神经网络 06(优化方法)
一、优化方法
网络搭建好,损失函数设计好之后, 根据损失函数更新参数(权重,偏移)。参数更新过程就是一个神经网络优化过程。
二、梯度下降方法
梯度下降法简单来说就是一种寻找使损失函数最小化的方法。从数学上的角度来看,梯度的方向是函数增长速度最快的方向、那么梯度的反方向就是函数减少最快的方向,所以有:

w是权重,E是损失函数
其中,n是学习率,如果学习率太小,那么每次训练之后得到的效果都太小,增大训练的时间成本。如果,学习率太大,那就有可能直接跳过最优解,进入无限的训练中。解决的方法就是,学习率也需要随着训练的进行而变化。


实际中使用较多的是小批量的梯度下降算法,在tf.keras中通过以下方法实现
tf.keras.optimizers.SGD(
learning_rate=0.01, momentum=0.0, nesterov=False, name='SGD', **kwargs
)# 导入相应的工具包
import tensorflow as tf
# 实例化优化方法:SGD
opt = tf.keras.optimizers.SGD(learning_rate=0.1)
# 定义要调整的参数
var = tf.Variable(1.0)
# 定义损失函数:无参但有返回值
loss = lambda: (var ** 2)/2.0
# 计算梯度,并对参数进行更新,步长为 `- learning_rate * grad`
opt.minimize(loss, [var]).numpy()
# 展示参数更新结果
var.numpy()在进行模型训练时,有三个基础的概念:

实际上,梯度下降的几种方式的根本区别就在于 Batch Size不同,,如下表所示:
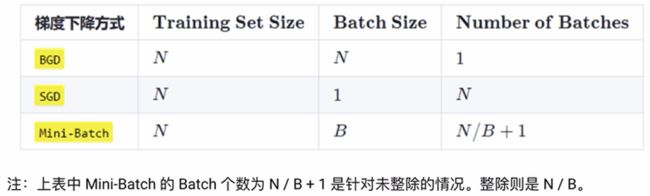
假设数据集有 50000 个训练样本,现在选择 Batch Size = 256 对模型进行训练。
每个 Epoch 要训练的图片数量:50000
训练集具有的 Batch 个数:50000/256+1=196
每个 Epoch 具有的 Iteration 个数:196
10个 Epoch 具有的 Iteration 个数:1960
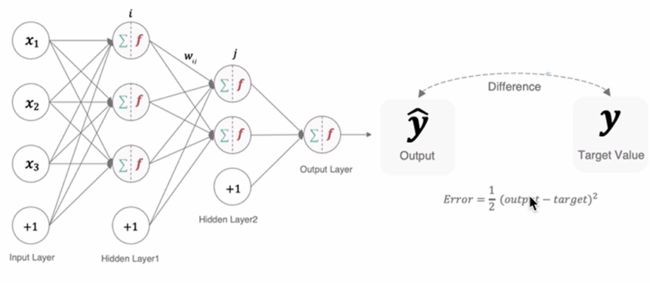
三、反向传播算法(BP算法)
利用反向传播算法对神经网络进行训练。该方法与梯度下降算法相结合,对网络中所有权重计算损失函数的梯度,并利用梯度值来更新权值以最小化损失函数。
3.1 前向传播和反向传播
前向传播是指数据输入的神经网络中,逐层向前传输,一直运算到输出层为止。

在网络的训练过程中经过前向传播后得到的最终结果跟样本的真实值总是存在误差,误差使用损失函数衡量。想要减小这个误差,就用损失函数Error,从后向前,依次求出各个参数的偏导,这就是反向传播。
3.2 链式法则
反向传播算法是利用链式法则进行梯度求解及权重更新的。对于复杂的复合函数,我们将其拆分为一系列的加减乘除或指数,对数,三角函数等初等函数,通过链式法则完成复合函数的求导。为简单起见,这里以一个神经网络中常见的复合函数的例子来说明 这个过程.令复合函数 (x; w,b)为:
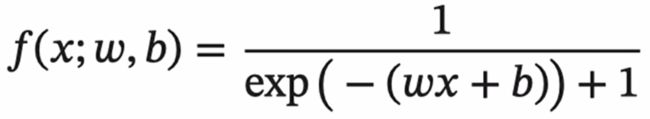
其中x是输入数据,w是权重,b是偏置。我们可以将该复合函数分解为:


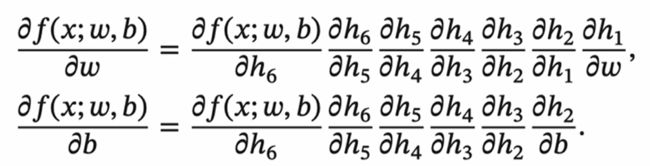


3.3 反向传播算法
反向传播算法利用链式法则对神经网络中的各个节点的权重进行更新。
假设当前前向传播的过程如下图所以:
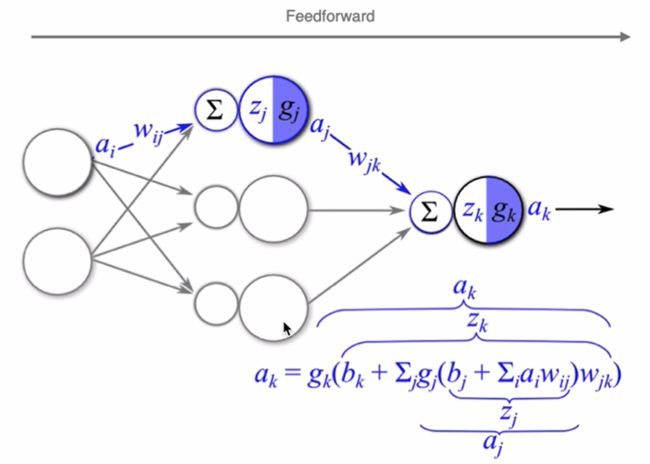
计算损失函数,进行反向传播:

计算梯度值





3.4 梯度下降优化方法
梯度下降算法在进行网络训练时,会遇到鞍点,局部极小值这些问题,那我们怎么改进SGD呢?在这里我们介绍几个比较常用的

3.4.1 动量算法
动量算法主要针对鞍点问题,介绍动量算法之前,首先看下指数加权平均数的计算方法。
指数加权平均数


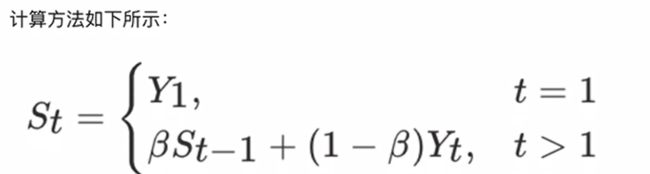
其中Yt为t时刻时的真实值,St为t加权平均后的值,β为权重值。红线即是指数加权平均后的结果。
上图中β设为0.9,那么指数加权平均的计算结果为:

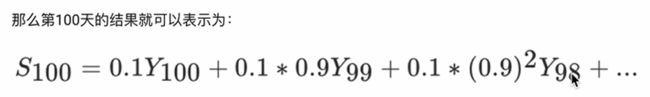
动量梯度下降算法
动量梯度下降 (Gradient Descent with Momentum)计算梯度的指数加权平均数,并利用该值来更新参数值。动量梯度下降法的整个过程为,其中β通常设置为0.9:

与原始的梯度下降算法相比,它的下降趋势更平滑。
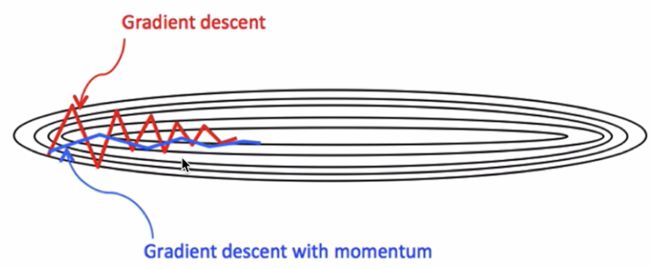
3.4.2 AdaGrad
AdaGrad算法会使用一个小批量随机梯度g_t按元素平方的累加变量st。在首次送代时,AdaGrad将s0中每个元素初始化为0。在t次迭代,首先将小批量随机梯度gt按元素平方后累加到变量st:

其中O是按元素相乘。接着,我们将目标函数自变量中每个元素的学习率通过按元素运算重新调整下:

其中α是学习率,e是为了维持数值稳定性而添加的常数,如10^(-6)。这里开方、除法和乘法的运算都是按元素运算的。这些按元素运算使得目标函数自变量中每个元素都分别拥有自己的学习率。
3.4.3 RMSprop
AdaGrad算法在迭代后期由于学习率过小,能较难找到最优解。为了解决这一问题,RMSProp算法对AdaGrad算法做了一点小小的修改。
不同于AdaGrad算法里状态变量st是截至时间步t所有小批量随机梯度gt按元素平方和,RMSProp(RootMean Square Prop) 算法将这些梯度按元素平方做指数加权移动平均
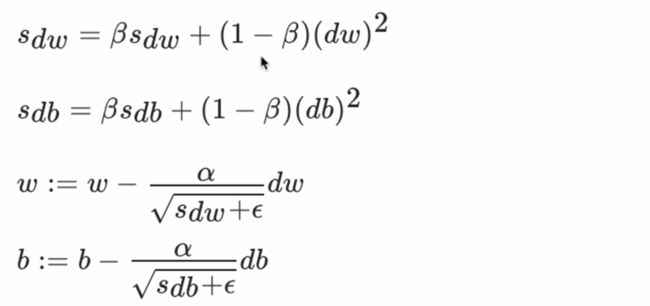
其中e是一样为了维持数值稳定一个常数。最终自变量每个元素的学习率在迭代过程中就不再一直降低。RMSProp 有助于减少抵达最小值路径上的摆动,并允许使用一个更大的学习率α,从而加快算法学习速度。
3.4.4 Adam
Adam 优化算法 (Adaptive Moment Estimation,自适应矩估计)将 Momentum 和RMSProp算法结合在一起。Adam算法在RMSProp算法基础上对小批量随机梯度也做了指数加权移动平均
假设用每一个mini-batch 计算 dw、db,第t次迭代时:
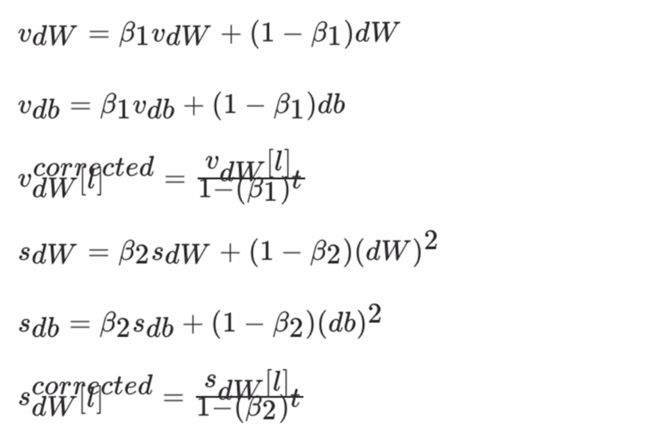

建议的参数设置的值
。学习率a:需要尝试一系列的值,来寻找比较合适的
。β1:常用的缺省值为 0.9
。β2:建议为0.999
e:默认值1e-8
四、学习率退火
在训练神经网络时,一般情况下学习率都会随着训练而变化,这主要是由于,在神经网络训练的后期,如果学习率过高,会造成loss的振荡,但是如果学习率减小的过快,又会造成收敛变慢的情况。
4.1 分段常数衰减
分段常数衰减是在事先定义好的训练次数区间上,设置不同的学习率常数。刚开始学习率大一些,之后越来越小,区间的设置需要根据样本量调整,一般样本量越大区间间隔应该越小。


4.2 指数衰减

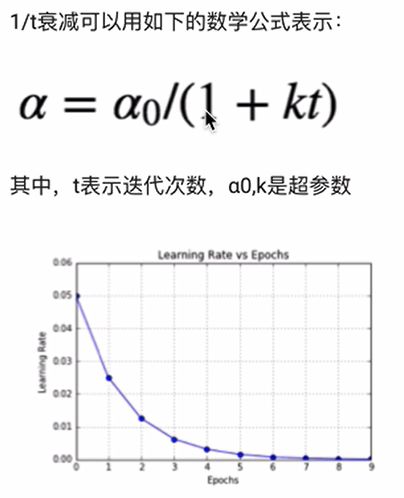
4.3 1/t衰减