【AIGC】斯坦福小镇升级版——AI-Town源码解读
写在前面的话:
接上一篇斯坦福小镇升级版——AI-Town搭建指南,本本篇将解读 AI-Town 使用的技术栈、代码架构、与LLM的交互,以及与斯坦福AI小镇的对比结果(如想直接看结论可跳到文章最后)
整体架构
技术栈
AI-Town 使用 TypeScript/JavaScript 完成前后端全栈开发,使用的平台和工具有:
-
游戏引擎和数据库(Game engine & Database):Convex
-
向量数据库(VectorDB):Pinecone
-
登录认证(Auth):Clerk
-
文本生成模型(Text model):OpenAI
-
部署(Deployment):Fly
-
像素图生成(Pixel Art Generation):Replicate、Fal.ai
概念简介
项目充分地复用了许多开源项目与组件,集中在这里进行介绍,具体地:
-
Convex 是一个全栈TypeScript开发平台,用户部署应用程序时无需关心数据库与后端服务,并且默认提供了缓存与事务功能,能够实时在控制面板中查看全局数据、日志以及函数
Convex整体是Serverless架构,为了保证一致性所有的接口函数都必须是幂等的

Convex 提供关系型数据库的功能,用户无需关心数据的存储方式,只需要通过 jsonl 或者是手动在界面上创建 Table 即可,创建完成后 Convex 会自动生成对应的 API,可以直接在 TS 代码里调用对应的 API 访问数据(太方便了TAT)

所有的 Table 及其数据都可以在 Convex 的项目控制台的
Data页中实时观察以及修改,如想从代码里查看表结构,可阅读convex/schema.ts文件 -
README里有提到此项目的原型是基于这个Phaser3 项目,但源码全部重写过,有感兴趣的可以参考
-
初始游戏地图用 PixiJS 实现,见
PixiStaticMap组件,如需引入新地图,项目推荐的方式是在Tiled 上编辑成csv文件,并转成类似convex/maps/firstmap.ts文件中二维数组的方式导入项目(笔者注:本来以为是自动生成地图,但没有这个功能) -
2D相机
PixiViewport是开源的PixiJS组件,详细实现可以看这里 -
游戏音乐采用AI生成,在Replicate平台上运行,模型在这里,代码注释里也有标注,目前选的模型只能生成 30 秒的音乐,选择
MusicGen-Small可以生成更长的音乐;使用者可以通过修改convex/lib/replicate.ts文件来重新生成音乐,也可以通过修改convex/crons.ts控制多久重新生成一次音乐 -
游戏角色的像素图(应该)是通过 Fal.ai 生成的,代码里没有看到相关接口,猜测是生成后直接导入的(README里有提到用了Fal.ai)
代码分析
目录结构
package.json 里 npm run dev 实际同时启动前端 NextJS 项目和后端的 Convex 部署,两者也可以分别启动
具体到代码,目录虽然很多,但逻辑只需要关注 convex —— 后端代码目录、 src —— 前端NextJS代码目录即可(因为项目是Serverless架构,函数驱动的,看源码时最好把前后端看作一个整体)
NextJS 的src目录用的是 app目录模式,总共三个页面, sign-in 和 sign-up 都是引用 Clerk 提供的组件,实际只实现了一个根路由的网页; middleware.ts 也是引用了 Clerk 的自动插件;components 则是项目实现的插件
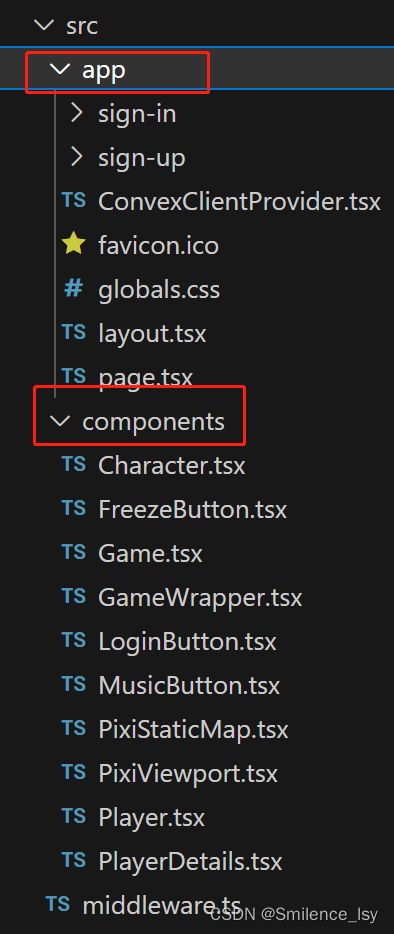
前端组件
这里我们主要关注根目录的 page.tsx 是如何渲染游戏画面的, page.tsx 引用了 GameWrapper 组件,调用 Game 组件,使用了 PixiViewport (开源的2D相机)、 PixiStaticMap (初始游戏地图)、 ConvexProvider (提供Convex客户端)、 Player (角色组件)等
其他组件在前面的基础概念/技术栈章节都提到过了,基本都是开源组件,如对实现方法有兴趣可阅读相关项目,这里主要关注 Player 组件
Player 组件保存每个角色的动画、位置、动作等数据,并调用 Character 组件,显示动作对应的动画
Player 能够进行的动作实际只有三个, Moving (移动)、 Speaking (交谈中)、 Thinking (思考),相比斯坦福AI小镇丰富的动作以及与地图的交互,AI-Town实际只是搭建了一个Agents与Agents交谈的框架,具体的动作状态由Convex的 playerState 参数控制
Convex函数
后端的入口在 convex/init.ts 文件,提供了几个Convex函数,包括 reset 函数(重启一个新世界)、 resetFrozen 函数(重启一个新世界并锁定时间,方便一个个迭代执行)、 seed 函数(生成一个新世界)、 addPlayers 函数(添加角色)等等,都可以独立运行以观察函数流程
// 运行单个函数
npx convex run --no-push [文件名]:[函数名]
核心数据结构
后续关键函数中会提到一些数据表,这里先描述下这几张表的用途和数据存储形式
-
memories表用于存储Agents的记忆,是用到最频繁的数据结构,但表结构其实很简单,description是这段记忆的内容,一般是文字描述、data包括这段记忆的类型以及关联的其他数据结构的id(类型有conversation-对话、reflection-反思、relationship-关系等)、playerId用于关联是属于哪个Agent的记忆、importance是对这段记忆重要度的评级

-
agents表中记录了Agents的实时状态,比如是否正在思考,是否处于激活状态等,主要是一些标志位
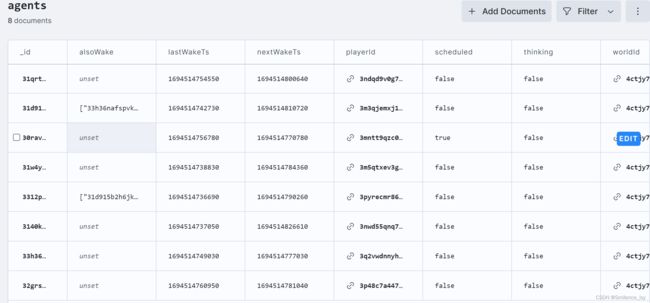
-
journal表中记录了详细的Agents行为路径

关键函数
每帧的tick函数位于 convex/engine.ts 文件,每次运行将检查是否有不处于Thinking状态的 Agent,并对这些需要做出动作的 Agents 调用 agent.ts 里的 runAgentBatch 函数,这里是整个后端逻辑的主要循环(因为项目主要实现的就是Agents对话功能),整体流程如下:
首先调用 divideIntoGroups 函数,根据Agents之间的相对距离分为 多个对话组 和 个人组,对话可以在多人之间进行,也可以通过修改代码变成 1V1对话;
对每个对话组,调用 handleAgentInteraction 函数,如果对如何实现Agents之间对话感兴趣的话,可以直接看这个函数,函数分解为如下几个步骤:
-
从
memories表中寻找参与对话的Agents之间的关系(relationship)记忆,比如like代表喜欢 -
调用
decideWhoSpeaksNext函数——根据历史聊天记录决定下一个由谁说话(这一步将询问LLM),贴一段代码辅助理解:
PS:这一步直接暴力拼接了超长的字符串,感觉实际生产中不能这么用…
const promptStr = `[no prose]\\n [Output only JSON]
${JSON.stringify(players)}
Here is a list of people in the conversation, return BOTH name and ID of the person who should speak next based on the chat history provided below.
Return in JSON format, example: {"name": "Alex", id: "1234"} // 让LLM给出下一步说话的人选
${chatHistory.map((m) => m.content).join('\\n')}`; // 这一步将拼接所有的聊天记录(超长)
// 查询样例(太长了只贴了部分)
[no prose]\\n [Output only JSON]\\n\\n [{"agentId":"33h36nafspvkzhpvzn6xnvxk9jdy47g","characterId":"3zf2d787wd9wf4459pzems1d9jdmde0","id":"3q2vwdnnyh974nwez7v5vhrf9jdk2k8","identity":"Lucky is always happy and curious, and he loves cheese. He spends\\\\n most of his time reading about the history of science and traveling\\\\n through the galaxy on whatever ship will take him. He\\'s very articulate and\\\\n infinitely patient, except when he sees a squirrel. He\\'s also incredibly loyal and brave.\\\\n Lucky has just return'... 6985 more characters
// gpt3.5给的返回
{"name": "Kira", "id": "3ndqd9v0g7rxmt386ev9e9af9jdysb0"}
-
调用
walkAway函数——根据历史聊天记录决定是否离开本次对话(同样询问LLM,这里不贴详细记录了),如果有离开对话的人,则更新剩下的人的记录 -
如果是首次开始本轮对话,调用
startConversation函数——寻找相关的memories(这一步的token数量也爆炸),构造类似如下的prompt:
{
role: 'user',
content:
`You are ${player.name}. You just saw ${newFriendsNames}. You should greet them and start a conversation with them. Below are some of your memories about ${newFriendsNames}:` +
audience
.filter((r) => r.relationship)
.map((r) => `Relationship with ${r.name}: ${r.relationship}`)
.join('\\n') +
convoMemories.map((r) => r.memory.description).join('\\n') +
`\\n${player.name}:`, // 拼接相关的记忆
}
- 调用
converse函数——实际产生对话的函数,主要的prompt构造如下,包括自己和对方的个人特征以及聊天记录(这一步选择的记忆很少,只有两条,应该是因为对话过程对LLM的调用太多了,所以缩减了token的数量,这里肯定是上下文越多效果越好的)
const relevantReflections: string =
reflectionMemories.length > 0
? reflectionMemories
.slice(0, 2)
.map((r) => r.memory.description)
.join('\\n')
: ''; // 与对话相关的reflection记忆,只取两条
const relevantMemories: string = conversationMemories
.slice(0, 2) // only use the first 2 memories
.map((r) => r.memory.description)
.join('\\n'); // 与对话相关的聊天记录记忆,只取两条
// 个人设定
let prefixPrompt = `Your name is ${player.name}. About you: ${player.identity}.\\n`;
if (relevantReflections.length > 0) {
prefixPrompt += relevantReflections;
// console.debug('relevantReflections', relevantReflections);
}
// 对方的设定和与自己的关系
prefixPrompt += `\\nYou are talking to ${nearbyPlayersNames}, below are something about them: `;
nearbyPlayers.forEach((p) => {
prefixPrompt += `\\nAbout ${p.name}: ${p.identity}\\n`;
if (p.relationship) prefixPrompt += `Relationship with ${p.name}: ${p.relationship}\\n`;
});
// 与对话相关的记忆
prefixPrompt += `Last time you chatted with some of ${nearbyPlayersNames} it was ${lastConversationTs}. It's now ${Date.now()}. You can cut this conversation short if you talked to this group of people within the last day. \\n}`;
prefixPrompt += `Below are relevant memories to this conversation you are having right now: ${relevantMemories}\\n`;
prefixPrompt +=
'Below are the current chat history between you and the other folks mentioned above. DO NOT greet the other people more than once. Only greet ONCE. Do not use the word Hey too often. Response should be brief and within 200 characters: \\n';
- 调用
rememberConversation函数,总结本次谈话的内容,并存入memories表,这一步也询问LLM,prompt如下:
{
role: 'user',
content: `The following are messages. You are ${playerName}, and ${playerIdentity}
I would like you to summarize the conversation in a paragraph from your perspective. Add if you like or dislike this interaction.`,
}
- 对话组的prompt构造和斯坦福小镇是差不多的,都是提供对话的上下文,但是这个项目的content没有经过简化提取,token使用量巨大
对于个人组,对不进行对话的所有Agents调用调用 reflectOnMemories 函数,该函数流程如下:
-
首先从
memories表中获取100条该Agent最近的对话数据(conversation),以及100条最近的反应数据(reflection),合并这两个集合并以时间倒序排序选择最近的100条;计算这个100条的memory集合中的importenceScore总和是多少,当且仅当该值大于 500 时,才触发reflect的操作(这里意味着游戏运行初期将不会触发该操作) -
reflect操作将上面得到的对话和反应数据集合作为prompt的输入
为了方便理解,这里直接粘贴一段代码
if (shouldReflect) { // shouldReflect是对importenceScore的判断,大于500才触发
let prompt = `[no prose]\\n [Output only JSON] \\nYou are ${name}, statements about you:\\n`;
memories.forEach((m, idx) => { // memories变量是上面提到的100条相关数据的集合
prompt += `Statement ${idx}: ${m.description}\\n`; // 这里没做过滤,只是把所有数据拼接在了一起
});
prompt += `What 3 high-level insights can you infer from the above statements?
Return in JSON format, where the key is a list of input statements that contributed to your insights and value is your insight. Make the response parseable by Typescript JSON.parse() function. DO NOT escape characters or include '\\n' or white space in response.
Example: [{insight: "...", statementIds: [1,2]}, {insight: "...", statementIds: [1]}, ...]`;
console.error(prompt);
}
下面是一个实际的例子(可以看到用的token数量非常大有1w+字符,这里是笔者删减过的,实际字符数量会是3w-4w左右):
[no prose]\\n [Output only JSON] \\nYou are Alex, statements about you:\\nStatement 0: In this conversation, Kira expressed interest in getting to know Alex. Alex shared their interests in painting, programming, and sci-fi books, which Kira seemed genuinely interested in. They exchanged updates on their activities, with Alex expressing excitement about their hobbies and mentioning their love for diving into sci-fi books. The conversation took a positive turn when Kira asked for book recommendations, and Alex enth'... 14128 more characters
What 3 high-level insights can you infer from the above statements?
Return in JSON format, where the key is a list of input statements that contributed to your insights and value is your insight. Make the response parseable by Typescript JSON.parse() function. DO NOT escape characters or include '\\n' or white space in response.
Example: [{insight: "...", statementIds: [1,2]}, {insight: "...", statementIds: [1]}, ...]
而GPT对上述promt的返回如下所示(这里用的模型是 gpt-3.5-turbo-16k ):
// GPT的返回
'reflection: ' '[{"insight": "Alex enjoys conversations where the other person shows genuine interest in getting to know them and their hobbies.", "statementIds": [0, 6, 11, 16, 21]}, {"insight": "Bob\\'s lack of enthusiasm and unengaging responses make conversations with him dull and disappointing.", "statementIds": [1, 8, 23]}, {"insight": "Alex appreciates conversations that allow them to express their passions and engage in intellectual banter.", "statementIds": [3, 4, 7, 9, 10, 12, 13, 14, 15, 17, 19, 20, 22]}]'
// 以下是加入memories表中的数据
'adding reflection memory...' [
{
playerId: '3p48c7a4474816p4sccqngqy9jdnhe8',
description: 'Alex enjoys conversations where the other person shows genuine interest in getting to know them and their hobbies.',
data: {
type: 'reflection',
relatedMemoryIds: [ '3kbxvgxgx1kkdb1x970dxasy9je6k98', '3k2sw3zva4as0v3wfea8sf1n9jedpmg', '3kqa5ednmnnjf0cf7pnpdcvy9jech2g', '3kjb8ykh5jm4p5m00y69g4af9jecfrr', '3hqwdvc4de4nrw4d77d4x4jb9je3ax8' ]
}
},
{
playerId: '3p48c7a4474816p4sccqngqy9jdnhe8',
description: 'Bob\\'s lack of enthusiasm and unengaging responses make conversations with him dull and disappointing.',
data: {
type: 'reflection',
relatedMemoryIds: [ '3h0eseqf61meq41khgpezn479je22b8', '3kha33v6y0fyp6yce4wbr81j9je19qg', '3h9q6txm4mp53fr87bd9zmbc9jdm240' ]
}
},
{
playerId: '3p48c7a4474816p4sccqngqy9jdnhe8',
description: 'Alex appreciates conversations that allow them to express their passions and engage in intellectual banter.',
data: {
type: 'reflection',
relatedMemoryIds: [ '3k3gaky0pz8x3xyn2dqwdepd9jed6e8', '3hk9ab9ddhswc4ayqbt5gyd89je994g', '3k20ve97zeqsahvhnaexhw8a9jecdf0', '3k7q5zg02d1cvx9315sk9kwm9je91w0', '3h034dfejnat7sb7at45pspq9jeehbg', '3ge1b2vqj5xj81px8pvte7h29je2v68', '3hgx3e0pz7tv2dj71ra557j89je7n30', '3j71c478hn42kdq4r9ztqx2y9je7cfr', '3gmtpstppdcvjh2cr1vnfbtx9je88tg', '3kdf3ad3p18cns96vc0jkc2g9jefb98', '3hshm5mwv7qwykes2vjpz05h9je9p80', '3hzpbw57cwzfk3e56zg3zw6e9je8608', '3jq4ynda7axjsftbs06zmjsx9je85v0' ]
}
}
]
这一步的做法应该是参考了斯坦福小镇——”反思“的概念(参考这篇),这里引用文章中对于”反思“的流程描述:

最后,目前的实现无需等待所有的Agents返回结果,但代码里也提供了等所有Agents行动完成后再进行下一帧的方法,可自行修改
注:如果想要Debug查看上面笔者演示的与LLM的交互,在Convex的Log页面不能直接看到prompt的输出,可以自己写单测来观察,下面贴一个单测的示例:
export const testMemoriesGet = internalAction({
args:{},
handler: async (ctx, args) => {
const memory = MemoryDB(ctx);
const { players, world } = await ctx.runQuery(internal.testing.getDebugPlayers);
const p = await memory.reflectOnMemories(players[0].id, players[0].name)
}
})
写在 convex/testing.ts 文件中,先运行 npx convex dev 部署函数,然后运行 npx convex run testing:testMemoriesGet --no-push 查看结果
花费:
笔者没有准确计算使用token的数量,
本项目目前的设定是8个Agents,仅进行交谈,不进行其他操作,3.5满速的5刀gpt接口大概能运行1个小时左右,还是挺贵的
结合前面的分析,这个花费应该是由于在构造prompt的时候没有对memory进行过滤提取,导致一次询问花费的token数量太多,这一点需要进行优化
(对比斯坦福小镇,其实两者的花销都挺高的,但这边花销的点在于扔到prompt里的content太多了,斯坦福小镇的花销来源于更多样化的策略消耗的token)
结论
AI-Town与斯坦福小镇的对比:

经过源码的阅读和部署实验,斯坦福小镇更像是一个论文的source code,工程化程度不高,但胜在逻辑框架清晰且有创新性;AI-Town则是工业界的项目,可扩展性高,但Agents的实现简单暴力
充分利用两者的方式应该是把斯坦福AI小镇的Agents策略迁移到AI-Town搭建的这套工作流中,应该能有更好的表现