Ceph入门到精通-S3 基准测试工具warp使用入门
S3 基准测试工具。
下载
下载适用于各种平台的二进制版本。
配置
可以使用命令行参数或环境变量配置 Warp。 可以使用 、 在命令行上指定要使用的 S3 服务器,也可以选择指定 TLS 和自定义区域。--host--access-key--secret-key--tls--region
也可以使用 、、 和环境变量设置相同的参数。WARP_HOSTWARP_ACCESS_KEYWARP_SECRET_KEYWARP_REGIONWARP_TLS
凭证必须能够创建、删除和列出存储桶以及上传文件并执行请求的操作。
默认情况下,操作在名为 的存储桶上执行。 这可以使用参数进行更改。 但请注意,每次运行前后都会彻底清洁铲斗, 所以它不应该包含任何数据。warp-benchmark-bucket--bucket
如果您运行的是 TLS, 您可以使用 启用对象的服务器端加密。将生成一个随机键并用于对象。 要使用 SSE-S3 加密,请使用标志。--encrypt--sse-s3-encrypt
用法
warp command [options]
使用提供的密钥对端口 8 上命名为 的 9000 台服务器运行混合类型基准测试的示例:s3-server-1s3-server-8
warp mixed --host=s3-server{1...8}:9000 --access-key=minio --secret-key=minio123 --autoterm
这将运行基准测试长达 5 分钟并打印结果。
基准
所有基准测试同时运行。默认情况下,将同时运行 20 个操作。 但是,也可以使用该参数进行调整。--concurrent
调整并发性可能会影响性能,尤其是在测试服务器延迟时。 大多数基准测试还将为每个运行的“线程”使用不同的前缀。
默认情况下,所有基准测试将所有请求详细信息保存到名为 的文件中。 可以使用参数指定自定义文件名。 原始数据是zstandard压缩的CSV数据。warp-operation-yyyy-mm-dd[hhmmss]-xxxx.csv.zst--benchdata
多个主机
可以将多个 S3 主机指定为逗号分隔值,例如将在指定的服务器之间切换。--host=10.0.0.1:9000,10.0.0.2:9000
或者,可以指定数字范围,使用它将通过 .此语法可用于主机名和端口的任何部分。--host=10.0.0.{1...10}:900010.0.0.110.0.0.10
默认情况下,在运行请求数最少的主机之间选择一个主机 并且自上次请求完成以来时间最长。这将确保在以下情况下 主机以不同的速度运行,最快的服务器将获得最多的请求。 可以使用参数选择简单的轮循机制算法。 如果只有一个主机,则此参数不起作用。--host-select=roundrobin
当每个主机完成基准时,将打印出平均值。 有关更多详细信息,也可以使用该参数。--analyze.v
分布式基准测试

可以自动协调多个扭曲实例。 这对于同时从多个客户端测试群集的性能非常有用。
对于可靠的基准测试,客户端应具有同步时钟。 Warp 检查时钟是否在服务器的一秒内, 但理想情况下,时钟应与 NTP 或类似服务同步。
要使用 Kubernetes,请参阅在 kubernetes 上运行 warp。
客户端设置
警告:切勿在公开的端口上运行 warp 客户端。客户端有可能使用DDOS任何服务。
客户端从
warp client [listenaddress:port]
warp client仅接受要侦听的可选主机/ip,否则不接受特定参数。 默认情况下,扭曲将侦听 。127.0.0.1:7761
一次只能连接一台服务器。 但是,当一个基准测试完成后,客户端可以立即运行另一个具有不同参数的基准测试。
将进行版本检查以确保客户端与服务器兼容, 但始终建议保持 Warp 版本相同。
服务器设置
任何基准测试都可以在服务器模式下运行。 当 warp 作为服务器调用时,不会在服务器上进行实际的基准测试。 每个客户端将执行基准测试。
服务器将协调基准测试运行并确保它们正确运行。
基准测试完成后,将收集、合并和保存/显示组合的基准测试信息。 每个客户端还将在本地保存自己的数据。
启用服务器模式是通过添加或逗号分隔的 warp 客户端主机列表来完成的。 如果未指定主机端口,则添加默认值。--warp-client=client-{1...10}:7761
例:
warp get --duration=3m --warp-client=client-{1...10} --host=minio-server-{1...16} --access-key=minio --secret-key=minio123
请注意,参数适用于每个客户端。 因此,如果指定,每个客户端将以 8 个并发操作运行。 如果 warp 服务器无法连接到客户端,则整个基准测试将中止。--concurrent=8
如果 warp 服务器在基准测试运行期间失去与客户端的连接,则会出错 显示,服务器将尝试重新连接。 如果服务器无法重新连接,基准测试将继续使用其余客户端。
手动分布式基准测试
虽然强烈建议使用自动分布式基准测试翘曲也可以 一次在多台计算机上手动运行。
在多个客户端上运行基准测试时,可以同步 使用参数开始时间。 时间格式为“hh:mm”,其中小时以 24h 格式指定, 并解析为本地计算机时间。--syncstart
使用此方法将使合并来自客户端的基准测试以获得总结果变得更加可靠。 这将合并数据,就像在同一客户端上运行一样。 仅考虑实际重叠的时间段。
在多个客户端上运行基准测试时,最好指定参数 因此,客户端不会在启动时意外删除彼此的数据。--noclear
基准数据
默认情况下,warp 会上传随机数据。
对象大小
大多数基准测试使用该参数来确定要上传的对象的大小。--obj.size
不同的基准测试类型将具有不同的默认值。
随机文件大小
可以通过指定来随机化对象大小,文件将具有最大 . 但是,有一些事情需要考虑“引擎盖下”。--obj.randsize--obj.size
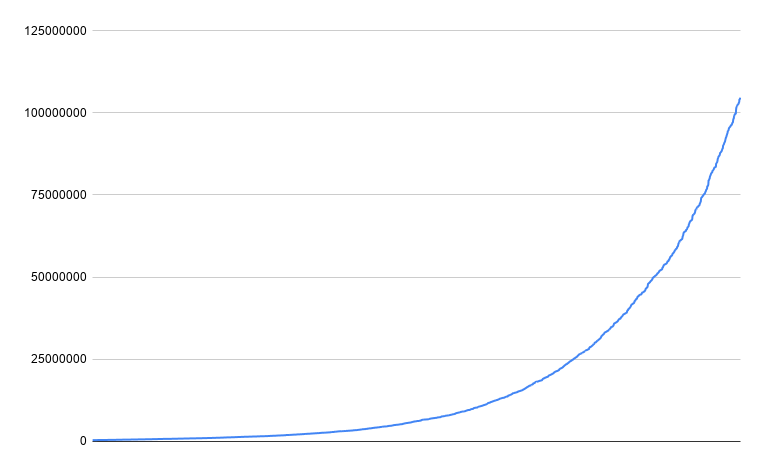
我们使用 log2 来分配对象大小。 这意味着对于大小的每增加一倍,对象将以相等的数量分布。 这意味着 -> 将具有与 -> 相同数量的对象。obj.size/64obj.size/32obj.size/2obj.size
对象(水平)及其大小示例,最大 100MB:
要查看分段的请求统计信息,请使用该参数。--analyze.v
λ warp analyze --analyze.op=GET --analyze.v warp-get-2020-08-18[190338]-6Nha.csv.zst
Operation: GET (78188). Concurrency: 32.
Requests considered: 78123. Multiple sizes, average 1832860 bytes:
Request size 1 B -> 10 KiB. Requests - 10836:
* Throughput: Average: 1534.6KiB/s, 50%: 1571.9KiB/s, 90%: 166.0KiB/s, 99%: 6.6KiB/s, Fastest: 9.7MiB/s, Slowest: 1124.8B/s
* First Byte: Average: 3ms, Median: 2ms, Best: 1ms, Worst: 39ms
Request size 10KiB -> 1MiB. Requests - 38219:
* Throughput: Average: 73.5MiB/s, 50%: 66.4MiB/s, 90%: 27.0MiB/s, 99%: 13.6MiB/s, Fastest: 397.6MiB/s, Slowest: 3.1MiB/s
* First Byte: Average: 3ms, Median: 2ms, Best: 1ms, Worst: 41ms
Request size 1MiB -> 10MiB. Requests - 33091:
* Throughput: Average: 162.1MiB/s, 50%: 159.4MiB/s, 90%: 114.3MiB/s, 99%: 80.3MiB/s, Fastest: 505.4MiB/s, Slowest: 22.4MiB/s
* First Byte: Average: 3ms, Median: 2ms, Best: 1ms, Worst: 40ms
Throughput:
* Average: 4557.04 MiB/s, 2604.96 obj/s (29.901s, starting 19:03:41 CEST)
Throughput, split into 29 x 1s:
* Fastest: 4812.4MiB/s, 2711.62 obj/s (1s, starting 19:03:41 CEST)
* 50% Median: 4602.6MiB/s, 2740.27 obj/s (1s, starting 19:03:56 CEST)
* Slowest: 4287.0MiB/s, 2399.84 obj/s (1s, starting 19:03:53 CEST)
平均对象大小将接近乘以 0.179151。--obj.size
要获取一个值,请将所需的平均对象大小乘以 5.582 以获得最大值。--obj.size
自动终止
添加参数将在结果稳定时启用自动终止。 为了检测稳定的设置,翘曲不断对当前数据进行下采样 25个数据点延伸至当前时间范围。--autoterm
要使基准被视为“稳定”,7 个数据点中的最后 25 个必须在指定的百分比内。 查看一段时间内的吞吐量,它可能如下所示:

红框显示用于评估稳定性的窗口。 盒子的高度由当前速度的阈值百分比决定。 此百分比可由用户通过 进行配置,默认为 7.5%。 用于此目的的指标为 MiB/s 或 obj/s,具体取决于基准类型。--autoterm.pct
为了确保有良好的样本数据,设置了 7 个样本中的 25 个样本的最短持续时间。 这是可配置的。这指定了基准测试必须稳定的最小时间长度。--autoterm.dur
如果基准测试没有自动终止,它将一直持续到达到持续时间为止。 当基准测试远程运行时,不能使用此功能。
吞吐量的永久“漂移”将防止自动终止, 如果漂移大于指定的百分比。 这是设计使然,因为应该记录下来。
使用自动终止时,请注意不应比较平均速度, 因为基准测试运行的长度可能会有所不同。 相反,50% 的中位数是一个更好的指标。
混合
混合模式基准测试将一次测试多种操作类型。 基准测试将上传大小的对象,并将这些对象用作基准测试的池。 上传/删除新对象时,将从池中添加/删除这些对象。--objects--obj.size
可以使用 、 和参数调整操作的分布。
最终分布将由总数中每个值的分数决定。 请注意,必须大于或等于 ,最终不会用完对象。
若要禁用类型,请将其分布设置为 0。--get-distrib--stat-distrib--put-distrib--delete-distribput-distrib--delete-distrib
例:
λ warp mixed --duration=1m
[...]
Mixed operations.
Operation: GET
* 632.28 MiB/s, 354.78 obj/s (59.993s, starting 07:44:05 PST) (45.0% of operations)
Operation: STAT
* 236.38 obj/s (59.966s, starting 07:44:05 PST) (30.0% of operations)
Operation: PUT
* 206.11 MiB/s, 118.23 obj/s (59.994s, starting 07:44:05 PST) (15.0% of operations)
Operation: DELETE
* 78.91 obj/s (59.927s, starting 07:44:05 PST) (10.0% of operations)
类似的基准称为对版本化对象进行操作的基准测试。versioned
获取
基准测试获取操作将尝试在 中下载尽可能多的对象。--duration
默认情况下,在执行实际工作台之前上传大小的对象。 对象将使用不同的前缀上传,除非指定了前缀。--objects--obj.size--concurrent--noprefix
使用将最多从存储桶中列出并下载它们 上传随机对象(将其设置为 0 以使用列表中的所有对象)。 列表仅限于如果已设置,并且可以通过设置禁用递归列表--list-existing--objects--prefix--list-flat
如果应该测试版本列表,可以通过设置(默认 1), 这将添加每个对象的多个版本并请求单独的版本。--versions=n
下载时,在所有上传的数据和基准测试之间随机选择对象 将尝试运行并发下载。--concurrent
分析将包括作为操作和操作的上传统计信息。PUTGET
Operation: GET
* Average: 94.10 MiB/s, 9866.97 obj/s
Throughput, split into 299 x 1s:
* Fastest: 99.8MiB/s, 10468.54 obj/s
* 50% Median: 94.4MiB/s, 9893.37 obj/s
* Slowest: 69.4MiB/s, 7279.03 obj/s
这些操作将包含接收第一个字节之前的时间。 这可以使用参数访问。GET--analyze.v
可以使用该选项测试部分文件请求的速度。 这将开始以随机偏移量读取每个对象并读取随机数量的字节。 使用此方法会产生类似于 - 的输出,甚至可以将它们组合在一起。--range--obj.randsize
放
基准测试放置操作将上传大小的对象,直到时间过去。--obj.size--duration
对象将使用不同的前缀上传,除非指定了前缀。--concurrent--noprefix
Operation: PUT
* Average: 10.06 MiB/s, 1030.01 obj/s
Throughput, split into 59 x 1s:
* Fastest: 11.3MiB/s, 1159.69 obj/s
* 50% Median: 10.3MiB/s, 1059.06 obj/s
* Slowest: 6.7MiB/s, 685.26 obj/s
通过使用该选项强制对数据进行 md5 校验和,可以实现。--md5
删除
基准删除操作将上传大小的对象并尝试 在 中尽可能多地删除 。--objects--obj.size--duration
删除操作在并发运行的请求中每个请求的对象中完成。--batch--concurrent
如果没有更多的对象,基准测试将结束。
分析将包括作为操作和操作的上传统计信息。PUTDELETE
Operation: DELETE
* Average: 10.06 MiB/s, 1030.01 obj/s
Throughput, split into 59 x 1s:
* Fastest: 11.3MiB/s, 1159.69 obj/s
* 50% Median: 10.3MiB/s, 1059.06 obj/s
* Slowest: 6.7MiB/s, 685.26 obj/s
列表
基准测试列表操作将上传带有前缀的大小对象。 列表操作是按前缀完成的。--objects--obj.size--concurrent
如果应该测试版本列表,可以通过设置(默认 1), 这将添加每个对象的多个版本并用于列表。--versions=NListObjectVersions
分析将包括作为操作的上传统计信息和单独的操作。 从请求开始到第一个对象的时间也会被记录下来,可以使用参数进行访问。PUTLIST--analyze.v
Operation: LIST
* Average: 10.06 MiB/s, 1030.01 obj/s
Throughput, split into 59 x 1s:
* Fastest: 11.3MiB/s, 1159.69 obj/s
* 50% Median: 10.3MiB/s, 1059.06 obj/s
* Slowest: 6.7MiB/s, 685.26 obj/s
统计
对统计信息对象操作进行基准测试 将上传带有前缀的大小对象。--objects--obj.size--concurrent
如果应该测试版本列表,可以通过设置(默认 1), 这将添加每个对象的多个版本并请求单个版本的信息。--versions=n
主基准测试将执行单独的请求以获取上传对象的对象信息。
由于对象大小并不重要,因此仅报告每秒对象数。
例:
$ warp stat --autoterm
[...]
-------------------
Operation: STAT
* Average: 10.06 MiB/s, 1030.01 obj/s
Throughput, split into 59 x 1s:
* Fastest: 11.3MiB/s, 1159.69 obj/s
* 50% Median: 10.3MiB/s, 1059.06 obj/s
* Slowest: 6.7MiB/s, 685.26 obj/s
保留
基准测试放置对象保留操作 将上传大小的对象,每个对象上都有前缀和版本。--objects--obj.size--concurrent--versions
例:
λ warp retention --objects=2500 --duration=1m
[...]
----------------------------------------
Operation: RETENTION
* Average: 169.50 obj/s
Throughput by host:
* http://192.168.1.78:9001: Avg: 85.01 obj/s
* http://192.168.1.78:9002: Avg: 84.56 obj/s
Throughput, split into 59 x 1s:
* Fastest: 203.45 obj/s
* 50% Median: 169.45 obj/s
* Slowest: 161.73 obj/s
请注意,由于只能在创建存储桶时指定对象锁定,因此可能需要重新创建存储桶。 Warp 将尝试自动执行此操作。
多部分
多部件基准测试会将分片上传到单个对象,然后测试分片的下载速度。
在分布式模式下运行时,每个客户端将上传指定的段数。
每个客户端只会启动上传, 因此,建议使用倍数,但不是必需的。--concurrent--parts--concurrent
λ warp multipart --parts=500 --part.size=10MiB
warp: Benchmark data written to "warp-remote-2022-07-15[190649]-bRtD.csv.zst"
----------------------------------------
Operation: PUT
* Average: 470.88 MiB/s, 47.09 obj/s
Throughput, split into 15 x 1s:
* Fastest: 856.9MiB/s, 85.69 obj/s
* 50% Median: 446.7MiB/s, 44.67 obj/s
* Slowest: 114.1MiB/s, 11.41 obj/s
----------------------------------------
Operation: GET
* Average: 1532.79 MiB/s, 153.28 obj/s
Throughput, split into 9 x 1s:
* Fastest: 1573.7MiB/s, 157.37 obj/s
* 50% Median: 1534.1MiB/s, 153.41 obj/s
* Slowest: 1489.5MiB/s, 148.95 obj/s
warp: Cleanup done.
.ZIP
该命令对 MinIO s3zip 扩展进行基准测试 允许zip
这将上传一个 zip 文件,其中包含 10000 个单独的文件(更改为 ),每个文件为 10KiB(更改为 )。--files--obj.size
然后,基准测试将同时下载单个文件,并将结果显示为GET基准测试。
例:
λ warp zip --obj.size=1MiB -duration=1m
warp: Benchmark data written to "warp-zip-2022-12-02[150109]-xmXj.csv.zst"
----------------------------------------
Operation: GET
* Average: 728.78 MiB/s, 728.78 obj/s
Throughput, split into 59 x 1s:
* Fastest: 757.0MiB/s, 756.96 obj/s
* 50% Median: 732.7MiB/s, 732.67 obj/s
* Slowest: 662.7MiB/s, 662.65 obj/s
这仅适用于 2022 年及以后的最新 MinIO 版本。
雪球
Snowball 基准测试将测试上传一个“snowball”TAR 文件,其中包含多个文件,这些文件被提取为单个对象。
参数:
--obj.size=N控制上载的 TAR 文件中每个对象的大小。默认值为 512KiB。--objs.per=N控制每个 TAR 文件的对象数。默认值为 50。--compress将在上传前压缩 TAR 文件。对象数据将在每个 TAR 内复制。这限制为 10MiB。--obj.size
由于 TAR 操作是在内存中完成的,因此总大小限制为 1GiB。
计算公式为 * 。 如果未指定,则也乘以 。--obj.size--concurrent--compress--objs.per
例子:
使用默认参数进行基准测试。每个 TAR 文件中的 50 x 512KiB 重复对象。压缩。
λ warp snowball --duration=30s --compress
warp: Benchmark data written to "warp-snowball-2023-04-06[115116]-9S9Z.csv.zst"
----------------------------------------
Operation: PUT
* Average: 223.90 MiB/s, 447.80 obj/s
Throughput, split into 26 x 1s:
* Fastest: 261.0MiB/s, 522.08 obj/s
* 50% Median: 237.7MiB/s, 475.32 obj/s
* Slowest: 151.6MiB/s, 303.27 obj/s
warp: Cleanup Done.
在每个 snowball 中测试 1000 个唯一的 1KB 对象,并运行 2 个并发上传:
λ warp snowball --duration=60s --obj.size=1K --objs.per=1000 --concurrent=2
warp: Benchmark data written to "warp-snowball-2023-04-06[114915]-W3zw.csv.zst"
----------------------------------------
Operation: PUT
* Average: 0.93 MiB/s, 975.72 obj/s
Throughput, split into 56 x 1s:
* Fastest: 1051.9KiB/s, 1077.12 obj/s
* 50% Median: 1010.0KiB/s, 1034.26 obj/s
* Slowest: 568.2KiB/s, 581.84 obj/s
warp: Cleanup Done.
分析吞吐量表示提取时写入的对象计数和大小。
用 显示的请求时间表示每个雪球的请求时间。--analyze.v
扇出
扇出基准测试将测试上传复制到多个单独对象的单个对象。 此功能仅在最近的 MinIO 服务器上可用。
参数:
--obj.size=N控制上载的每个对象的大小。默认值为 1MiB。--copies=N控制每个请求的对象副本数。默认值为 100。
大小计算公式为 * 。--obj.size--copies
示例:使用 8 个并发上传将 512KB 对象复制到 50 个位置。
λ warp fanout --copies=50 --obj.size=512KiB --concurrent=8
warp: Benchmark data written to "warp-fanout-2023-06-15[105151]-j3qb.csv.zst"
----------------------------------------
Operation: POST
* Average: 113.06 MiB/s, 226.12 obj/s
Throughput, split into 57 x 1s:
* Fastest: 178.4MiB/s, 356.74 obj/s
* 50% Median: 113.9MiB/s, 227.76 obj/s
* Slowest: 56.3MiB/s, 112.53 obj/s
warp: Cleanup Done.
分析吞吐量表示提取时写入的对象计数和大小。
显示的请求时间表示每个扇出呼叫的请求时间。--analyze.v
分析
基准测试完成后,所有请求数据将保存到文件中,并显示分析。
保存的数据可以通过运行来重新评估。warp analyze (filename)
分析数据
所有分析都将在完整数据的减少部分上进行。 当所有线程完成一个请求时,数据聚合将开始 并且当线程的最后一个请求被启动时,时间段将停止。
这是为了排除由于预热和螺纹在不同时间完成而导致的变化。 因此,分析时间通常会略低于所选基准持续时间。
例:
Operation: GET
* Average: 92.05 MiB/s, 9652.01 obj/s
然后,基准运行将分为由 指定的固定持续时间段。 对于每个段,将跨所有线程计算吞吐量。-analyze.dur
分析输出将显示最快、最慢和 50% 的中位数段。
Throughput, split into 59 x 1s:
* Fastest: 97.9MiB/s, 10269.68 obj/s
* 50% Median: 95.1MiB/s, 9969.63 obj/s
* Slowest: 66.3MiB/s, 6955.70 obj/s
分析参数
旁边是重要的,它指定了时间段大小 聚合数据 可以使用一些其他参数。--analyze.dur
指定将输出每个主机的时间聚合数据,而不仅仅是平均值。 例如:--analyze.v
Throughput by host:
* http://127.0.0.1:9001: Avg: 81.48 MiB/s, 81.48 obj/s (4m59.976s)
- Fastest: 86.46 MiB/s, 86.46 obj/s (1s)
- 50% Median: 82.23 MiB/s, 82.23 obj/s (1s)
- Slowest: 68.14 MiB/s, 68.14 obj/s (1s)
* http://127.0.0.1:9002: Avg: 81.48 MiB/s, 81.48 obj/s (4m59.968s)
- Fastest: 87.36 MiB/s, 87.36 obj/s (1s)
- 50% Median: 82.28 MiB/s, 82.28 obj/s (1s)
- Slowest: 68.40 MiB/s, 68.40 obj/s (1s)
--analyze.op=GET将仅分析 GET 操作。
指定将仅考虑来自此特定主机的数据。--analyze.host=http://127.0.0.1:9001
Warp 将自动丢弃所有线程的第一个和最后一个请求完成的时间。 但是,如果您想从汇总数据中放弃额外的时间, 这是可能的。例如,将跳过每种操作类型的前 10 秒数据。analyze.skip=10s
请注意,跳过数据并不总是会导致聚合数据的时间确切减少 因为开始时间仍将与开始的请求保持一致。
每个请求统计信息
通过添加参数,可以显示每个请求的统计信息。--analyze.v
默认情况下不启用此功能,因为假设基准测试受吞吐量限制, 但在某些情况下,例如确定单个主机的问题可能很有用。
例:
Operation: GET (386413). Ran 1m0s. Concurrency: 20. Hosts: 2.
Requests considered: 386334:
* Avg: 3ms, 50%: 3ms, 90%: 4ms, 99%: 8ms, Fastest: 1ms, Slowest: 504ms
* TTFB: Avg: 3ms, Best: 1ms, 25th: 3ms, Median: 3ms, 75th: 3ms, 90th: 4ms, 99th: 8ms, Worst: 504ms
* First Access: Avg: 3ms, 50%: 3ms, 90%: 4ms, 99%: 10ms, Fastest: 1ms, Slowest: 18ms
* First Access TTFB: Avg: 3ms, Best: 1ms, 25th: 3ms, Median: 3ms, 75th: 3ms, 90th: 4ms, 99th: 10ms, Worst: 18ms
* Last Access: Avg: 3ms, 50%: 3ms, 90%: 4ms, 99%: 7ms, Fastest: 2ms, Slowest: 10ms
* Last Access TTFB: Avg: 3ms, Best: 1ms, 25th: 3ms, Median: 3ms, 75th: 3ms, 90th: 4ms, 99th: 7ms, Worst: 10ms
Requests by host:
* http://127.0.0.1:9001 - 193103 requests:
- Avg: 3ms Fastest: 1ms Slowest: 504ms 50%: 3ms 90%: 4ms
- First Byte: Avg: 3ms, Best: 1ms, 25th: 3ms, Median: 3ms, 75th: 3ms, 90th: 4ms, 99th: 8ms, Worst: 504ms
* http://127.0.0.1:9002 - 193310 requests:
- Avg: 3ms Fastest: 1ms Slowest: 88ms 50%: 3ms 90%: 4ms
- First Byte: Avg: 3ms, Best: 1ms, 25th: 3ms, Median: 3ms, 75th: 3ms, 90th: 4ms, 99th: 8ms, Worst: 88ms
Throughput:
* Average: 1.57 MiB/s, 6440.36 obj/s
Throughput by host:
* http://127.0.0.1:9001:
- Average: 0.79 MiB/s, 3218.47 obj/s
- Fastest: 844.5KiB/s
- 50% Median: 807.9KiB/s
- Slowest: 718.9KiB/s
* http://127.0.0.1:9002:
- Average: 0.79 MiB/s, 3221.85 obj/s
- Fastest: 846.8KiB/s
- 50% Median: 811.0KiB/s
- Slowest: 711.1KiB/s
Throughput, split into 59 x 1s:
* Fastest: 1688.0KiB/s, 6752.22 obj/s (1s, starting 12:31:40 CET)
* 50% Median: 1621.9KiB/s, 6487.60 obj/s (1s, starting 12:31:17 CET)
* Slowest: 1430.5KiB/s, 5721.95 obj/s (1s, starting 12:31:59 CET)
TTFB是从请求发送到收到第一个字节的时间。First Access是每个对象的首次访问。Last Access是每个对象的最后一次访问。
显示最快和最慢的请求时间,并选择 百分位数和总金额是考虑请求的。
请注意,不同的衡量指标用于选择每个主机的请求数,对于组合的 所以可能会有差异。
时序 CSV 输出
可以输出分析的CSV数据,使用该数据将CSV数据写入指定文件。--analyze.out=filename.csv
以下是导出的数据字段:
| 页眉 | 描述 |
|---|---|
index |
细分市场索引 |
op |
执行的操作 |
host |
如果只有一个主机,主机名,否则为空 |
duration_s |
段的持续时间(以秒为单位) |
objects_per_op |
每个操作的对象数 |
bytes |
操作的总字节数(分布式) |
full_ops |
操作完全包含在段内 |
partial_ops |
在段外开始或结束,但也在段内执行的操作 |
ops_started |
在段内开始运营 |
ops_ended |
该部门内结束的运营 |
errors |
在段内结束的操作上记录的错误 |
mb_per_sec |
段内操作的 MiB/s(分布式) |
ops_ended_per_sec |
每秒在段内结束的操作 |
objs_per_sec |
段中每秒处理的对象数(分布式) |
start_time |
段的绝对开始时间 |
end_time |
段的绝对结束时间 |
其中一些字段是分布式的。 这意味着部分操作的数据已分布在它们发生的段中。 操作在段内的百分比越大,其中大部分归因于该段。
这就是为什么可以有一个部分对象归因于一个段, 因为只有一部分操作发生在该段中。
比较基准
可以使用 to 比较两个记录的运行 查看之前和之后之间的差异。 “之前”不需要在“之后”之前按时间顺序排列,但将显示差异 从“之前”变为“之后”。warp cmp (file-before) (file-after)
举个例子:
λ warp cmp warp-get-2019-11-29[125341]-7ylR.csv.zst warp-get-2019-202011-29[124533]-HOhm.csv.zst
-------------------
Operation: PUT
Duration: 1m4s -> 1m2s
* Average: +2.63% (+1.0 MiB/s) throughput, +2.63% (+1.0) obj/s
* Fastest: -4.51% (-4.1) obj/s
* 50% Median: +3.11% (+1.1 MiB/s) throughput, +3.11% (+1.1) obj/s
* Slowest: +1.66% (+0.4 MiB/s) throughput, +1.66% (+0.4) obj/s
-------------------
Operation: GET
Operations: 16768 -> 171105
Duration: 30s -> 5m0s
* Average: +2.10% (+11.7 MiB/s) throughput, +2.10% (+11.7) obj/s
* First Byte: Average: -405.876µs (-2%), Median: -2.1µs (-0%), Best: -998.1µs (-50%), Worst: +41.0014ms (+65%)
* Fastest: +2.35% (+14.0 MiB/s) throughput, +2.35% (+14.0) obj/s
* 50% Median: +2.81% (+15.8 MiB/s) throughput, +2.81% (+15.8) obj/s
* Slowest: -10.02% (-52.0) obj/s
列出了所有相关差异。这是两次运行。 将显示参数的差异。warp get
通常的分析参数可用于定义线段长度。
合并基准
可以使用该命令合并来自多个客户端的运行。warp merge (file1) (file2) [additional files...]
该命令将输出一个组合数据文件,其中包含所有在时间上重叠的数据。
组合输出实际上与运行具有更高并发设置的单个基准相同。 在多个客户端上运行基准测试的主要原因是帮助消除客户端瓶颈。
请务必注意,只有绝对时间严格重叠的数据才会被考虑进行分析。
流入数据库输出
Warp 允许将实时统计信息推送到 InfluxDB v2 或更高版本。
这可以与参数结合使用,这将允许在不消耗内存的情况下进行长时间运行的测试,并且仍然可以访问性能数字。--stress
Warp 不提供对发送到 InfluxDB 的数据的任何分析。
配置
InfluxDB 是通过参数启用的。或者,可以在环境变量中设置参数。--influxdbWARP_INFLUXDB_CONNECT
该值的格式必须类似于 URL:
| 部分 | |
|---|---|
|
连接类型。替换为或httphttps |
|
替换为访问服务器所需的令牌 |
|
替换为服务器的主机名或 IP 地址 |
|
替换为服务器的端口 |
|
替换为要在其中放置数据的存储桶 |
|
替换为数据应关联的组织(如果有) |
|
要添加到每个数据点的一个或多个标记 |
每个参数都可以进行 URL 编码。
例:
--influxdb "http://shmRUvVjk0Ig2J9qU0_g349PF6l-GB1dmwXUXDh5qd19n1Nda_K7yvSIi9tGpax9jyOsmP2dUd-md8yPOoDNHg==@127.0.0.1:8086/mybucket/myorg?mytag=myvalue"
这将使用提供的令牌连接到 8086.127.0.0 上的端口 1。shmRU...
数据将放置在 中并与 相关联。将在所有数据点上设置一个附加标记。mybucketmyorgmytagmyvalue
对于分布式基准测试,所有客户端都将发送数据,因此不应使用 localhost 和 127.0.0.1 等主机。
数据
所有运行中的测量均为 .warp
| 标记 | 价值 |
|---|---|
warp_id |
包含一个随机字符串值,每个客户端都是唯一的。 这可用于在使用分布式基准测试时识别单个运行或单个 warp 客户端。 |
op |
包含操作类型,例如 GET、PUT、DELETE 等。 |
endpoint |
端点是操作发送到的端点。 没有此值的测量值是 warp 客户端的总和。 |
字段作为每个操作类型的每次运行的累计总计发送。
每个操作(请求)完成后都会发送新指标。没有记录任何操作间进度。 这意味着更大的对象(意味着更少的请求)将产生更大的波动。在分析时需要注意这一点很重要。
| 田 | 价值 |
|---|---|
requests |
执行的请求总数 |
objects |
受影响的对象总数 |
bytes_total |
受影响的总字节数 |
errors |
遇到的错误总数 |
request_total_secs |
总请求时间(秒) |
request_ttfb_total_secs |
相关操作到第一个字节的总时间(以秒为单位) |
提供的统计数据意味着,要获得“随时间变化的利率”,必须将数字计算为差值(增加/正导数)。
总结
运行完成后,将发送摘要。这将是一种测量类型。 除了上面的字段外,它还将包含:warp_run_summary
| 田 | 价值 |
|---|---|
request_avg_secs |
平均请求时间 |
request_max_secs |
最长请求时间 |
request_min_secs |
最短的请求时间 |
request_ttfb_avg_secs |
平均到第一个字节的时间 (TTFB) |
request_ttfb_max_secs |
最长的TTFB |
request_ttfb_min_secs |
最短的TTFB |
所有时间均以浮点秒为单位。
将针对每个主机和操作类型发送摘要。
服务器分析
在针对 MinIO 服务器运行时,可以在基准测试运行时启用分析。
这是通过添加具有所需配置文件类型的参数来完成的。 这要求凭据允许第一个主机的管理员访问权限。--serverprof=type
| 类型 | 描述 |
|---|---|
cpu |
CPU 配置文件确定程序在主动消耗 CPU 周期(而不是在休眠或等待 I/O 时)花费时间的位置。 |
mem |
堆配置文件报告当前实时分配;用于监视当前内存使用情况或检查内存泄漏。 |
block |
块配置文件显示 goroutines 阻止等待同步原语(包括计时器通道)的位置。 |
mutex |
互斥配置文件报告锁争用。当您认为由于互斥锁争用而未充分利用 CPU 时,请使用此配置文件。 |
trace |
当前程序执行的详细跟踪。这将包括有关 goroutine 调度和垃圾回收的信息。 |
所有集群成员的概要文件将下载为 zip 文件。
分析配置文件需要安装 Go 工具。 有关性能分析工具的基本用法,请参阅性能分析Go程序 以及 Go 执行跟踪器的介绍以获取更多信息。