, white shark, man-eater, man-eating shark, Carcharodon carcharias
n01491361 tiger shark, Galeocerdo cuvieri
n01494475 hammerhead, hammerhead shark
n01496331 electric ray, crampfish, numbfish, torpedo
...
文件的每一行包含有所有针对一个图片的所有标签或者类别名称。比如,第一行包括有 tench, Tinca Tinca。对于这个同样的鱼它有两个名字。类似,第二行也是对应的金鱼有两个名称。 通常情况下第一个名称是被大多数人最常用到的名字。
下面展示如何将text文件读入内存,并将第一个名称抽取出来作为图像分类的标签。
string labels_txt = "F:/data/CQU/VS/Googllenet_Classification/synset_words.txt";
vector readLabels()
{
vector classNames;
ifstream fp(labels_txt);
if(!fp.is_open())
{
printf("could not open the file");
exit(-1);
}
string name;
while(!fp.eof())
{
getline(fp, name); //读取每一行
if(name.length())
{
//将前面的数字丢掉,加1是因为中间的空格,然后读取分类:n01440764 tench, Tinca tinca--》tench, Tinca tinca
classNames.push_back(name.substr(name.find(' ') + 1));
}
}
fp.close();
return classNames;
}
//得到图像标签
vector labels = readLabels(); 首先,通过打开包含有所有类别名称的文件,将它们分割成新的一行行文本。现在将所有的类都安装下面的格式存储在 classNames 列表中。如下图所示:

二、构建输入
通过 OpenCV中的 imread() 函数读入图片。注意,有些细节需要我们关注。使用DNN 模块载入的预训练好的模型并不能够直接使用读入图像数据。需要预先进行预处理一下。
//输入图片进行预处理
Mat inputBlob = blobFromImage(src, 1.0, Size(224, 224), Scalar(104, 117, 123));
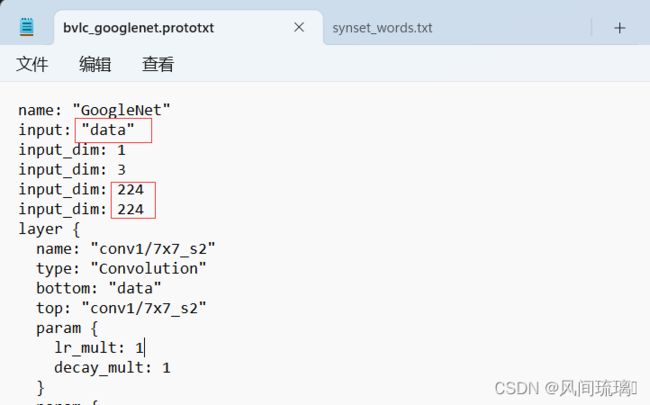
网络的图像输入大小以及其他要求可以查看网络的配置文件
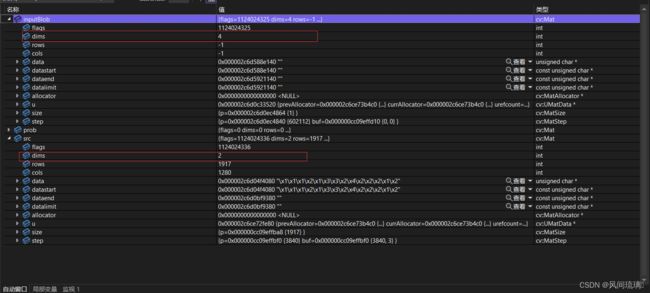
注意:所有的深度学习模型都希望输入数据都是成批次的。然而这里只有一张图片。不管怎样, blob 的输出格式得到的矩阵为[1,3,224,224],blockFromImage() 函数输出的结果是在原来的彩色图像(3维)的基础上又增加了一维。这就是神经网络模型所需要到正确输入格式。
三、执行推理
现在网络输入已经准备好了,可以利用网络进行预测了,这个过程也是把输入图像在网络各层中前向进行传播。
//进行多次推理
for (int i = 0; i < 10; i++)
{
net.setInput(inputBlob, "data");
prob = net.forward("prob");
}这里的data和prob分别是输入层和输出层网络的名称。

网络预测需要两个步骤:
- 首先,将网络的输入中加载图像数据;
- 接着使用forward()函数将输入数据前向通过网络模型,可以获得网络所有的输出。
在 prob中存储着网络的所有输出。在获得正确的分类类别之前,还有一些需要与处理得步骤。现在 prob还是一个向量 (1,1000)。

四、解析输出
prob是一个向量为(1,1000),prob经过变形(reshape)之后,形成 (1000,1)的形状,表示一个1000行,1列的矩阵,每一行对应的一个类别的得分。然后查找概率最大的值以及对应的位置,根据 label索引映射到类别名称。
//打平成一维
Mat probMat = prob.reshape(1, 1);
Point classNumber;
double classProb;
//获取预测图像的最大预测概率值以及最大概率值所在位置(传入的参数都是指针)
minMaxLoc(probMat, NULL, &classProb, NULL, &classNumber);
int classidx = classNumber.x;
printf("\n current image classification : %s, possible : %.2f", labels.at(classidx).c_str(), classProb);
putText(src, labels.at(classidx), Point(20, 20), FONT_HERSHEY_SIMPLEX, 1.0, Scalar(0, 0, 255), 2, 8);
imshow("Image Classification", src);
waitKey(0);由于minMaxLoc位置是传入一个Point,所以其x坐标对应着标签的索引值。

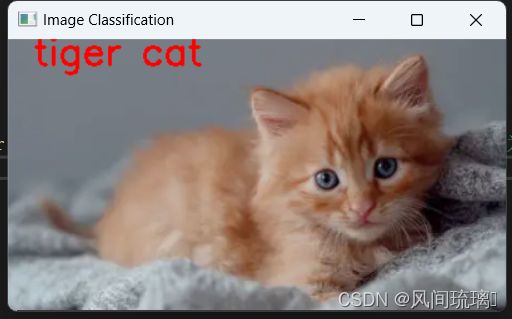
运行结果如下:

源程序:资源下载链接:https://download.csdn.net/download/qq_53144843/88327465(若需要积分才能下载,可以给我留言找我)
// Googllenet_Classification.cpp : 此文件包含 "main" 函数。程序执行将在此处开始并结束。
//
#include
#include
#include
#include
#include
#include
using namespace cv;
using namespace cv::dnn;
using namespace std;
string model_bin = "F:/data/CQU/VS/Googllenet_Classification/bvlc_googlenet.caffemodel";
string model_txt = "F:/data/CQU/VS/Googllenet_Classification/bvlc_googlenet.prototxt";
string labels_txt = "F:/data/CQU/VS/Googllenet_Classification/synset_words.txt";
vector readLabels()
{
vector classNames;
ifstream fp(labels_txt);
if(!fp.is_open())
{
printf("could not open the file");
exit(-1);
}
string name;
while(!fp.eof())
{
getline(fp, name); //读取每一行
if(name.length())
{
classNames.push_back(name.substr(name.find(' ') + 1)); //将前面的数字丢掉,加1是因为中间的空格,然后读取分类:n01440764 tench, Tinca tinca
}
}
fp.close();
return classNames;
}
int main()
{
Mat src = cv::imread("F:/data/CQU/VS/Googllenet_Classification/xiong.png");
if (src.empty())
{
cout << "读取图片失败...\n";
return -1;
}
//namedWindow("src", CV_WINDOW_AUTOSIZE);
//imshow("src", src);
//waitKey(0);
//得到图像标签
vector labels = readLabels();
//加载网络模型
Net net = readNetFromCaffe(model_txt, model_bin);
if(net.empty())
{
cout<<"加载网络模型失败...\n";
return -1;
}
//输入图片进行预处理
Mat inputBlob = blobFromImage(src, 1.0, Size(224, 224), Scalar(104, 117, 123));
Mat prob;
//进行多次推理
for (int i = 0; i < 10; i++)
{
net.setInput(inputBlob, "data");
prob = net.forward("prob");
}
//打平成一维
Mat probMat = prob.reshape(1, 1);
Point classNumber;
double classProb;
//获取预测图像的最大预测概率值以及最大概率值所在位置(传入的参数都是指针)
minMaxLoc(probMat, NULL, &classProb, NULL, &classNumber);
int classidx = classNumber.x;
printf("\n current image classification : %s, possible : %.2f", labels.at(classidx).c_str(), classProb);
putText(src, labels.at(classidx), Point(20, 20), FONT_HERSHEY_SIMPLEX, 1.0, Scalar(0, 0, 255), 2, 8);
imshow("Image Classification", src);
waitKey(0);
return 0;
}
结束语
感谢你观看我的文章呐~本次航班到这里就结束啦
希望本篇文章有对你带来帮助 ,有学习到一点知识~
躲起来的星星也在努力发光,你也要努力加油(让我们一起努力叭)。
最后,博主要一下你们的三连呀(点赞、评论、收藏),不要钱的还是可以搞一搞的嘛~
不知道评论啥的,即使扣个666也是对博主的鼓舞吖 感谢