rancher
1 docker
参考docker-ce
# 移除已有版本
sudo yum remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-engine
# 配置仓库
sudo yum install -y yum-utils \
device-mapper-persistent-data \
lvm2
sudo yum-config-manager \
--add-repo \
https://download.docker.com/linux/centos/docker-ce.repo
# 安装docker-ce
sudo yum install docker-ce docker-ce-cli containerd.io -y
# 修改docker镜像存储位置
mkdir -p /appdata/lib/docker
# 修改,找到对应的内容,修改配置
vi /lib/systemd/system/docker.service
ExecStart=/usr/bin/dockerd --data-root /appdata/lib/docker -H fd:// --containerd=/run/containerd/containerd.sock
# 将之前安装的docker目录复制过来
# 重启
systemctl daemon-reload
systemctl start docker
# docker卸载
sudo yum remove docker-ce docker-ce-cli containerd.io
执行docker info,可以看到根目录发生变化了
2 rancher
参考rancher手动快速部署
docker run -d --privileged --restart=unless-stopped \
-p 80:80 -p 443:443 \
rancher/rancher:latest
还可以更换映射端口
docker run -d --privileged --restart=unless-stopped \
-p 8080:80 -p 8443:443 \
rancher/rancher
输入ip地址,出现下面的内容,就ok了。参考rancher2.0安装k8s集群

在master节点添加--etcd --controlplane, node节点只需要--worker构建还有一个过程,应该是会下载k8s相关文件。

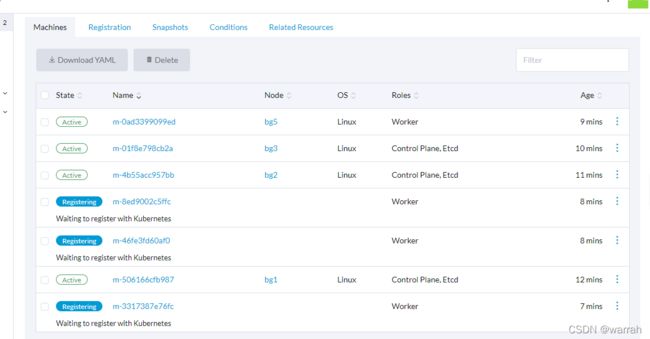
rancher安装好集群后并不能使用kubectl,没有命令行作为工程师来讲,感觉总是不痛快.
Install and Set Up kubectl on Linux
注意对应k8s的版本,下面的命令是直接将官网的命令复制过来
curl -LO https://dl.k8s.io/release/v1.21.5/bin/linux/amd64/kubectl
sudo install -o root -g root -m 0755 kubectl /usr/local/bin/kubectl
chmod +x kubectl
mkdir -p ~/.local/bin/kubectl
mv ./kubectl ~/.local/bin/kubectl
[root@bg1 ~]# kubectl version
Client Version: version.Info{Major:"1", Minor:"21", GitVersion:"v1.21.5", GitCommit:"aea7bbadd2fc0cd689de94a54e5b7b758869d691", GitTreeState:"clean", BuildDate:"2021-09-15T21:10:45Z", GoVersion:"go1.16.8", Compiler:"gc", Platform:"linux/amd64"}
The connection to the server localhost:8080 was refused - did you specify the right host or port?
上面直接解决了kubectl,还是不能通过命令获取节点,需要进一步处理.这个rancher内部的config文件,直接复制用不了

在k8s的集群节点,注意并不是rancher的机器,其中fay是我自定义集群的名称
cd /etc/kubernetes/ssl/
kubectl config set-cluster fay --certificate-authority=kube-ca.pem --server=https://10.128.2.185:6443
kubectl config set-credentials fay --client-certificate=kube-scheduler.pem --client-key=kube-scheduler-key.pem
kubectl config set-context fay --cluster=fay --user=fay
kubectl config use-context fay
注意上面master节点中也可以使用
kubectl config set-cluster fay --certificate-authority=kube-ca.pem --server=https://127.0.0.1:6443
执行完毕后,可以再10.128.2.185这台机器看到
[root@bg2 ~]# cat ~/.kube/config
apiVersion: v1
clusters:
- cluster:
certificate-authority: /etc/kubernetes/ssl/kube-ca.pem
server: https://10.128.2.185:6443
name: fay
contexts:
- context:
cluster: fay
user: fay
name: fay
current-context: fay
kind: Config
preferences: {}
users:
- name: fay
user:
client-certificate: /etc/kubernetes/ssl/kube-scheduler.pem
client-key: /etc/kubernetes/ssl/kube-scheduler-key.pem
[root@bg2 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
bg1 Ready controlplane,etcd 13h v1.21.5
bg2 Ready controlplane,etcd 13h v1.21.5
bg3 Ready controlplane,etcd 13h v1.21.5
bg4 Ready worker 13h v1.21.5
bg5 Ready worker 13h v1.21.5
bg6 Ready worker 13h v1.21.5
bg7 Ready worker 13h v1.21.5
上面是在master节点中执行的结果,如果在workder节点执行kubectl命令呢?worker节点中/etc/kubernetes/ssl/里面的文件明显比master节点少很多,方式有所不同

通过kubectl get nodes -o wide得到集群节点情况,但rancher中仍旧存在一些不清楚地地方,自己定义的集群无法explore,应该还是某个地方有问题

执行docker logs --tail=50 7144e4c671f3,查看日志
2021-12-04 06:31:23.648933 I | mvcc: finished scheduled compaction at 290246 (took 75.880759ms)
2021/12/04 06:31:40 [ERROR] error syncing 'ingress-ip-domain': handler copy-settings: error applying setting object for cluster [c-j5c6g]: the server could not find the requested resource, requeuing
2021/12/04 06:31:40 [ERROR] error syncing 'install-uuid': handler copy-settings: error applying setting object for cluster [c-j5c6g]: the server could not find the requested resource, requeuing
执行kubectl get pods -n cattle-system -o wide,发现集群存在异常

[root@bg1 ~]# kubectl logs -f cattle-cluster-agent-cddf44f6b-xpmr7 -n cattle-system
Error from server (Forbidden): pods "cattle-cluster-agent-cddf44f6b-xpmr7" is forbidden: User "system:kube-scheduler" cannot get resource "pods/log" in API group "" in the namespace "cattle-system"
跟进所有的pod,可以看到,这些也有问题

2.1 网络驱动
Pod网络的管理并非k8s系统内置,而由第三方以CNI插件方式完成,在k8s中网络是全联通。
- 一个Pod一个IP,故Pod的IP是全局唯一。
- 所有的Pod可以与任何其他Pod直接通信,无需使用NAT映射
- 所有节点可以与所有Pod直接通信,无需NAT映射
- Pod内部获取到的IP地址与其他Pod或节点与其通信的IP地址时同一个。
可以看到rancher中有四个选项,每个选项对应的配置有所区别,默认是Canel
- Flannel
通过划分子网来实现Pod的IP唯一,每个节点都是一个单独的子网,子网信息通过flannel存放在etcd中,flannel通过daemon的方式运行。

每个节点都看到flannel的进程

从下面两台机器可以看到k8s集群自身是一个大子网,每个节点都是一个小子网。子网不要与物理网络冲突。
[root@master1 flannel]# cat /var/run/flannel/subnet.env
FLANNEL_NETWORK=10.244.0.0/16
FLANNEL_SUBNET=10.244.0.1/24
FLANNEL_MTU=1450
FLANNEL_IPMASQ=true
[root@master3 ~]# cat /var/run/flannel/subnet.env
FLANNEL_NETWORK=10.244.0.0/16
FLANNEL_SUBNET=10.244.2.1/24
FLANNEL_MTU=1450
FLANNEL_IPMASQ=true
flannel默认的工作数据转发方式时vxlan,最早支持upd但因性能问题已弃用。vxlan是一种overlap网络方案。源数据包封装在另一个网络包里面进行路由转发,vxlan是linux支持的隧道的技术,端到端设备的通信技术。
veth(对数据的封装和解封装)封装在flannel.1这个虚拟网卡中,

执行yum install bridge-utils -y,网桥一头接着cni0,一头接着宿主机的veth6034a749,下面看到了cni的网桥
[root@master1 ~]# brctl show cni0
bridge name bridge id STP enabled interfaces
cni0 8000.aa56802b9fd3 no veth6034a749
[root@master1 ~]# ifconfig
cni0: flags=4163 mtu 1450
inet 10.244.0.1 netmask 255.255.255.0 broadcast 10.244.0.255
inet6 fe80::a856:80ff:fe2b:9fd3 prefixlen 64 scopeid 0x20
ether aa:56:80:2b:9f:d3 txqueuelen 1000 (Ethernet)
RX packets 47453570 bytes 8231099330 (7.6 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 47794281 bytes 6540389640 (6.0 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
docker0: flags=4099 mtu 1500
inet 172.17.0.1 netmask 255.255.0.0 broadcast 172.17.255.255
ether 02:42:ed:5c:87:8c txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
eth0: flags=4163 mtu 1500
inet 10.128.4.164 netmask 255.255.255.0 broadcast 10.128.4.255
inet6 fe80::f816:3eff:fe2b:3b5f prefixlen 64 scopeid 0x20
ether fa:16:3e:2b:3b:5f txqueuelen 1000 (Ethernet)
RX packets 377170847 bytes 94262979128 (87.7 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 359637576 bytes 91164463064 (84.9 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
flannel.1: flags=4163 mtu 1450
inet 10.244.0.0 netmask 255.255.255.255 broadcast 10.244.0.0
inet6 fe80::4c4d:6eff:fe7e:ea22 prefixlen 64 scopeid 0x20
ether 4e:4d:6e:7e:ea:22 txqueuelen 0 (Ethernet)
RX packets 43377005 bytes 4252841887 (3.9 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 43377013 bytes 7939553004 (7.3 GiB)
TX errors 0 dropped 8 overruns 0 carrier 0 collisions 0
lo: flags=73 mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10
loop txqueuelen 1000 (Local Loopback)
RX packets 164293744 bytes 44604421253 (41.5 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 164293744 bytes 44604421253 (41.5 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
veth6034a749: flags=4163 mtu 1450
inet6 fe80::a8a9:59ff:fe7d:c6ff prefixlen 64 scopeid 0x20
ether aa:a9:59:7d:c6:ff txqueuelen 0 (Ethernet)
RX packets 47453570 bytes 8895449310 (8.2 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 47794287 bytes 6540390080 (6.0 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
flannel还有一个Host GW主机网关模式,为路由方案。Pod中的eth0是在容器内部,并不是上面宿主机的,下面的veth就是上面宿主机中的veth6034a749。如果是节点内部,通过CNI作为二级交换机,就可以实现通信了。跨子网就需要经过默认网关flannel.1,从路由表中到目的ip

flannel有自己的网桥,而不是使用docker0的
[root@master3 ~]# ip route
default via 10.128.4.1 dev eth0 proto dhcp metric 100
10.128.4.0/24 dev eth0 proto kernel scope link src 10.128.4.211 metric 100
10.244.0.0/24 via 10.244.0.0 dev flannel.1 onlink
10.244.1.0/24 via 10.244.1.0 dev flannel.1 onlink
10.244.3.0/24 via 10.244.3.0 dev flannel.1 onlink
10.244.4.0/24 via 10.244.4.0 dev flannel.1 onlink
10.244.5.0/24 via 10.244.5.0 dev flannel.1 onlink
169.254.169.254 via 10.128.4.254 dev eth0 proto dhcp metric 100
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1
二层VTEP设备之间需要知道目的MAC地址。这些mac地址的获取,当flannel进程启动后,会自动添加节点的ARP(地址解析协议,Address Resolution Protocol)记录。知道目的mac地址,封装二层数据帧,但这个数据帧是没法到达目的地,需要进一步封装UDP包。因为有多层封包,使用vxlan会导致性能存在一定瓶颈。
[root@master3 ~]# ip neigh show dev flannel.1
10.244.4.0 lladdr fa:f4:e7:71:0e:85 PERMANENT
10.244.1.0 lladdr 36:eb:26:2c:0b:4e PERMANENT
10.244.0.0 lladdr 4e:4d:6e:7e:ea:22 PERMANENT
10.244.5.0 lladdr ca:02:b2:d2:81:e8 PERMANENT
10.244.3.0 lladdr 0a:b9:af:cf:03:ca PERMANENT
执行kubectl get pods -o yaml
Host GW工作在二层,性能比xvlan好,但是不能做三层转发。
-
Calico
-
Calico是一个纯三层的数据中心网络方案,calico是基于路由表实现容器数据包转发,但不同于flannel使用flanneld进程来维护路由信息的做法,calico采用BGP协议来自动维护整个集群的路由信息。
BGP是动态路由协议,大型规模的网络架构采用。两个自治系统,不在一个网络,想通信,通过路由器将两个自治系统AS连起来,BGP就是两个自治系统连接在一起的方式。
路由表写入到每个节点上,路由规则可以在路由表中手工添加,如果vlan节点很多,BGP可以动态学习到路由表信息。
calico网络原理分析

Calico主要由三部分组成,可以通过calloctl命令行界面实现高级策略和网络。 -
Felix:以DeamonSet方式部署,运行在每一个节点上,主要负责维护宿主机上路由规则以及ACL规则
-
BGP client(BIRD):主要负责把felix写入kernel的路由信息分发到集群calico网络
-
Etcd:分布式键值存储,保存calico的策略和网络配置状态,从上图看到了重要性,故而etcd推荐独立部署。
生产环境切换网络,pod需要重建。calico的两种网络模式BGP和IP-IP性能分析
数据包不是通过网桥,而是通过ARP代理传到目的节点
calico要看看自己有没有那么厉害的运维实力,管理大型网络,另外有些公有云也不一定支持BGP协议(阿里云VPC可以支持BGP)。如果小型性能可以考虑flanno hostgw方式。上百台需要网络采用calico。

-
Canel

-
weave

2.2 集群选项