正则表达式
正则表达式,用标准正则解析,一般会把HTML当做普通文本,用指定格式匹配当相关文本,适合小片段文本,或者某一串字符(比如电话号码、邮箱账户),或者HTML包含javascript的代码,无法用CSS选择器或者XPath
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个"规则字符串",这个"规则字符串"用来表达对字符串的一种过滤逻辑。
1、正则表达式常见概念
- 边界匹配
^ — 与字符串开始的地方匹配,不匹配任何字符;
$ — 与字符串结束的地方匹配,不匹配任何字符;
str = "cat abdcatdetf ios"
^cat : 验证该行以c开头紧接着是a,然后是t
ios$ : 验证该行以t结尾倒数第二个字符为a倒数第三个字符为c
^cat$: 以c开头接着是a->t然后是行结束:只有cat三个字母的数据行
^$ : 开头之后马上结束:空白行,不包括任何字符
^ : 行的开头,可以匹配任何行,因为每个行都有行开头
\b — 匹配一个单词边界,也就是单词和空格之间的位置,不匹配任何字符;
"er\b"可以匹配"never"中的"er",但不能匹配"verb"中的"er"。
\B — \b取非,即匹配一个非单词边界;
"er\B"能匹配"verb"中的"er",但不能匹配"never"中的"er"。
- 数量词的贪婪模式与非贪婪模式
正则表达式通常用于在文本中查找匹配的字符串。Python里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字符;非贪婪的则相反,总是尝试匹配尽可能少的字符。例如:
正则表达式"ab*"如果用于查找"abbbc",将找到"abbb"。而如果使用非贪婪的数量词"ab*?",将找到"a"。
- 反斜杠问题
与大多数编程语言相同,正则表达式里使用""作为转义字符,这就可能造成反斜杠困扰。
假如你需要匹配文本中的字符"“,那么使用编程语言表示的正则表达式里将需要4个反斜杠”\":前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。
Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r""表示。
同样,匹配一个数字的"\d"可以写成r"\d"。有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。
import re
a=re.search(r"\\","ab123bb\c")
print a.group()
\
a=re.search(r"\d","ab123bb\c")
print a.group()
1
2、Python Re模块
Python 自带了re模块,它提供了对正则表达式的支持。
match函数
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
下面是此函数的语法:
re.match(pattern, string, flags=0)
这里的参数的说明:

匹配成功re.match方法返回一个匹配的对象,否则返回None。
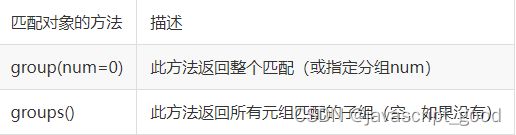
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
案例
#!/usr/bin/python
import re
line = "Cats are smarter than dogs"
matchObj = re.match( r'(.*) are (.*?) .*', line, re.M|re.I)
if matchObj:
print "matchObj.group() : ", matchObj.group()
print "matchObj.group(1) : ", matchObj.group(1)
print "matchObj.group(2) : ", matchObj.group(2)
else:
print "No match!!"
当执行上面的代码,它产生以下结果:
matchObj.group() : Cats are smarter than dogs
matchObj.group(1) : Cats
matchObj.group(2) : smarter
正则表达式修饰符 - 选项标志
正则表达式字面可以包含一个可选的修饰符来控制匹配的各个方面。修饰符被指定为一个可选的标志。可以使用异或提供多个修饰符(|),如先前所示,并且可以由这些中的一个来表示:

3、findall()函数
re.findall(pattern, string, flags=0)
返回字符串中所有模式的非重叠的匹配,作为字符串列表。该字符串扫描左到右,并匹配返回的顺序发现
默认:
pattren = "\w+"
target = "hello world\nWORLD HELLO"
re.findall(pattren,target)
['hello', 'world', 'WORLD', 'HELLO']
re.I:
re.findall("world", target,re.I)
['world', 'WORLD']
re.S:
re.findall("world.WORLD", target,re.S)
["world\nworld"]
re.findall("hello.*WORLD", target,re.S)
['hello world\nWORLD']
re.M:
re.findall("^WORLD",target,re.M)
["WORLD"]
re.X:
reStr = '''\d{3} #区号
-\d{8}''' #号码
re.findall(reStr,"010-12345678",re.X)
["010-12345678"]
4、search函数
re.search 扫描整个字符串并返回第一个成功的匹配。
下面是此函数语法:
re.search(pattern, string, flags=0)
这里的参数说明:

匹配成功re.search方法返回一个匹配的对象,否则返回None。
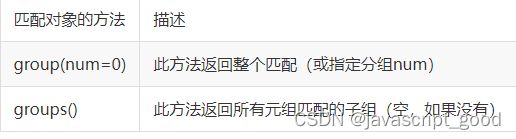
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
案例
#!/usr/bin/python
import re
line = "Cats are smarter than dogs";
searchObj = re.search( r'(.*) are (.*?) .*', line, re.M|re.I)
if searchObj:
print "searchObj.group() : ", searchObj.group()
print "searchObj.group(1) : ", searchObj.group(1)
print "searchObj.group(2) : ", searchObj.group(2)
else:
print "Nothing found!!"
当执行上面的代码,它产生以下结果:
matchObj.group() : Cats are smarter than dogs
matchObj.group(1) : Cats
matchObj.group(2) : smarter
re.match与re.search的区别
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配。
例子:
#!/usr/bin/python
import re
line = "Cats are smarter than dogs";
matchObj = re.match( r'dogs', line, re.M|re.I)
if matchObj:
print "match --> matchObj.group() : ", matchObj.group()
else:
print "No match!!"
searchObj = re.search( r'dogs', line, re.M|re.I)
if searchObj:
print "search --> searchObj.group() : ", searchObj.group()
else:
print "Nothing found!!"
当执行上面的代码,产生以下结果:
No match!!
search --> matchObj.group() : dogs
5、搜索和替换
Python 的re模块提供了re.sub用于替换字符串中的匹配项。
语法
re.sub(pattern, repl, string, max=0)
返回的字符串是在字符串中用 RE 最左边不重复的匹配来替换。如果模式没有发现,字符将被没有改变地返回。可选参数 count 是模式匹配后替换的最大次数;count 必须是非负整数。缺省值是 0 表示替换所有的匹配。实例:
例子
下面是一个爬虫做翻页面例子:
#!/usr/bin/python
import re
url = "http://hr.tencent.com/position.php?&start=10"
page = re.search('start=(\d+)',url).group(1)
nexturl = re.sub(r'start=(\d+)', 'start='+str(int(page)+10), url)
print "Next Url : ", nexturl
当执行上面的代码,产生以下结果:
Next Url : http://hr.tencent.com/position.php?&start=20