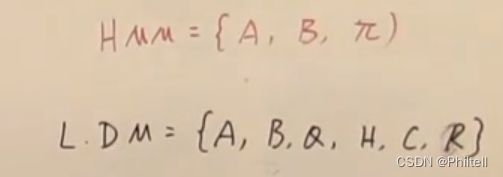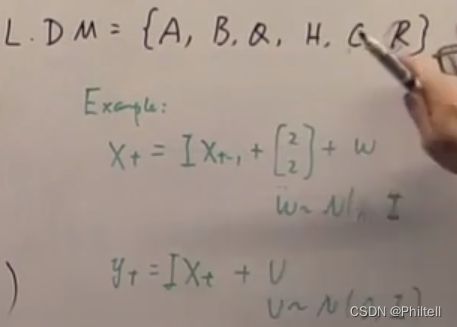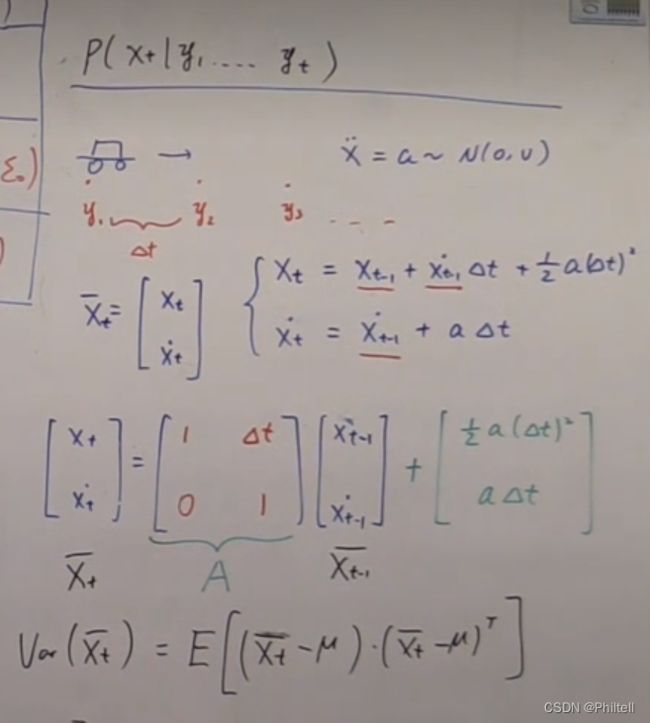《徐亦达机器学习:Kalman Filter 卡尔曼滤波笔记 (一)》

P ( x t P(x_t P(xt| x t − 1 ) x_{t-1}) xt−1) |
P ( y t P(y_t P(yt| x t ) x_t) xt) |
P ( x 1 ) P(x_1) P(x1) | |
|---|---|---|---|
| Discrete State DM | A X t − 1 , X t A_{X_{t-1},X_t} AXt−1,Xt | Any | π \pi π |
| Linear Gassian Kalman DM | N ( A X t − 1 + B , Q ) N(AX_{t-1}+B,Q) N(AXt−1+B,Q) | N ( H X t + C , R ) N(HX_t+C,R) N(HXt+C,R) | N ( μ 0 , ϵ 0 ) N(\mu_0,\epsilon_0) N(μ0,ϵ0) |
| No-Linear NoGaussian DM | f ( x t − 1 ) f(x_{t-1}) f(xt−1) | g ( y t ) g(y_t) g(yt) | f ( x 1 ) f(x_1) f(x1) |
{ P ( y 1 , . . . , y t ) − − e v a l u a t i o n a r g m e n t θ log P ( y 1 , . . . , y t ∣ θ ) − − p a r a m e t e r l e a r n i n g P ( x 1 , . . . , x t ∣ y 1 , . . . , y t ) − s t a t e d e c o d i n g P ( x t ∣ y 1 , . . , y t ) − f i l t e r i n g \left\{ \begin{aligned} P(y_1,...,y_t)--evaluation\\ argment \theta \log{P(y1,...,y_t|\theta)}--parameter learning \\ P(x_1,...,x_t|y_1,...,y_t)-state decoding \\ P(x_t | y_1,..,y_t)-filtering \end{aligned} \right. ⎩ ⎨ ⎧P(y1,...,yt)−−evaluationargmentθlogP(y1,...,yt∣θ)−−parameterlearningP(x1,...,xt∣y1,...,yt)−statedecodingP(xt∣y1,..,yt)−filtering
线性高斯噪声的动态模型
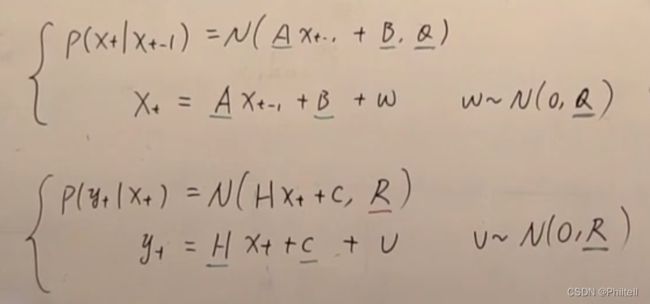
P ( x t ∣ y 1 , . . . , y t ) P(x_t|y_1,...,y_t) P(xt∣y1,...,yt)
假设转移概率是 P ( x t ∣ X t − 1 ) = N ( A X t − 1 + B , Q ) P(x_t|X_{t-1})= N(AX_{t-1}+B,Q) P(xt∣Xt−1)=N(AXt−1+B,Q)
X t = A X t − 1 + B + ω X_t = AX_{t-1}+B+\omega Xt=AXt−1+B+ω , ω ∼ N ( 0 , Q ) \omega \sim N(0,Q) ω∼N(0,Q)
measurement probility
P ( y t ∣ x t ) = N ( H X t + C , R ) P(y_t|x_t) = N(HX_t+C,R) P(yt∣xt)=N(HXt+C,R)
y t = H X t + C + v y_t = HX_t+C+v yt=HXt+C+v
v ∼ N ( 0 , R ) v \sim N(0,R) v∼N(0,R)
以下都是参数。