chatGPT笔记
文章目录
- 一、GPT之技术演进时间线
- 二、chatGPT中的语言模型instructGPT跟传统语言LM模型最大不同点是什么?
- 三、instructGPT跟GPT-3的网络结构是否一样
- 四、GPT和BERT有啥区别
- 五、chatGPT的训练过程是怎样的?
- 六、GPT3在算数方面的能力
- 七、GPT相比于bert的优点是什么
- 八、元学习(meta-learning)是什么
- 九、chatGPT的优缺点
- 十一、chatGPT与人体结构
-
- 1. chatGPT离完全的人类智能还有多少距离
- 2. 人类历史上曾出现类似chatGPT的病人,只有某个时间点以前的记忆
- 十二、chatGPT的输入有长度限制,怎么办
- 十三、基于人类反馈的强化学习(Reinforcement Learning with Human Feedback,RLHF)
- 十四、什么是LoRA训练
- 十四、目前已有的大规模参数训练框架
- 十五、如何选取基座模型
- 十四、只有cpu的机器,如何满足离线部署需求
- 十五、如何补足LLM的记忆能力
- 十六、如何制作"针对某个pdf的问答机器人"
- 十六、开源项目
-
- 1. RLHF的开源实现
- 2. 目前复现水平最接近chatGPT的开源模型是Vicuna
- 3. 其他
- 参考文献
- 待阅读
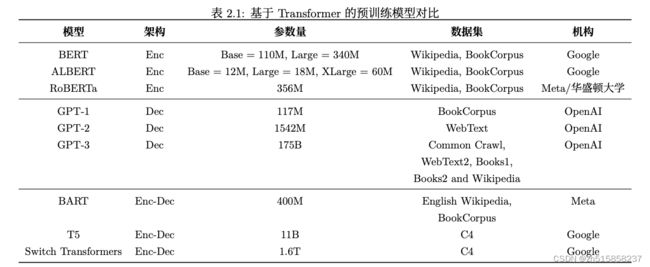
一、GPT之技术演进时间线
GPT从开始至今,其发展历程如下:
- 【Transformer模型】:
2017年6月,Google发布论文《Attention is all you need》,首次提出Transformer模型,成为GPT发展的基础。 论文地址 - 【GPT模型】:
2018年6月,OpenAI 发布论文《Improving Language Understanding by Generative Pre-Training》(通过生成式预训练提升语言理解能力),首次提出GPT模型(Generative Pre-Training)。 - 【GPT2模型】:
2019年2月,OpenAI 发布论文《Language Models are Unsupervised Multitask Learners》(语言模型应该是一个无监督多任务学习者),GPT2更加侧重于 Zero-shot 设定下语言模型的能力。GPT-2使用了与 GPT-1相同的模型和架构,在 GPT-1的基础上引入任务相关信息作为输出预测的条件,将 GPT-1 中的条件概 率 p(output|input) 变为 p(output|input; task);并继续增大训练的数据规模 以及模型本身的参数量,最终在 Zero-shot 的设置下对多个任务都展示了巨大的潜力。这样的思想事实上是在传达只要模型足够大,学到的知识足够多,任何有监督任务都可以通过无监督的方式来完成,即任何任务都可以视作生成任务。 - 【GPT3模型】:
2020年5月,OpenAI 发布论文《Language Models are Few-Shot Learners》(语言模型应该是一个少量样本(few-shot)学习者)。GPT-3使用了与GPT-2相同的模型和架构。GPT-3最显著的特点就是大。大体现在两方面,一方面是模型本身规 模大,参数量众多,具有 96 层 Transformer Decoder Layer,每一层有 96 个 128 维的注意力头,单词嵌入的维度也达到了12288;另一方面是训练过程中使用到的数据集规模大,达到了45TB。在这样的模型规模与数据量的情况下,GPT-3 在多个任务上均展现出了非常优异的性能,延续 GPT-2将无监督模型应用到有监督任务的思想,GPT-3在Few-shot,One-shot 和 Zero-shot 等设置下的任务表现都得到了显著的提升。 - 【Instruction GPT模型】:
2022年2月底,OpenAI 发布论文《Training language models to follow instructions with human feedback》(使用人类反馈指令流来训练语言模型),公布Instruction GPT模型。 - 【ChatGPT模型】:
2022年11月30日,OpenAI推出ChatGPT模型,并提供试用,全网火爆。
二、chatGPT中的语言模型instructGPT跟传统语言LM模型最大不同点是什么?
目标不一样。传统语言模型主要是预测一句话中下一个词是什么。而instructGPT的目标是:follow the user’s instructions helpfully and safely
三、instructGPT跟GPT-3的网络结构是否一样
instructGPT跟GPT-3的网络结构是一样的,区别在于训练阶段的不同,instructGPT使用了标注数据进行fine-tune
四、GPT和BERT有啥区别
GPT 中训练的是单向语言模型,其实就是直接应用 Transformer Decoder;
Bert 中训练的是双向语言模型,应用了 Transformer Encoder 部分,不过在 Encoder 基础上还做了 Masked 操作;
BERT Transformer 使用双向 self-attention,而 GPT Transformer 使用受限制的 self-attention,其中每个 token 只能处理其左侧的上下文。
五、chatGPT的训练过程是怎样的?

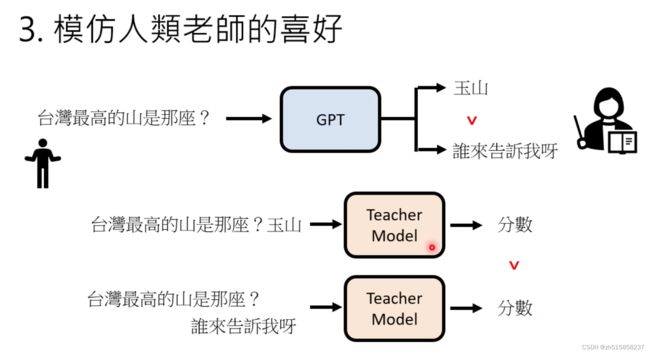
从InstructGPT论文里梳理“三步走”:
(1)SFT (监督指令微调,supervised fine tune):从5.4w人工标注的指令集中抽取1.3w,在GPT-3大模型上微调。也就是说从测试用户提交的 prompt 中随机抽取一批,靠专业的标注人员,给出指定 prompt 的高质量答案,然后用这些人工标注好的 < prompt,answer > 数据来 Fine-tune GPT 3.5 模型,从而让 GPT 3.5 初步具备理解指令中蕴含的意图的能力;
(2)RM(训练回报模型,reward model):基于新模型生成一批数据集
(3)PPO(采用强化学习来增强预训练模型的能力):利用上一阶段学好的 RM 模型,靠 RM 打分结果来更新预训练模型参数。RLHF的具体实现,RM奖励模型作为critic(评论家),SFT阶段的大模型作为actor(行动家),二者相互配合,actor学习指令集,critic评估打分,再更新权重,进入下一轮。论文里对比两种损失函数,后采用混合预训练损失PPT_ptx,兼顾预训练的效果。
六、GPT3在算数方面的能力
七、GPT相比于bert的优点是什么
GPT-3主要聚焦于更通用的NLP模型,解决当前BERT类模型的两个缺点:
- 对领域内有标签数据的过分依赖:虽然有了预训练+精调的两段式框架,但还是少不了一定量的领域标注数据,否则很难取得不错的效果,而标注数据的成本又是很高的。
- 对于领域数据分布的过拟合:在精调阶段,因为领域数据有限,模型只能拟合训练数据分布,如果数据较少的话就可能造成过拟合,致使模型的泛华能力下降,更加无法应用到其他领域。
因此GPT-3的主要目标是用更少的领域数据、且不经过精调步骤去解决问题。
八、元学习(meta-learning)是什么
对于一个少样本的任务来说,模型的初始化值非常重要,从一个好的初始化值作为起点,模型能够尽快收敛,使得到的结果非常快的逼近全局最优解。元学习的核心思想在于通过少量的数据寻找一个合适的初始化范围,使得模型能够在有限的数据集上快速拟合,并获得不错的效果。
九、chatGPT的优缺点
chatGPT有很强的归纳能力和泛化记忆能力。但是在推演和演绎方面,超大规模语言模型在符号推理、输出可控和可解释方面还较弱,并且容易犯事实性错误。
例如,你问刘德华的电影有哪些,但是chatGPT却返回一堆周星驰或者其他人的电影
十一、chatGPT与人体结构
1. chatGPT离完全的人类智能还有多少距离
人类大脑有860亿神经元、100-1000万亿联接,能处理的任务也远远超过GPT-3。如果一个联接就相当于有一个参数,那么粗略估计人脑可能可以通过100-1000万亿的模型参数来模拟,目前的chatGPT的1750亿参数看来,参数规模还需要再扩大571倍至5710倍。
当然,这并不意味着只要参数规模扩大这么多倍,就一定能实现完全的人类智能。
2. 人类历史上曾出现类似chatGPT的病人,只有某个时间点以前的记忆
1953年,Henry Molaison 因为饱受癫痫症带来的痛苦,接受了一种实验性的手术。这次手术让他成为神经科学家们最耳熟能详的病人。
手术切除了他部分内侧颞叶,包括海马体,这些区域在当时被认为与癫痫发作有关。术后,身边的医护人员发现 Henry 的记忆就像沙滩上的字,时间的海水一冲就会消失,无法形成新的记忆;同时,他对以前发生的事情、语言中每个词语的意义、理解和发音记得一清二楚。也就是说,海马体的缺失使他的记忆永远停留在了手术那一天。
对于人类这种智能体,记忆似乎是与生俱来的能力;而如果把 ChatGPT 类的大语言模型比作大脑,其天然就缺失了形成记忆能力的海马体。在大模型中,世界知识和语义理解被压缩为了静态的参数,模型不会随着交互记住我们的聊天记录和喜好,也不会调用额外的知识信息来辅助自己的判断。
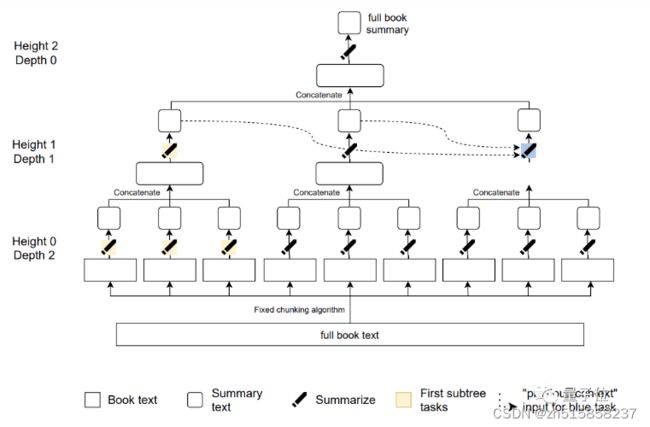
十二、chatGPT的输入有长度限制,怎么办
AI分四个阶段来总结:比如这样一段121567词的《傲慢与偏见》原文:
先把原文总结成276个摘要(24796词),然后进一步压缩成25个摘要(3272词),再到4个摘要(475词)。
最终得到一段175词的摘要,长度只有原片段的千分之一:
十三、基于人类反馈的强化学习(Reinforcement Learning with Human Feedback,RLHF)
【奖励模型训练】 该阶段旨在获取拟合人类偏好的奖励模型。奖励模型以提示和回复作为输入,计算标量奖励值作为输出。奖励模型的训练过程通过拟合人类对于不同回复的倾向性实现。具体而言,首先基于在人类撰写数据上精 调的模型,针对同一提示采样多条不同回复。然后,将回复两两组合构成一 条奖励模型训练样本,由人类给出倾向性标签。最终,奖励模型通过每条样本中两个回复的奖励值之差计算倾向性概率拟合人类标签
【生成策略优化】 给定习得的奖励模型,ChatGPT/InstructGPT 的参数将被 视为一种策略,在强化学习的框架下进行训练。首先,当前策略根据输入的查询采样回复。然后,奖励模型针对回复的质量计算奖励,反馈回当前策略用以更新。值得注意的是,为防止上述过程的过度优化,损失函数同时引入了词级别的 KL 惩罚项。
十四、什么是LoRA训练
LoRA: Low-Rank Adaptation of Large Language Models 是微软研究员引入的一项新技术,主要用于处理大模型微调的问题。目前超过数十亿以上参数的具有强能力的大模型 (例如 GPT-3) 通常在为了适应其下游任务的微调中会呈现出巨大开销。LoRA 建议冻结预训练模型的权重并在每个 Transformer 块中注入可训练层 (秩-分解矩阵)。因为不需要为大多数模型权重计算梯度,所以大大减少了需要训练参数的数量并且降低了 GPU 的内存要求。研究人员发现,通过聚焦大模型的 Transformer 注意力块,使用 LoRA 进行的微调质量与全模型微调相当,同时速度更快且需要更少的计算。
十四、目前已有的大规模参数训练框架
目前,已经公布明确已经完成 千亿参数规模大模型训练的框架主要是 NVIDIA 开发的 Megatron-LM 、经 过微软深度定制开发的DeepSpeed、国产百度飞浆 PaddlePaddle 和华为昇思 MindSpore。大多数并行框架都支持 PyTorch 分布式训练,可以完成百亿参数规模的模型训练。
十五、如何选取基座模型
有论文(The Practical Guides for Large Language Models)按照模型结构整理了大模型的进化树
Encoder-Only结构:BERT系列
Decoder-Only结构:GPT系列,成员最多
Encoder-Decoder结构:BART、T5、GLM
 图源:https://github.com/Mooler0410/LLMsPracticalGuide/blob/main/imgs/qr_version.jpg
图源:https://github.com/Mooler0410/LLMsPracticalGuide/blob/main/imgs/qr_version.jpg
其中开源模型尤为“耀眼”,拿来就用。
GPT-2:完全开源,适合自己升级架构到GPT-3,并加上RLHF流程,照着OpenAI趟出来的路再走一遍。
BLOOM:完全开源,2022年7月,法国BigScience开源的GPT-3级别LLM,176b,覆盖46种语言和13种编程语言,中文语料占比高达16%,仅次于英文的30%
OPT:2022年5月,META AI开源,175b。英文为主,中文不佳。只能科研,不能商用。
LLaMA:2023年2月25日,META基于OPT微调出一个用于聊天的大模型,7b~65b, 依旧英文为主,非商用,
GPT-Neo、GPT-J和GPT-NeoX:开源,英语为主。源自一个富有极客反叛精神的全球开源组织 EleutherAI,既然OpenAI colsed了,为地主独占,那就揭竿而起,自己做真正的开源。
GLM:清华发布,亚洲唯一上榜的175b级别LLM,中文版的ChatGLM商用受限。
LLM看着很多,但完全开源的屈指可数,这让准备商用的研发人员头疼不已。
十四、只有cpu的机器,如何满足离线部署需求
https://github.com/nomic-ai/gpt4all
https://github.com/antimatter15/alpaca.cpp
十五、如何补足LLM的记忆能力
我们认为目前的LLM相当于没有记忆能力的大脑,而向量数据库是补足这一能力的海马体。其实调用向量数据库的过程,比较像人类死记硬背使用短期记忆的方式。因为当我们进入某一领域时,会首先根据一些知识与过来人的经验依葫芦画瓢,然后随着自己的试错和经验积累慢慢形成自己的直觉、风格和行为习惯,直到那时我们才成为这一领域的专家。而向量数据库(比如Pinecone),只实现了依葫芦画瓢的那一步。
换言之,从人类智能的角度看,向量数据库是短期记忆,LLM 是长期记忆,但目前他们之间的交互还是单向的,缺少了短期记忆累积沉淀,形成长期记忆的过程。但直接去调整大模型的参数是不太可行的。因此这一过程可能需要一些新的组件来弥补,例如一个基于 Lora 进行微调的小模型,来帮助大模型做一些领域专业知识的记忆;也或者是由多个 LLM 交互形成群体记忆,来达到更新长期记忆的效果。
十六、如何制作"针对某个pdf的问答机器人"
推荐国外已经很火的chatpdf网站https://www.chatpdf.com/

chain 的 chain_type 参数
这个参数主要控制了将 document 传递给 llm 模型的方式,一共有 4 种方式:
stuff: 这种最简单粗暴,会把所有的 document 一次全部传给 llm 模型进行总结。如果document很多的话,势必会报超出最大 token 限制的错,所以总结文本的时候一般不会选中这个。
map_reduce: 这个方式会先将每个 document 进行总结,最后将所有 document 总结出的结果再进行一次总结。
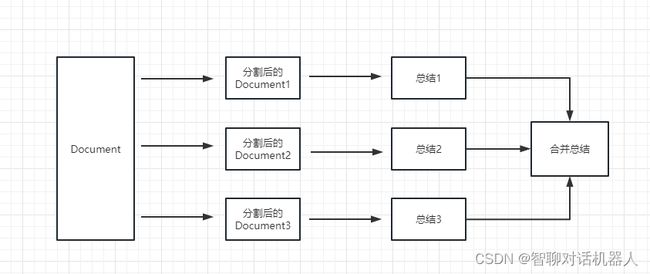
refine: 这种方式会先总结第一个 document,然后在将第一个 document 总结出的内容和第二个 document 一起发给 llm 模型在进行总结,以此类推。这种方式的好处就是在总结后一个 document 的时候,会带着前一个的 document 进行总结,给需要总结的 document 添加了上下文,增加了总结内容的连贯性。
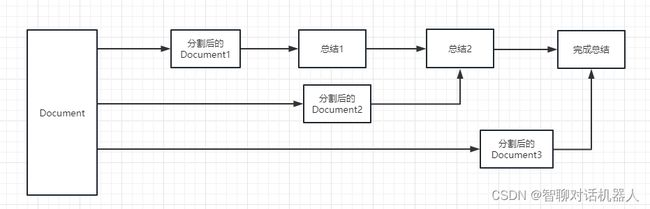
map_rerank: 这种一般不会用在总结的 chain 上,而是会用在问答的 chain 上,他其实是一种搜索答案的匹配方式。首先你要给出一个问题,他会根据问题给每个 document 计算一个这个 document 能回答这个问题的概率分数,然后找到分数最高的那个 document ,在通过把这个 document 转化为问题的 prompt 的一部分(问题+document)发送给 llm 模型,最后 llm 模型返回具体答案。
十六、开源项目
1. RLHF的开源实现
https://github.com/lucidrains/PaLM-rlhf-pytorch
https://github.com/AI4Finance-Foundation/FinGPT 金融领域的GPT模型(优势:应用了RLHF)
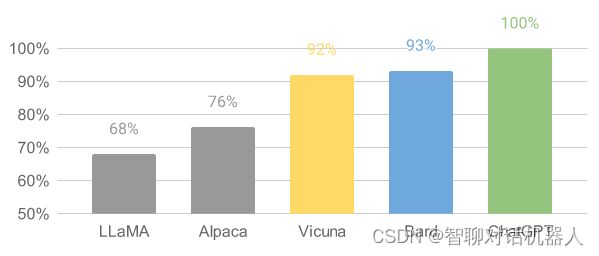
2. 目前复现水平最接近chatGPT的开源模型是Vicuna
https://github.com/lm-sys/FastChat
Vicuna 在总分上达到了 ChatGPT 的 92%
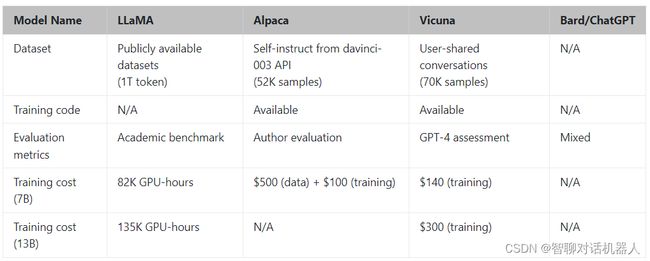
下面是LLaMA、Alpaca、Vicuna几个模型的差别
3. 其他
ChatGPT的核心模块包括SFT、RM、RLHF三个,当前的很多工作主要集中在复现SFT模块,只有ColossalChat 目前复现了SFT+RM+RLHF整个流程
1.1. 算法工作
| 项目 | 模块 | 备注 |
|---|---|---|
| LLaMA | 基础 | 提供了一个pre-train的backbone |
| Alpaca | SFT模块 | 基于self-instruct技术,做了指令微调 instruction fine-tune |
| Alpaca-Lora | SFT模块 | 利用LoRa技术,大大减少了需要微调的参数量 |
| Vicuna | SFT模块 | 目前最接近chatGPT的模型 |
| LMFlow | SFT模块 | 基于 70 亿参数的 LLaMA,只需 1 张 3090、耗时 5 小时,就可定制自己的GPT并完成网页端部署 |
| ColossalChat | 提供了SFT+RM+RLHF整个流程 | 无 |
1.2. 数据集
| 项目 | 备注 |
|---|---|
| AlpacaDataCleaned | 对Alpaca提供的52k数据进行了进一步清理 |
| Alpaca-CoT | 加入了思维链chain-of-thought数据 |
| InstructionWild | colossalChat开放的数据集 |
| shareGPT | 一个 ChatGPT 数据共享网站,用户会上传自己觉得有趣的 ChatGPT 回答。 |
1.3. 有限资源下的部署
llama.cpp
alpaca.cpp
参考文献
- https://www.51cto.com/article/743197.html
- https://wqw547243068.github.io/gpt#nanogpt
- Training langeuage models to follow instructions with human feedback
- https://www.inside.com.tw/article/30032-chatgpt-possible-4-steps-training
- https://www.youtube.com/watch?v=e0aKI2GGZNg&t=1074s (李宏毅讲解chatGPT)
- https://www.youtube.com/watch?v=DOG1L9lvsDY (李宏毅讲解GPT3)
- https://www.zhihu.com/question/398114261
- https://mp.weixin.qq.com/s/CwYb1uLnzrz7s9jXeqSynw (产生事实性错误“幻觉”的原因)
- https://www.youtube.com/watch?v=t70Bl3w7bxY (强烈推荐李沐大神的youtube视频)
- https://cloud.tencent.com/developer/article/1883747 (解决长文本输入的问题)
- https://mp.weixin.qq.com/s/gq42DajNV0QvEZ_qg6iR4Q
- https://github.com/sunlylorn/llm-pitfall-compass (孙林写的踩坑之旅)
- https://huggingface.co/blog/zh/lora
- https://36kr.com/p/2233027665457281 (人类历史上曾出现类似chatGPT的病人,只有某个时间点以前的记忆)
- https://mp.weixin.qq.com/s?__biz=Mzg2OTY0MDk0NQ==&mid=2247501117&idx=1&sn=e860ac5e259a969f62b05d080bf42d14&chksm=ce9b7aa3f9ecf3b503656e9a09b55210fdba0844b54bd6a5714f5fc8c57b8c3570acbe2d342f&scene=21#wechat_redirect (pdf问答机器人解决方案)
- https://liaokong.gitbook.io/llm-kai-fa-jiao-cheng/ (构建本地知识库问答机器人)
- https://docs.kanaries.net/tutorials/ChatGPT/FinGPT
待阅读
- https://docs.cohere.ai/docs/prompt-engineering (prompt讲解比较好的文章)
- http://jalammar.github.io/how-gpt3-works-visualizations-animations/ (GPT3讲解比较好的文章)
- http://jalammar.github.io/illustrated-gpt2/ (讲解GPT2的文章)
- https://hub.baai.ac.cn/view/23596 (独立人工智能开发者开源自己的ChatGPT训练算法实现)
- https://mp.weixin.qq.com/s/2NZeK_HitLQsRtb9xp1jtQ
- https://mp.weixin.qq.com/s/Vv45QCU_rGEeU8IHBrIBcQ
- https://mp.weixin.qq.com/s/ZgZln_o6VJCrkjnvqcOlsA
- https://mp.weixin.qq.com/s/ct2qXDXnaB5_9QfNkS_sKA
- https://zhuanlan.zhihu.com/p/606478660
- https://cloud.tencent.com/developer/article/2057536