DataFrame的三种遍历操作和其他基本操作以及和series的区别
基本操作:
pd.set_option('display.max_rows', None) # 设置行数为无限制
pd.set_option('display.max_columns', None) # 设置列数为无限制
pd.set_option('display.width', 1000) # 设置列宽
pd.set_option('display.colheader_justify', 'left') # 设置列标题靠左
读取csv文件为dataframe,excel表可以另存为csv文件
df = pd.read_csv(r'folder_path\file_name.csv', encoding='utf-8')将dataframe写为csv文件:
df.to_csv(r'folder_path\file_name.csv', encoding='utf-8')给出行数和列数
print(df.shape) ![]()
计算基本的统计数据
print(df.describe())
series对象.tolist()可以 将series转化为列表
series_list = row.tolist() # 将series转化为列表pd.isna判断是否为NAN类型
columns = [column for column in series_list if not pd.isna(column)] # pd.isna判断是否为NAN类型三种遍历操作:
按行遍历:
iterrows()将DataFrame的每一行迭代为(index, Serie)对,可以通过row[name]对元素访问:
print("iterrows方法生成的每对(index, Series)的index:", index) # 打印dataframe的行索引
print("iterrows方法生成的每对(index, Series)series:", row)
print("每行series的索引为首次病程记录的元素:", row['首次病程记录']) # 根据生成的series的索引得到每行元素
print("日常病程记录的series:", row['日常病程记录'])第一个print
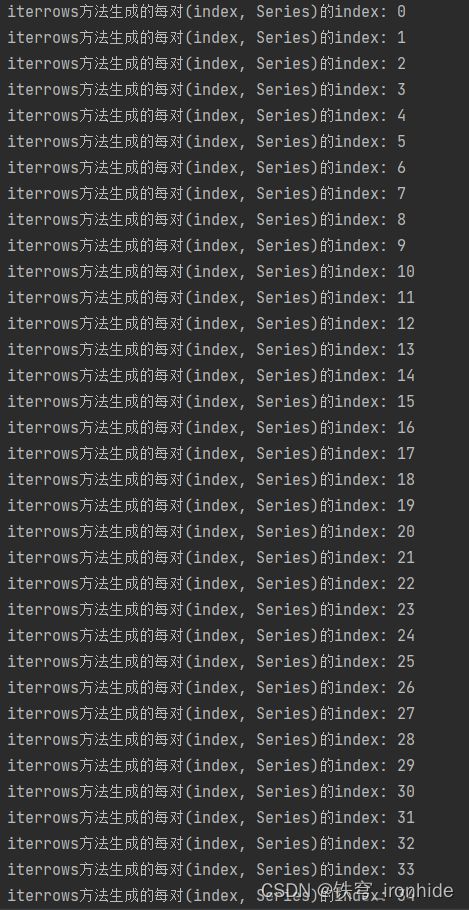
第一个和第二个print
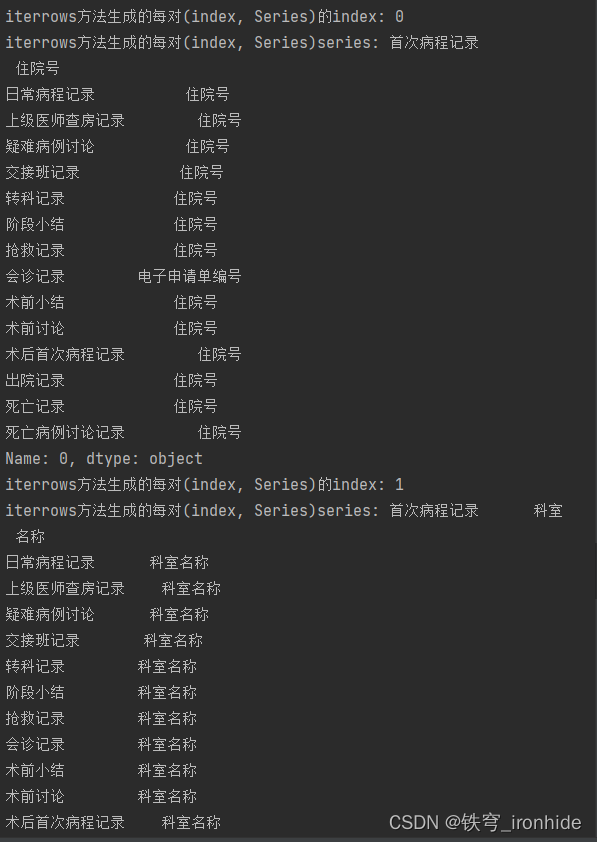
第三个print

itertuples(): 按行遍历,将DataFrame的每一行迭代为元祖,可以通过row[name]对元素进行访问,比iterrows()效率高:
for row in df.itertuples():
print(row) # eg:Pandas(Index=0, user=1, item=1, rating=3)
print(getattr(row, '首次病程记录'), getattr(row, '日常病程记录')) # 输出对应每一列
第一个print
第二个print

按列遍历:
iteritems():按列遍历,将DataFrame的每一列迭代为(列名, Series)对,可以通过row[index]对元素进行访问:
for index, row in df.items():
print(index) # 打印dataframe列索引
print(row) # 打印每列的series信息
print(row[0]) # 输出每个series的第一个元素
print(row[1]) # 输出每个series的第二个元素
print(type(row[1])) # str第一个print

第二个print

第三个print
和series的区别:
pandas有两个主要的数据结构:Series和DataFrame:
Series:
Series是一种类似于一维数组的对象。它由一组数据(各种Numpy数据类型)以及一组与之相关的数据标签(即索引)组成。Series只有行索引
for index, row in df.items():
print(index) # 打印dataframe列索引
print(row) # 打印每列的series信息 
DataFrame:
DataFrame是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame既有行索引也有列索引,它可以被看做由Series组成的字典(共同用一个索引)