【大数据】美团 DB 数据同步到数据仓库的架构与实践
美团 DB 数据同步到数据仓库的架构与实践
- 1.背景
- 2.整体架构
- 3.Binlog 实时采集
- 4.离线还原 MySQL 数据
- 5.Kafka2Hive
- 6.对 Camus 的二次开发
- 7.Checkdone 的检测逻辑
- 8.Merge
- 9.Merge 流程举例
- 10.实践一:分库分表的支持
- 11.实践二:删除事件的支持
- 12.总结与展望
1.背景
在数据仓库建模中,未经任何加工处理的原始业务层数据,我们称之为 ODS(Operational Data Store)数据。在互联网企业中,常见的 ODS 数据有 业务日志数据(Log)和 业务 DB 数据(DB)两类。对于业务 DB 数据来说,从 MySQL 等关系型数据库的业务数据进行采集,然后导入到 Hive 中,是进行数据仓库生产的重要环节。
如何准确、高效地把 MySQL 数据同步到 Hive 中?一般常用的解决方案是批量取数并 Load:直连 MySQL 去 Select 表中的数据,然后存到本地文件作为中间存储,最后把文件 Load 到 Hive 表中。这种方案的优点是实现简单,但是随着业务的发展,缺点也逐渐暴露出来:
- 性能瓶颈:随着业务规模的增长,
Select From MySQL→Save to Localfile→Load to Hive这种数据流花费的时间越来越长,无法满足下游数仓生产的时间要求。 - 直接从 MySQL 中
Select大量数据,对 MySQL 的影响非常大,容易造成慢查询,影响业务线上的正常服务。 - 由于 Hive 本身的语法不支持更新、删除等 SQL 原语,对于 MySQL 中发生
Update/Delete的数据无法很好地进行支持。
为了彻底解决这些问题,我们逐步转向 CDC(Change Data Capture)+ Merge 的技术方案,即实时 Binlog 采集 + 离线处理 Binlog 还原业务数据的这样一套解决方案。Binlog 是 MySQL 的二进制日志,记录了 MySQL 中发生的所有数据变更,MySQL 集群自身的主从同步就是基于 Binlog 做的。
本文主要从 Binlog 实时采集 和 离线处理 Binlog 还原业务数据 两个方面,来介绍如何实现 DB 数据准确、高效地进入数仓。
2.整体架构
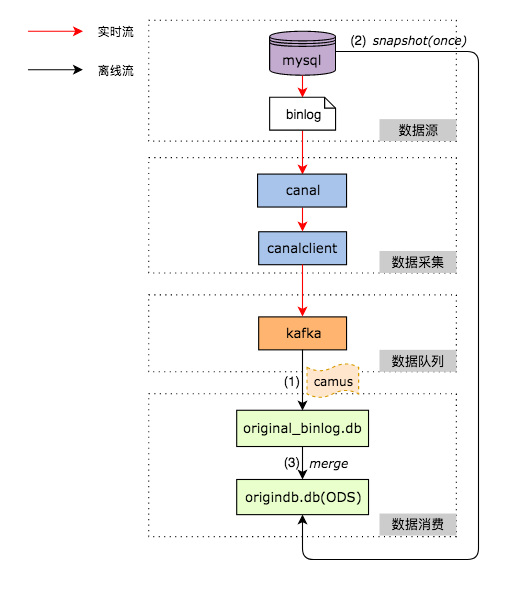
整体的架构如上图所示。在 Binlog 实时采集方面,我们采用了阿里巴巴的开源项目 Canal,负责从 MySQL 实时拉取 Binlog 并完成适当解析。Binlog 采集后会暂存到 Kafka 上供下游消费。整体实时采集部分如图中红色箭头所示。
离线处理 Binlog 的部分,如图中黑色箭头所示,通过下面的步骤在 Hive 上还原一张 MySQL 表:
- 采用 Linkedin 的开源项目
Camus,负责每小时把 Kafka 上的 Binlog 数据拉取到 Hive 上。 - 对每张 ODS 表,首先需要一次性制作快照(
Snapshot),把 MySQL 里的存量数据读取到 Hive 上,这一过程底层采用直连 MySQL 去 Select 数据的方式。 - 对每张 ODS 表,每天基于存量数据和当天增量产生的 Binlog 做 Merge,从而还原出业务数据。
我们回过头来看看,背景中介绍的批量取数并 Load 方案遇到的各种问题,为什么用这种方案能解决上面的问题呢?
- 首先,Binlog 是流式产生的,通过对 Binlog 的实时采集,把部分数据处理需求由每天一次的批处理分摊到实时流上。无论从性能上还是对 MySQL 的访问压力上,都会有明显地改善。
- 第二,Binlog 本身记录了数据变更的类型(
Insert/Update/Delete),通过一些语义方面的处理,完全能够做到精准的数据还原。
3.Binlog 实时采集
对 Binlog 的实时采集包含两个主要模块:
- 一是
CanalManager,主要负责采集任务的分配、监控报警、元数据管理以及和外部依赖系统的对接; - 二是真正执行采集任务的
Canal和CanalClient。

当用户提交某个 DB 的 Binlog 采集请求时,CanalManager 首先会调用 DBA 平台的相关接口,获取这一 DB 所在 MySQL 实例的相关信息,目的是从中选出最适合 Binlog 采集的机器。然后把 采集实例(Canal Instance)分发到合适的 Canal 服务器 上,即 CanalServer 上。在选择具体的 CanalServer 时,CanalManager 会考虑负载均衡、跨机房传输等因素,优先选择负载较低且同地域传输的机器。
CanalServer 收到采集请求后,会在 ZooKeeper 上对收集信息进行注册。注册的内容包括:
- 以 Instance 名称命名的永久节点。
- 在该永久节点下注册以自身
ip:port命名的临时节点。
这样做的目的有两个:
- 高可用:CanalManager 对 Instance 进行分发时,会选择两台 CanalServer,一台是 Running 节点,另一台作为 Standby 节点。Standby 节点会对该 Instance 进行监听,当 Running 节点出现故障后,临时节点消失,然后 Standby 节点进行抢占。这样就达到了容灾的目的。
- 与 CanalClient 交互:CanalClient 检测到自己负责的 Instance 所在的 Running CanalServer 后,便会进行连接,从而接收到 CanalServer 发来的 Binlog 数据。
对 Binlog 的订阅以 MySQL 的 DB 为粒度,一个 DB 的 Binlog 对应了一个 Kafka Topic。底层实现时,一个 MySQL 实例下所有订阅的 DB,都由同一个 Canal Instance 进行处理。这是因为 Binlog 的产生是以 MySQL 实例为粒度的。CanalServer 会抛弃掉未订阅的 Binlog 数据,然后 CanalClient 将接收到的 Binlog 按 DB 粒度分发到 Kafka 上。
4.离线还原 MySQL 数据
完成 Binlog 采集后,下一步就是利用 Binlog 来还原业务数据。首先要解决的第一个问题是把 Binlog 从 Kafka 同步到 Hive 上。
5.Kafka2Hive
整个 Kafka2Hive 任务的管理,在美团数据平台的 ETL 框架下进行,包括任务原语的表达和调度机制等,都同其他 ETL 类似。而底层采用 LinkedIn 的开源项目 Camus,并进行了有针对性的二次开发,来完成真正的 Kafka2Hive 数据传输工作。
6.对 Camus 的二次开发
Kafka 上存储的 Binlog 未带 Schema,而 Hive 表必须有 Schema,并且其分区、字段等的设计,都要便于下游的高效消费。对 Camus 做的第一个改造,便是将 Kafka 上的 Binlog 解析成符合目标 Schema 的格式。
对 Camus 做的第二个改造,由美团的 ETL 框架所决定。在我们的任务调度系统中,目前只对同调度队列的任务做上下游依赖关系的解析,跨调度队列是不能建立依赖关系的。而在 MySQL2Hive 的整个流程中,Kafka2Hive 的任务需要每小时执行一次(小时队列),Merge 任务每天执行一次(天队列)。而 Merge 任务的启动必须要严格依赖小时 Kafka2Hive 任务的完成。
为了解决这一问题,我们引入了 Checkdone 任务。Checkdone 任务是天任务,主要负责检测前一天的 Kafka2Hive 是否成功完成。如果成功完成了,则 Checkdone 任务执行成功,这样下游的 Merge 任务就可以正确启动了。
7.Checkdone 的检测逻辑
Checkdone 是怎样检测的呢?每个 Kafka2Hive 任务成功完成数据传输后,由 Camus 负责在相应的 HDFS 目录下记录该任务的启动时间。Checkdone 会扫描前一天的所有时间戳,如果最大的时间戳已经超过了 0 点,就说明前一天的 Kafka2Hive 任务都成功完成了,这样 Checkdone 就完成了检测。
此外,由于 Camus 本身只是完成了读 Kafka 然后写 HDFS 文件的过程,还必须完成对 Hive 分区的加载才能使下游查询到。因此,整个 Kafka2Hive 任务的最后一步是加载 Hive 分区。这样,整个任务才算成功执行。
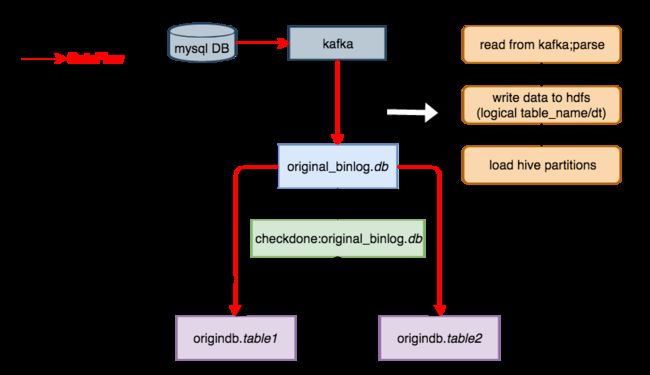
每个 Kafka2Hive 任务负责读取一个特定的 Topic,把 Binlog 数据写入 original_binlog 库下的一张表中,即前面图中的 original_binlog.db,其中存储的是对应到一个 MySQL DB 的全部 Binlog。

上图说明了一个 Kafka2Hive 完成后,文件在 HDFS 上的目录结构。假如一个 MySQL DB 叫做 user,对应的 Binlog 存储在 original_binlog.user 表中。ready 目录中,按天存储了当天所有成功执行的 Kafka2Hive 任务的启动时间,供 Checkdone 使用。每张表的 Binlog,被组织到一个分区中,例如 userinfo 表的 Binlog,存储在 table_name=userinfo 这一分区中。每个 table_name 一级分区下,按 dt 组织二级分区。图中的 xxx.lzo 和 xxx.lzo.index 文件,存储的是经过 lzo 压缩的 Binlog 数据。
8.Merge
Binlog 成功入仓后,下一步要做的就是基于 Binlog 对 MySQL 数据进行还原。Merge 流程做了两件事,首先把当天生成的 Binlog 数据存放到 Delta 表中,然后和已有的存量数据做一个基于主键的 Merge。Delta 表中的数据是当天的最新数据,当一条数据在一天内发生多次变更时,Delta 表中只存储最后一次变更后的数据。
把 Delta 数据和存量数据进行 Merge 的过程中,需要有唯一键来判定是否是同一条数据。如果同一条数据既出现在存量表中,又出现在 Delta 表中,说明这一条数据发生了更新,则选取 Delta 表的数据作为最终结果;否则说明没有发生任何变动,保留原来存量表中的数据作为最终结果。Merge 的结果数据会 Insert Overwrite 到原表中,即前面图中的 origindb.table。
9.Merge 流程举例
下面用一个例子来具体说明Merge的流程。

数据表共 id、value 两列,其中 id 是主键。在提取 Delta 数据时,对同一条数据的多次更新,只选择最后更新的一条。所以对 id=1 的数据,Delta 表中记录最后一条更新后的值 value=120。Delta 数据和存量数据做 Merge 后,最终结果中,新插入一条数据(id=4),两条数据发生了更新(id=1 和 id=2),一条数据未变(id=3)。
默认情况下,我们采用 MySQL 表的主键作为这一判重的唯一键,业务也可以根据实际情况配置不同于 MySQL 的唯一键。
上面介绍了基于 Binlog 的数据采集和 ODS 数据还原的整体架构。下面主要从两个方面介绍我们解决的实际业务问题。
10.实践一:分库分表的支持
随着业务规模的扩大,MySQL 的分库分表情况越来越多,很多业务的分表数目都在几千个这样的量级。而一般数据开发同学需要把这些数据聚合到一起进行分析。如果对每个分表都进行手动同步,再在 Hive 上进行聚合,这个成本很难被我们接受。因此,我们需要在 ODS 层就完成分表的聚合。

首先,在 Binlog 实时采集时,我们支持把不同 DB 的 Binlog 写入到同一个 Kafka Topic。用户可以在申请 Binlog 采集时,同时勾选同一个业务逻辑下的多个物理 DB。通过在 Binlog 采集层的汇集,所有分库的 Binlog 会写入到同一张 Hive 表中,这样下游在进行 Merge 时,依然只需要读取一张 Hive 表。
第二,Merge 任务的配置支持正则匹配。通过配置符合业务分表命名规则的正则表达式,Merge 任务就能了解自己需要聚合哪些 MySQL 表的 Binlog,从而选取相应分区的数据来执行。
这样通过两个层面的工作,就完成了分库分表在 ODS 层的合并。
这里面有一个技术上的优化,在进行 Kafka2Hive 时,我们按业务分表规则对表名进行了处理,把物理表名转换成了逻辑表名。例如 userinfo123 这张表名会被转换为 userinfo,其 Binlog 数据存储在 original_binlog.user 表的 table_name=userinfo 分区中。这样做的目的是防止过多的 HDFS 小文件和 Hive 分区造成的底层压力。
11.实践二:删除事件的支持
Delete 操作在 MySQL 中非常常见,由于 Hive 不支持 Delete,如果想把 MySQL 中删除的数据在 Hive 中删掉,需要采用 “迂回” 的方式进行。
对需要处理 Delete 事件的 Merge 流程,采用如下两个步骤:
- 首先,提取出发生了 Delete 事件的数据,由于 Binlog 本身记录了事件类型,这一步很容易做到。将存量数据(表 A)与被删掉的数据(表 B)在主键上做左外连接(
Left outer join),如果能够全部join到双方的数据,说明该条数据被删掉了。因此,选择结果中表 B 对应的记录为 NULL 的数据,即是应当被保留的数据。 - 然后,对上面得到的被保留下来的数据,按照前面描述的流程做常规的 Merge。

12.总结与展望
作为数据仓库生产的基础,美团数据平台提供的基于 Binlog 的 MySQL2Hive 服务,基本覆盖了美团内部的各个业务线,目前已经能够满足绝大部分业务的数据同步需求,实现 DB 数据准确、高效地入仓。在后面的发展中,我们会集中解决 CanalManager 的单点问题,并构建跨机房容灾的架构,从而更加稳定地支撑业务的发展。
本文主要从 Binlog 流式采集和基于 Binlog 的 ODS 数据还原两方面,介绍了这一服务的架构,并介绍了我们在实践中遇到的一些典型问题和解决方案。希望能够给其他开发者一些参考价值,同时也欢迎大家和我们一起交流。
本文转载于:
- 作者:美团技术团队
- 标题:美团DB数据同步到数据仓库的架构与实践
- 链接:https://tech.meituan.com/2018/12/06/binlog-dw.html