04JVM_语法糖
一、编译期处理
语法糖java编译器把*.java源码编译为*.class字节码的过程中,自动生成和转换的一些代码(添加的class字节码),减轻程序员的负担。
1.默认构造器
默认构造器没有写任何的构造方法,但经过编译器编译成字节码过程中,会加上调用父类Object的无参构造方法。调用java/lang/Object.”

2.自动拆装箱
①在JDK 5之前,基本类型int转换成包装类型Integer需要手动装箱
Integer x = Integer.valueOf(2);
包装类型Integer转换为基本类型int需要手动拆箱
int y = x.intValue();
②在JDK 5 之后,由编译器在编译阶段实现自动拆装箱。

补充:
Integer在-128~127会复用对象。地址相同
3.泛型集合取值
1.泛型擦除
JDK5后,java在编译泛型代码后执行泛型擦除的动作,泛型信息都当作Object类型处理。
取值的时候会进行Object强制类型转换。

①当调用list.add(10)时,实际调用的是list.add(Object e)这个方法。把泛型信息当成Object处理
②当调用 Integer x = list.get(0),实际调用Object obj = list.get(int index)方法。最后Object类型转换为Integer。Integer x = (Integer)list.get(0)
③如果调用 int x = list.get(0)。类型转换是int x = ((Integer)list.get(0)).intValue();
2.泛型反射
局部变量类型表LocalVariableTable:方法内参数的泛型信息

只有方法参数,方法返回值,带的泛型信息才能反射获取到。

4.可变参数

可变参数是JDK 5加入的特性,String... args其实是String []。
调用foo(实参1,实参2)方法,编译器会根据实参的数量生成一个String数组new String[]{”hello”,”world”}

注意:
如果调用foo()无参方法,那么创建一个空的数组new String[]{},而不是传递null
4.foreach循环
数组循环,JDK 5 加入语法糖,按照下标区遍历的循环结构

①int[] array = {1, 2, 3, 4, 5};编译器转换
int[] array = new int[] {1, 2, 3, 4, 5};
②int e: array 编译器会转换为按照下标区遍历的循环结构。

集合循环
foreach循环被编译器转换为迭代器的调用 list.iterator()

注意:
foreach循环,配合数组和实现了Iterator()接口的集合类一起使用。
5.switch字符串
JDK7开始switch可以用字符串和枚举类
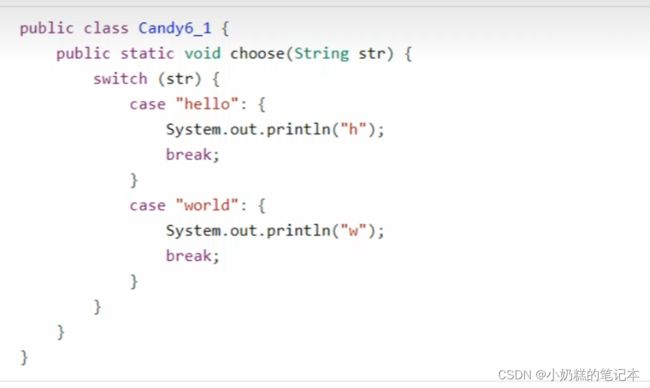
switch配合字符串和枚举类,变量不为null.编译后的字节码文件如下。
第一遍是根据字符串的hashCode和equals将字符串转换为byte类,第二遍根据byte进行比较。

6.switch枚举
原始代码

转换后代码
①定义一个合成类,用来映射枚举的ordinal与数组关系
②枚举的ordinal表示枚举对象的序号,从0开始
③MALE的ordinal()=0,FEMALE的ordinal()=1

7.枚举类
JDK 7 新增
枚举类本质是class,枚举值是class的一个对象。

转换后

8.try-with-resources关闭资源处理
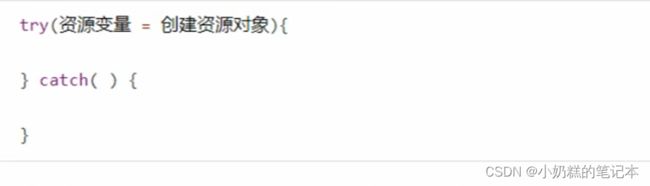
①JDK 7 开始,只要资源对象实现了AutoCloseable接口(文件输入输出流),使用try-with-resources不用写finally语句。编译器在finally会新增正常结束或者抛出异常的方法。
②设计一个addSuppressed(Throwable e)添加被压制异常的方法呢?
为了防止异常信息的丢失。
9.方法重写时的桥接方法
方法重写时返回值有2种情况
①子类的返回值跟父类一致
②子类的返回值是父类返回值的子类

对于子类的返回值是父类返回值的子类。编译器会自动生成一个重写父类的方法,采用桥接的方式
public synthetic bridge Number m()调用子类的方法,同时符合重写的规则。
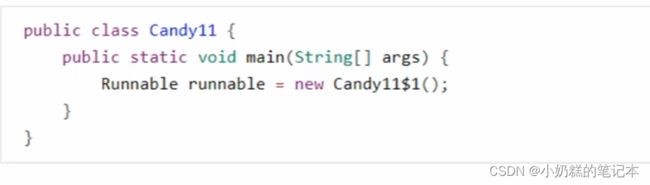
10.匿名内部类
源代码

转换后的代码
①生成一个额外的类Candy11$1实现Runnable接口。

②创建匿名内部类Candy11$1的对象
注意:
匿名内部类引用局部变量时,局部变量必须是final不可变的。因为编译器在创建匿名对象时,将复制给匿名对象的value属性,x就不能发生变化了,值固定住了。