介绍保存与读取Keras模型的方法,并对MNIST数据集的训练模型尝试进行手写识别
第一部分:介绍保存与读取Keras模型的方法
根据参考资料1,keras模型可保存为两种文件:JSON格式或者YAML格式
用户不必太关心两种格式的数据保存方式(至少我这样刚入门的暂时没必要这么深入)。记得摄像头的标定数据也是YAML格式,也有专门的API函数保存和读取数据的。
Deep.Learning.for.Computer.Vision.with.Python.Starter.Bundle提供了使用Keras生成神经网络操作MNIST数据集的例程。我把两者合并为以下代码。使用多行注释注释掉的就是和MNIST数据集操作有关的语句,正常颜色的就是Keras模型的保存和读取方法。
方法1:
1. keras_mnistMdlWriteLoad.py
'''
# import the necessary packages
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from keras.models import Sequential
from keras.layers.core import Dense
from keras.optimizers import SGD
from sklearn import datasets
import matplotlib.pyplot as plt
import numpy as np
import argparse
import os
'''
from keras.models import model_from_json
'''
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-o", "--output", default="output/keras_mnist.png", #required=True,
help="path to the output loss/accuracy plot")
args = vars(ap.parse_args())
# grab the MNIST dataset (if this is your first time running this
# script, the download may take a minute -- the 55MB MNIST dataset
# will be downloaded)
print("[INFO] loading MNIST (full) dataset...")
path1 = os.path.dirname(os.path.abspath(__file__))
dataset = datasets.fetch_mldata("MNIST Original", data_home=path1)
# scale the raw pixel intensities to the range [0, 1.0], then
# construct the training and testing splits
data = dataset.data.astype("float") / 255.0
(trainX, testX, trainY, testY) = train_test_split(data,
dataset.target, test_size=0.25)
# convert the labels from integers to vectors
lb = LabelBinarizer()
trainY = lb.fit_transform(trainY)
testY = lb.transform(testY)
# define the 784-256-128-10 architecture using Keras
model = Sequential()
model.add(Dense(256, input_shape=(784,), activation="sigmoid"))
model.add(Dense(128, activation="sigmoid"))
model.add(Dense(10, activation="softmax"))
# train the model using SGD
print("[INFO] training network...")
sgd = SGD(0.01)
model.compile(loss="categorical_crossentropy", optimizer=sgd,
metrics=["accuracy"])
H = model.fit(trainX, trainY, validation_data=(testX, testY),
epochs=100, batch_size=128)
# evaluate the network
print("[INFO] evaluating network...")
predictions = model.predict(testX, batch_size=128)
print(classification_report(testY.argmax(axis=1),
predictions.argmax(axis=1),
target_names=[str(x) for x in lb.classes_]))
# plot the training loss and accuracy
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, 100), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, 100), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, 100), H.history["acc"], label="train_acc")
plt.plot(np.arange(0, 100), H.history["val_acc"], label="val_acc")
plt.title("Training Loss and Accuracy")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend()
plt.savefig(args["output"])
'''
# - ----------------------------------------------------------------------------
model_json = model.to_json()
with open("model.json", "w") as json_file:
json_file.write(model_json)
# serialize weights to HDF5
model.save_weights("model.h5")
print("Saved model to disk")
# load json and create model
json_file = open('model.json', 'r')
loaded_model_json = json_file.read()
json_file.close()
loaded_model = model_from_json(loaded_model_json)
#load weights into new model
loaded_model.load_weights("model.h5")
print("Loaded model from disk")
# evaluate the network
print("[INFO] evaluating network...")
predictions = loaded_model.predict(testX, batch_size=128)
print(classification_report(testY.argmax(axis=1),
predictions.argmax(axis=1),
target_names=[str(x) for x in lb.classes_]))如果喜欢YAML,则只需要把上面的json改变为yaml即可。
取消了上面的多行注释,可以直接运行代码。
以上代码的运行结果将会显示,model和loaded_model的效果是一样的。是参数相同的、结构相同的两个网络。
方法2:
from keras.models import Sequential
model = Sequential()
# ...
# 省略model训练过程
#保存到文件
model.save('shallownet_wieght.hdf5')
#从文件读取
model = load_model('shallownet_wieght.hdf5')
第二部分:对MNIST数据集的训练模型尝试进行手写识别
使用上面的代码可以把训练好的模型保存下来。下一次若还是同样的训练样本、同样的网络结构,就不用重复训练消耗CPU资源和时间了。
下面的代码读取了使用MNIST数据集训练好的模型,对我的手写数字进行识别。
2. keras_mnistMdlTest.py
# import the necessary packages
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from keras.models import Sequential
from keras.layers.core import Dense
from keras.optimizers import SGD
from sklearn import datasets
import matplotlib.pyplot as plt
import numpy as np
import argparse
import os
from keras.models import model_from_json
import cv2
# later 读取了Keras模型参数
# load json and create model
json_file = open('model.json', 'r')
loaded_model_json = json_file.read()
json_file.close()
loaded_model = model_from_json(loaded_model_json)
#load weights into new model
loaded_model.load_weights("model.h5")
print("Loaded model from disk")
# 重新编译了模型,保存为loaded_model
# evaluate loaded model on test data
sgd = SGD(0.01)
loaded_model.compile(loss="categorical_crossentropy", optimizer=sgd,
metrics=["accuracy"])
#score = loaded_model.evaluate(X,Y, verbose=0)
# 这个文件夹保存了我的手写数字图片,是用win7的画图软件画的
path1 = '/home/xxjian/Workspace_Python/myTest/'
files = os.listdir(path1)
# 读取了文件夹中的每一个文件,把每个文件(28x28)像素的黑白文件,各自转换为(1x784)。并将它们组合成(nx784)的一个样本参数矩阵
Cnt = 0
for file in files:
if not os.path.isdir(file):
f = os.path.basename(file)
print(f)
Cnt +=1
image2d = cv2.imread(path1+f,cv2.IMREAD_GRAYSCALE)
image2d = cv2.resize(image2d, (28,28), interpolation = cv2.INTER_AREA)
#cv2.imwrite(path1+f, image2d)
image1d = np.mat(np.zeros((1,784)))
cv2.imshow("image2d",image2d)
cv2.waitKey(0)
for i in range(28):
for j in range(28):
image1d[0,i*28+j] = image2d[i,j]
if Cnt ==1:
X_myTest = image1d
else:
X_myTest = np.vstack((X_myTest,image1d))
# 这里根据上面读取文件的顺序,自行输入了各个图片对应的真实之
# 本网络的输出层是有10个神经元的,对应着10个类别的不同数字(0-9)
Y_myTest = np.mat(np.zeros((Cnt,10),dtype=np.uint8))
Y_myTest[0,2] = 1
Y_myTest[1,4] = 1
Y_myTest[2,9] = 1
Y_myTest[3,6] = 1
Y_myTest[4,1] = 1
Y_myTest[5,3] = 1
Y_myTest[6,5] = 1
Y_myTest[7,8] = 1
Y_myTest[8,0] = 1
Y_myTest[9,7] = 1
score = loaded_model.evaluate(X_myTest,Y_myTest,verbose=0)
# convert the labels from integers to vectors
lb = LabelBinarizer()
Y_myTest = lb.fit_transform(Y_myTest)
predictions_1 = loaded_model.predict(X_myTest, batch_size=2)
# 这里把预测结果打印出来
print("predictions_1.argmax(axis=1) = {}".format(predictions_1.argmax(axis=1)))
# 生成报告
print(classification_report(Y_myTest.argmax(axis=1),
predictions_1.argmax(axis=1),
target_names=[str(x) for x in lb.classes_]))
我刚开始是不确定从数据集中的样品(28x28)转换为(1x784)的存放方式。dataset.data已经是个(70000x784)的二维矩阵。于是编了以下代码,读取了dataset.data,并转换为(28x28)显示出来。假如图像显示正确,那么即可知道(28x28)转(1x784)的方式。
3. keras_mnistSampleRead.py
# import the necessary packages
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from keras.models import Sequential
from keras.layers.core import Dense
from keras.optimizers import SGD
from sklearn import datasets
import matplotlib.pyplot as plt
import numpy as np
import argparse
import os
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-o", "--output", default="output/keras_mnist.png", #required=True,
help="path to the output loss/accuracy plot")
args = vars(ap.parse_args())
# grab the MNIST dataset (if this is your first time running this
# script, the download may take a minute -- the 55MB MNIST dataset
# will be downloaded)
print("[INFO] loading MNIST (full) dataset...")
path1 = os.path.dirname(os.path.abspath(__file__))
dataset = datasets.fetch_mldata("MNIST Original", data_home=path1)
while(1):
# 下面开始随机打开dataset.data中的样品
aRand= int(np.random.rand(1)[0]*dataset.data.shape[0])
sample1 = dataset.data[aRand,:]
# 新建一个空白的mat格式,mat格式可以用imshow显示
newMat = np.mat(np.zeros((28,28)),dtype=np.uint8)
for i in range(28):
for j in range(28):
newMat[i,j] = sample1[i*28+j]
cv2.imshow("mat",newMat)
cv2.waitKey(0)手写图片素材:
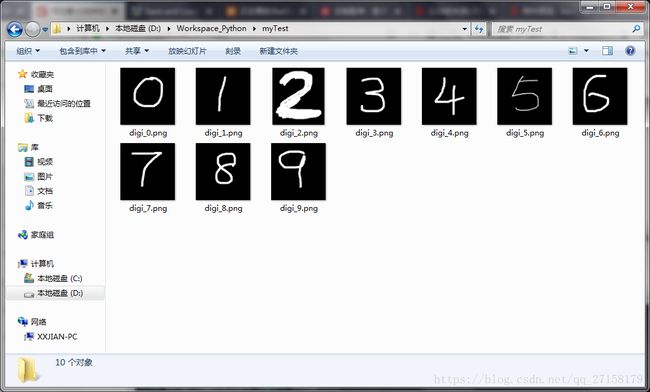
本工程文件夹的树形图:
│ keras_mnistMdlTest.py
│ keras_mnistMdlWriteLoad.py
│
├─mldata
│ mnist-original.mat
│
├─myTest
│ digi_0.png
│ digi_1.png
│ digi_2.png
│ digi_3.png
│ digi_4.png
│ digi_5.png
│ digi_6.png
│ digi_7.png
│ digi_8.png
│ digi_9.png
│
└─output
keras_mnistMdlTest.py 运行结果:
Loaded model from disk
digi_2.png
digi_4.png
digi_9.png
digi_6.png
digi_1.png
digi_3.png
digi_5.png
digi_8.png
digi_0.png
digi_7.png
predictions_1.argmax(axis=1) = [2 4 1 6 8 3 5 8 0 2]
Warning (from warnings module):
File "/home/xxjian/.local/lib/python3.6/site-packages/sklearn/metrics/classification.py", line 1135
'precision', 'predicted', average, warn_for)
UndefinedMetricWarning: Precision and F-score are ill-defined and being set to 0.0 in labels with no predicted samples.
precision recall f1-score support
0 1.00 1.00 1.00 1
1 0.00 0.00 0.00 1
2 0.50 1.00 0.67 1
3 1.00 1.00 1.00 1
4 1.00 1.00 1.00 1
5 1.00 1.00 1.00 1
6 1.00 1.00 1.00 1
7 0.00 0.00 0.00 1
8 0.50 1.00 0.67 1
9 0.00 0.00 0.00 1
avg / total 0.60 0.70 0.63 10结果平均只有0.6的精确度。主要原因是测试样品太少了,而且训练样品中,全部样品都没一个是我手写的。这样训练样品和测试样品有比较大的区别。果然还是没有捷径可走的。
参考资料
1、Keras模型的保存与读取参考了:https://machinelearningmastery.com/save-load-keras-deep-learning-models/
2、opencv-python中的缩放函数resize()用法参考了:https://www.jianshu.com/p/b5c29aeaedc7
3、Deep.Learning.for.Computer.Vision.with.Python.Starter.Bundle第十章Multi-layer Networks with Kares
4、如何保存Keras模型:https://blog.csdn.net/u010159842/article/details/54407745