性能工具之常见流量复制工具(转载)
一、什么是流量复制?
我们把用户访问系统造成的数据传输定义为流量,那么在用户访问系统的过程中,我们可以把进入和流出的数据复制下来,进行保存,待后续使用,即离线模式,或者转发到一个新的服务器,立即使用,即在线模式。
二、流量复制的应用
性能测试中我们可以使用诸如 ab, wrk, httperf, locust, JMeter 等工具模拟用户请求,也可以使用流「流量复制」工具,实时捕捉生产环境流量并导向目标测试系统。同时,这些「流量复制」工具可以支持对真实流量进行放大或缩小。
于是有人说,就是因为这样才应该直接用真实流量的方式来做嘛,这样就不用管业务模型了,直接就有生产的业务模型了。没错,只要你能通过生产流量扩大回放的方式实现压力部分,确实可以不用考虑业务场景了。但这么做的前提也必须是你的生产流量来源是可以覆盖想要测试的业务场景的。
流量回放
这里要批驳一个观点,就是有些人觉得只有通过生产流量回放的方式,才是真实地 模拟了线上的流量。事实上,这个观点是偏颇的。
总结一下,流量复制工具的优势就是可以将线上流量拷贝到测试机器,实时的模拟线上环境,真实的模拟线上流量的变化规律,达到在程序不上线的情况下实时承担线上流量的效果。
三、常见的流量复制工具
综述

常见流量复制工具
流量复制工具一般分成这几类:
基于web 服务器的请求复制
优点:请求多样化、成本
缺点:不具备通用性、丢失网络延迟、占用在线资源比较严重
基于应用层的流量复制工具
优点:实现简单
缺点:但会挤占线上应用的资源(比如连接资源,内存资源等),还可能会因为耦合度高而影响正常业务。
基于网络栈的流量复制工具,直接从链路层抓取数据包
优点:应用影响较小
缺点:但是其实现也就相对复杂一些
1、ngx_http_mirror_module
在 Nginx 1.13.4 中引入的插件,它是一种应用层的流量复制工具
该模块目前只实现了两个配置指令,用法相当简单:
location / {
mirror /mirror;
proxy_pass
}location /mirror {
internal;
proxy_pass http://test_backend$request_uri;
}
每一条 mirror 配置项对应用户请求的一个副本,我们就可以通过配置多次 mirror 指令来实现 “流量 放大” 的效果。当然,你也可以将多个副本转发给不同的后端目标系统。
示例配置:
server {
listen 8080;
access_log /home/work/log/nginx/org.log;
root html/org;
}server {
listen 8081;
access_log /home/work/log/nginx/mir.log ;
root html/mir;
}upstream backend {
server 127.0.0.1:8080;
}upstream test_backend {
server 127.0.0.1:8081;
}server {
listen 80;
server_name localhost;# original 配置
location / {
# mirror指定镜像uri为 /mirror
mirror /mirror;
# off|on 指定是否镜像请求body部分(开启为on,则请求自动缓存;)
mirror_request_body off;
# 指定上游server的地址
proxy_pass http://backend;
}
# mirror 配置
location /mirror {
# 指定此location只能被“内部的”请求调用
internal;
# 指定上游server的地址
proxy_pass http://test_backend$request_uri;
# 设置镜像流量的头部
proxy_set_header X-Original-URI $request_uri;
}}
流量放大, 配置两个 mirror 即可:
location / {
mirror /mirror;
mirror /mirror;
proxy_pass http://backend;
}
2、TCPCopy
TCPCopy 是一种请求复制(复制基于 TCP 的 packets)工具 ,通过复制在线数据包,修改 TCP/IP 头部信息,发送给测试服务器,达到欺骗测试服务器的TCP 程序的目的,从而为欺骗上层应用打下坚实基础。
TCPCopy 由网易技术部的王斌在王波的工作基础上中 2010 年开发,并于 2011 年 9 月开源。T
TCPCopy 一般会与 TCPDump 共同使用。
基于 C 语言
地址:https://github.com/session-replay-tools/tcpcopy
stars:3.9k
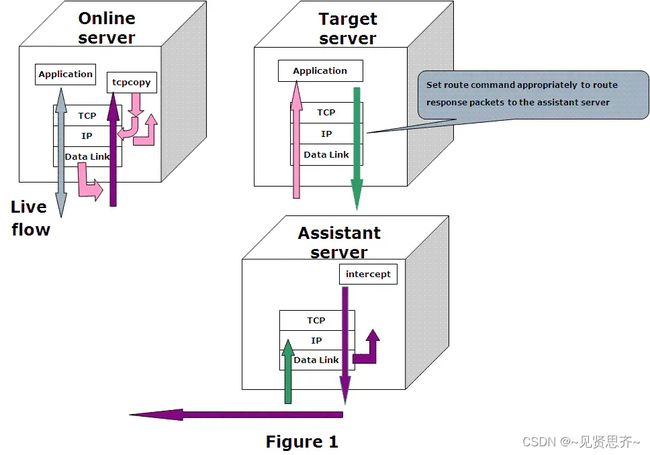
TCPCopy 由两部分组成:TCPCopy 和 intercept。TCPCopy 在线上服务器上运行并捕获在线请求,intercept 运行在辅助服务器上并执行一些辅助工作,例如将响应信息传递给 TCPCopy。测试应用程序则在目标服务器上运行。也就是使用上其实还需要一个辅助服务器。

运行逻辑图
TCPCopy 的主要优势:
- 协议无感知,可以透明转发,能够支持基于 TCP 的任意应用层协议,如 MySQL,Kafka,Redis 等
- 实时转发,延时较低
- 可以保留原始请求 IP 端口信息,测试服务器可用于统计
同时,也具有以下不足:
- 无法动态添加多个下游服务器
- 由于透明转发,不做协议解析,无法发现数据异常,如部分 TCP 包丢失,测试服务器将收到不完整的数据;此外,也无法对应用层数据进行筛选和修改进行修改
- 核心组件设计时未进行多线程设计,处理能力存在瓶颈
- 需要修改 iptables 来丢弃下游服务的回包,用在生产或公共的测试环境存在较大风险
3、GOReplay
Goreplay 是用 Golang 写的一个 HTTP 实时流量复制工具。功能更强大,支持流量的放大、缩小,频率限制,还支持把请求记录到文件,方便回放和分析,也支持和 ElasticSearch 集成,将流量存入 ES 进行实时分析。
GoReplay 不是代理,而是监听网络接口上的流量,不需要更改生产基础架构,而是在与服务相同的计算机上运行 GoReplay 守护程序。
特点:简单易用
地址:https://github.com/buger/goreplay
stars:14.1k
与 TCPCopy 相比它的架构更简单,只有一个 gor 组件,如下:


整体架构图
只需要在生产服务器上启动一个 gor 进程,它负责所有的工作包括监听、过滤和转发。它的设计遵循 Unix 设计哲学:一切都是由管道组成的,各种输入将数据复用为输出。
敲下命令,即可进行流量复制。无需理解复杂的概念。同样支持在线直接转发。存储到文件进行重放,N 倍重放。
sudo ./gor --input-raw :8000 --output-http="http://localhost:8001"
sudo ./gor --input-raw :8000 --output-file=requests.gor
相比 tcpcopy 只能复制 HTTP 和 HTTPS 的流量。使用时编译很麻烦,一般直接使用编译好的版本。
一般配合 diffy 一起使用,diffy 提供 diff 能力,可以智能降噪音。
diffy 地址:https://github.com/twitter-archive/diffy
4、TCPReplay
TCPReplay 是一种 pcap 包的重放工具,它可以将用 ethreal、wireshark工具抓下来的包原样或经过任意修改后重放回去。它允许你对报文做任意的修改(主要是指对2层、3层、4层报文头),指定重放报文的速度等,这样tcpreplay 就可以用来复现抓包的情景以定位 bug,以极快的速度重放从而实现压力测试。
地址:https://github.com/appneta/tcpreplay
stars:765
5、JVM-Sandbox
JVM 沙箱容器,一种 JVM 的非侵入式运行期 AOP 解决方案
需要代码的编写,可适用于一些比较定制化的场景
阿里巴巴开源
地址:https://github.com/alibaba/jvm-sandbox
stars:4.3k
整体架构图:

沙箱有两种启动方式:
使用jvm的attach机制,线上随时可进行attach
java agent启动,需要在命令行增加参数,故需要重启。
流量复制的场景下基本就是选择 attach了。提供的脚本非常简单易用,直接在安装目录下敲入命令即可。
# 假设目标JVM进程号为'2343'
./sandbox.sh -p 2343
6、Sharingan
Sharingan(中文名:写轮眼)是一个基于 golang 的流量录制回放工具,录制线上真实请求流量进行回放测试,适合项目重构、回归测试等。
滴滴开源
地址:https://github.com/didi/sharingan
stars:656
整体架构图:

整体架构图
recorder: 流量录制模块,录制流量本地文件存储、发送流量到录制agent等。
recorder-agent:流量录制agent,单独进程启动,控制录制比例、流量存储等。
replayer: 流量回放模块,重定向连接到Mock Server、Mock时间、添加流量标识等。
replayer-agent:流量回放agent,单独进程启动,查询流量、查询/上报噪音、流量diff、批量回放、生成覆盖率报告等。
7、RDebug
支持 PHP,暂不支持 java
滴滴开源
地址:https://github.com/didi/rdebug/blob/master/README_zh_CN.md
stars:1.1k
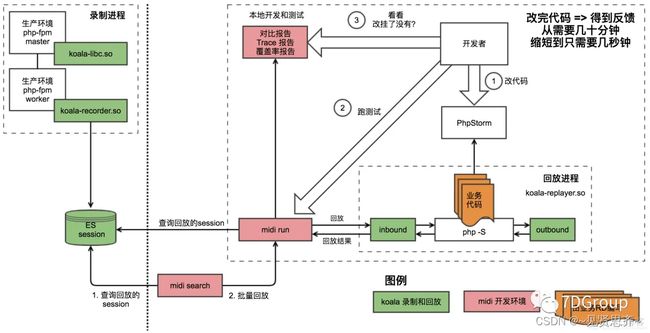
整体架构图:
四、总结
复制请求:通过将一台机器的请求复制多份发送到指定的压测机器
适用场景:系统调用量比较小的场景
优点:为了使得压测的请求跟真实的业务请求更加接近,在压测请求的来源方式上,我们尝试从真实的业务流量进行录制和回放,采用请求复制的方式来进行压力测试
缺点:同样也面临着处理写请求脏数据的问题,另外一个缺点复制的请求必须要将响应拦截下来,所以被压测的这台机器需要单独提供,且不能提供正常的服务(不能把响应给到真实的用户了,比如涉及到发短信邮件之类的)