JAVA基础语法:数组
文章目录
- 一.数组的基本用法
-
- 1.什么是数组
- 2.数组的创建与初始化
- 3.数组的使用
- 4.如何遍历数组
- 5.数组和字符串的转换
- 二.数组和方法的关系
-
- 1.数组作为方法的参数
- 三.关于引用数据类型的理解问题
-
- 1.实参与形参
- 2.引用
- 3.栈
- 4.堆
- 四.实战演练
-
- 1.找出数组最大值
- 2.求数组的平均值
- 3.查找一个数组中是否包含指定元素
- 4.二分查找
- 5.判断数组是否有序(默认升序)
- 6.冒泡排序
- 7.数组的逆序
- 8.数组的数字排列问题
一.数组的基本用法
1.什么是数组
数组的本质上就是我们能“批量”创建相同类型的变量,也就是以此定义N个相同数据类型的变量,我们就把这种结构称之为数组。
2.数组的创建与初始化
a.数组的动态初始化
语法:
在创建数组时,托没有使用{}来初始化每个元素的值,每个元素都是该类型的默认值。
数据类型[]数组名称 = new数组类型[]{初始化数据(可选)}
int []arr = new int []{1,3,5,7,9};
数据类型[]数组名称 = new数据类型[num](当前数组的最大元素个数)]
int []arr = new int [5];
b.数组的静态初始化(了解即可)
语法:
数据类型[] 数组名称 = {初始化数据}
int [] arr = {1,3,5,7,9};
3.数组的使用
a.获取一个数组的长度(最多保存的元素个数),使用数组名称.Length
int [] arr = new int [5];//长度就是5
如何拿到5:
arr.Length;

b.如何访问数组元素:
使用数组名称[要访问的元素相较于第一个元素的偏移量]
使用数组名称[元素的索引]
int []arr = new int []{1,3,5,7,9};
要取得第一个元素:arr[0];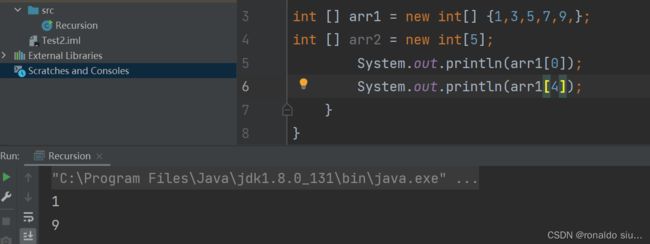
如果访问了一个数组索引并不存在的元素:会出现异常
4.如何遍历数组

5.数组和字符串的转换
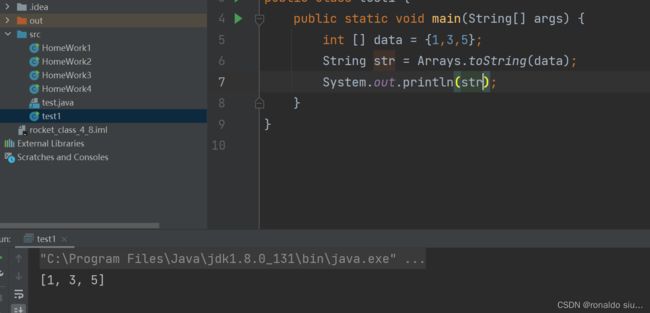
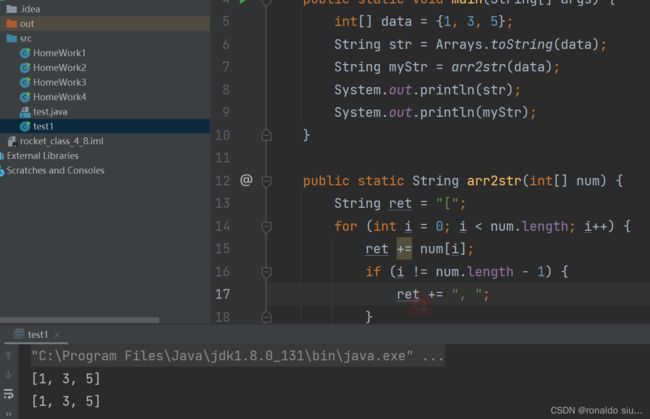
Arrays-数组的工具类,包含数组转字符串的方法,数组排序的方法,等等操作数组的各种方法都在这个类中,我们直接通过类名称来调用。
二.数组和方法的关系
1.数组作为方法的参数
创建一个方法,接收任意的整形数组并打印。
语法:public ststic void printArr(int[] num){}

三.关于引用数据类型的理解问题
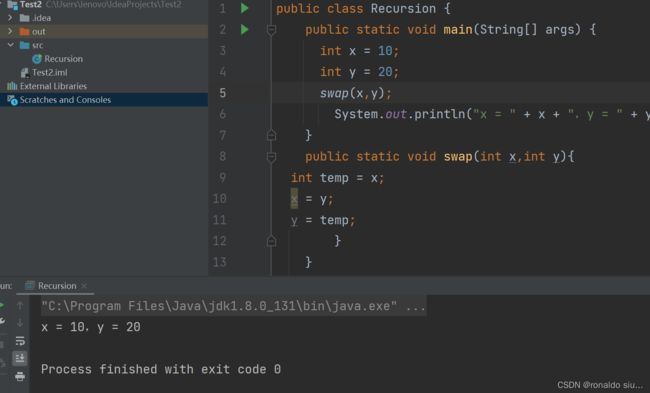
1.实参与形参
实参,位于主方法的临时变量
形参,位于swap方法的临时变量

2.引用
引用就是起个别名,保存的数值就是该对象的地址。
对于数组对象来说,数组的引用实际上就是保存了数组的首元素地址。
3.栈
方法的调用就是在栈区进行的,每个方法的调用过程,就是一个栈帧的入栈以及出栈的过程。
“栈”是先进后出的结构
方法中的局部变量和形参都在栈中储存。当方法调用结束出栈时,临时变量就会销毁
4.堆
JVM的另一块内存区域称为“堆区”,所以对象(数组对象,类的实例化对象,接口对象)都在堆区储存。
总结:
a.数组对象就是实实在在在堆中保存数据的实体,new出来的都在堆中。
b.数组的引用就是给这块数组对象起了个名字,保存这个数组对象的首地址而已。
四.实战演练
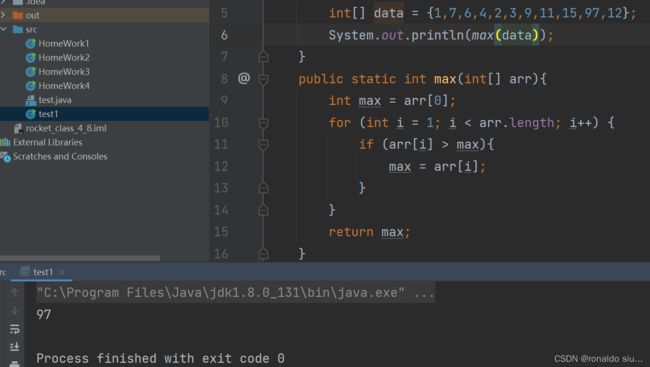
1.找出数组最大值
我们在寻找最大值的过程中,需要从数组第一个元素开始遍历,直到走到数组的最后一个元素,找出最大值
2.求数组的平均值
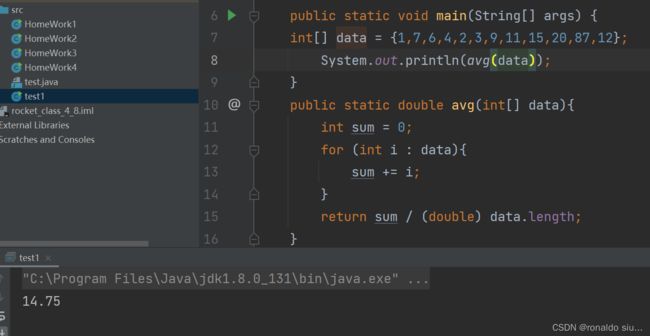
3.查找一个数组中是否包含指定元素
查找一个数组中是否包含指定元素,若存在,返回该元素的索引,若不存在,返回-1

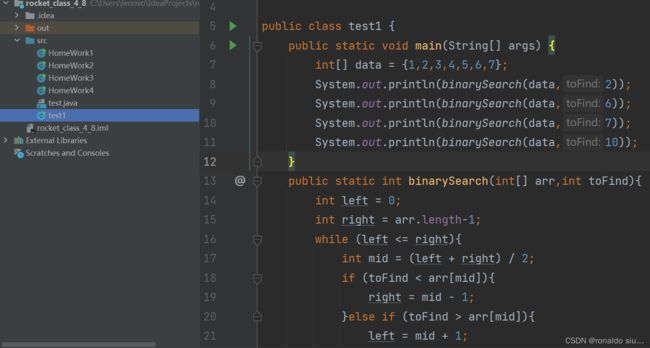
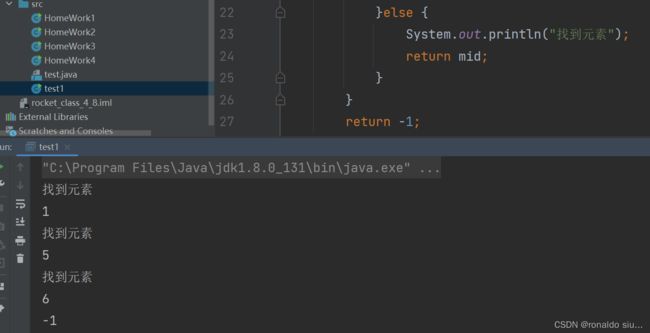
4.二分查找
前提:在有序(升序或者降序)的集合上,才能使用二分查找。
在有序区间中查找一个元素toFind,我们不断比较待查找元素和区间的中间位置元素的大小关系。
a.
5.判断数组是否有序(默认升序)
所谓的升序数组,前一个元素<=后一个元素。
若在遍历数组的过程中,发现一个元素比后一个元素还大,找到了一个反例,只要有一个反例,则这个数组一定不是升序数组。
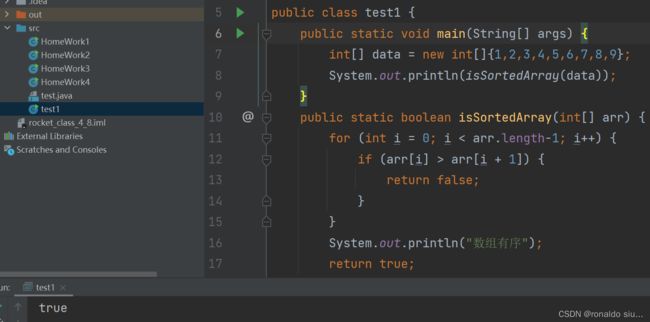
6.冒泡排序
假设现在数组有n个元素,每进行一次遍历过程,就将当前数组最大值放在数组末尾,每进行一次遍历,就有一个元素到达了最终位置。
a.

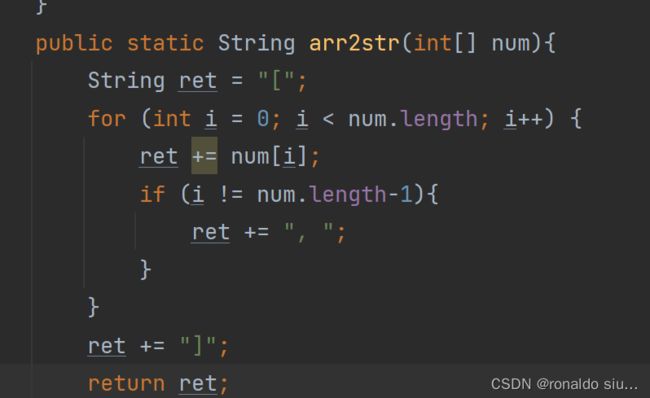
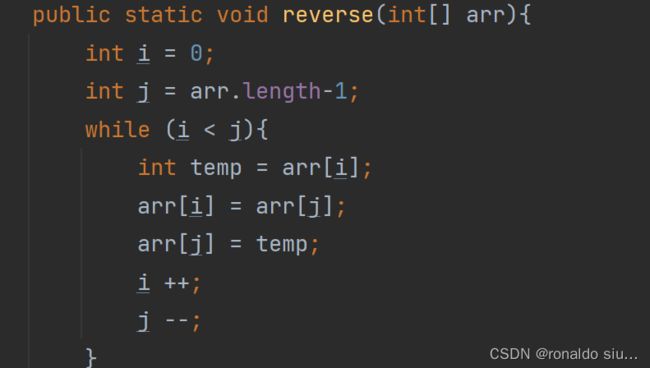
7.数组的逆序
将一个数组的元素,前面的换到后面去

8.数组的数字排列问题
