必知必会--数组与指针二
指针与数组一
四.指针数组与数组指针
4.1指针数据和数组指针的内存布局
初学者总是分不出指针数组与数组指针的区别。其实很好理解:
-
指针数组:首先它是一个数组,数组的元素都是指针,数组占多少个字节由数组本身决定。它是“储存指针的数组”的简称。
-
数组指针:首先它是一个指针,它指向一个数组。在 32 位系统下永远是占 4 个字节,至于它指向的数组占多少字节,不知道。它是“指向数组的指针”的简称。
下面到底哪个是数组指针,哪个是指针数组呢:
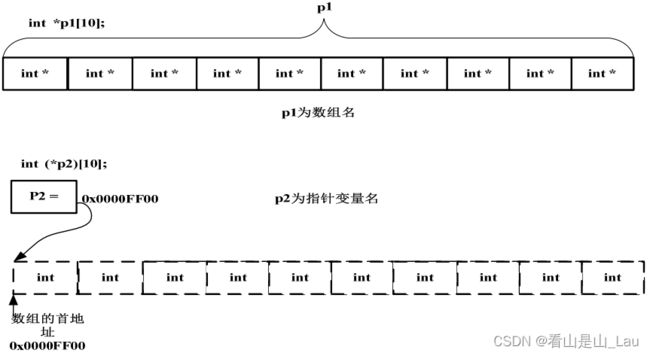
(A) int *p1[10];
(B) int (*p2)[10];
每次上课问这个问题,总有弄不清楚的。这里需要明白一个符号之间的优先级问题。
“[]”的优先级比“*”要高。p1 先与“[]”结合,构成一个数组的定义,数组名为 p1,int *修饰的是数组的内容,即数组的每个元素。那现在我们清楚,这是一个数组,其包含 10 个指向 int 类型数据的指针,即指针数组。
至于 p2 就更好理解了,在这里“()”的优先级比“[]”高,“*”号和 p2 构成一个指针的定义,指针变量名为 p2,int 修饰的是数组的内容,即数组的每个元素。数组在这里并没有名字,是个匿名数组。那现在我们清楚 p2 是一个指针,它指向一个包含 10 个 int 类型数据的数组,即数组指针。我们可以借助下面的图加深理解:
4.2a与&a之间的区别
现在再来看看下面的代码:
int main()
{
char a[5]={'A','B','C','D'};
char (*p3)[5] = &a;
char (*p4)[5] = a;
return 0;
}
上面对p3和p4的使用,哪个正确呢?p3+1 的值会是什么?p4+1 的值又会是什么?
毫无疑问,p3 和 p4 都是数组指针,指向的是整个数组。&a 是整个数组的首地址,a
是数组首元素的首地址,其值相同但意义不同。
在 C 语言里,赋值符号“=”号两边的数据类型必须是相同的,如果不同需要显示或隐式的类型转换。p3 这个定义的“=”号两边的数据类型完全一致,而 p4 这个定义的“=”号两边的数据类型就不一致了。左边的类型是指
向整个数组的指针,右边的数据类型是指向单个字符的指针。在 Visual C++6.0 上给出如下警告:warning C4047: 'initializing' : 'char (*)[5]' differs in levels of indirection from 'char *'。还好,
这里虽然给出了警告,但由于&a 和 a 的值一样,而变量作为右值时编译器只是取变量的值,所以运行并没有什么问题。不过我仍然警告你别这么用。
既然现在清楚了 p3 和 p4 都是指向整个数组的,那 p3+1 和 p4+1 的值就很好理解了。
但是如果修改一下代码,会有什么问题?p3+1 和 p4+1 的值又是多少呢?
int main()
{
char a[5]={'A','B','C','D'};
char (*p3)[3] = &a;
char (*p4)[3] = a;
return 0;
}
甚至还可以把代码再修改:
int main()
{
char a[5]={'A','B','C','D'};
char (*p3)[10] = &a;
char (*p4)[10] = a;
return 0;
}
这个时候又会有什么样的问题?p3+1 和 p4+1 的值又是多少?
上述几个问题,希望读者能仔细考虑考虑。
4.3地址的强制转换
看下面这个例子:
struct Test
{
int Num;
char *pcName;
short sDate;
char cha[2];
short sBa[4];
}*p;
假设 p 的值为 0x100000。 如下表表达式的值分别为多少?
p + 0x1 = 0x___ ?
(unsigned long)p + 0x1 = 0x___?
(unsigned int*)p + 0x1 = 0x___?
我相信会有很多人一开始没看明白这个问题是什么意思。其实我们再仔细看看,这个知识点似曾相识。一个指针变量与一个整数相加减,到底该怎么解析呢?
还记得前面我们的表达式“a+1”与“&a+1”之间的区别吗?其实这里也一样。指针变量与一个整数相加减并不是用指针变量里的地址直接加减这个整数。这个整数的单位不是byte 而是元素的个数。所以:p + 0x1 的值为 0x100000+sizof(Test)*0x1。至于此结构体的大小为 20byte。
结构体的大小计算方法参考
串口通信float型数据的处理和发送
所以 p + 0x1 的值为:0x100014。
(unsigned long)p + 0x1 的值呢?这里涉及到强制转换,将指针变量 p 保存的值强制转换成无符号的长整型数。任何数值一旦被强制转换,其类型就改变了。所以这个表达式其实就是一个无符号的长整型数加上另一个整数。所以其值为:0x100001。
(unsigned int*)p + 0x1 的值呢?这里的p被强制转换成一个指向无符号整型的指针。所以其值为:0x100000+sizof(unsigned int)*0x1,等于0x100004。
上面这个问题似乎还没啥技术含量,下面就来个有技术含量的:
在 x86 系统下,其值为多少?
int main()
{
int a[4]={1,2,3,4};
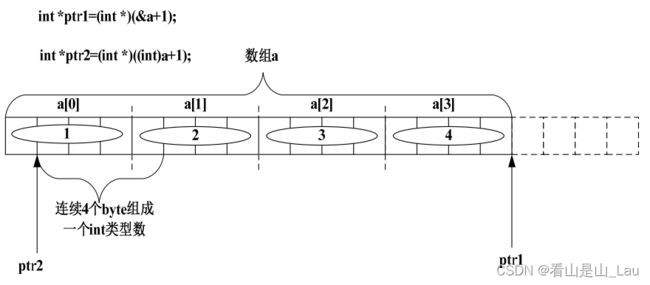
int *ptr1=(int *)(&a+1);
int *ptr2=(int *)((int)a+1);
printf("%x,%x",ptr1[-1],*ptr2);
return 0;
}
根据上面的讲解,&a+1 与 a+1 的区别已经清楚。
ptr1:将&a+1 的值强制转换成 int*类型,赋值给 int*类型的变量 ptr,ptr1 肯定指到数组 a 的下一个 int 类型数据了。ptr1[-1]被解析成*(ptr1-1),即 ptr1 往后退4个 byte。所以其值为 0x4。
ptr2:按照上面的讲解,(int)a+1 的值是元素 a[0]的第二个字节的地址。然后把这个地址强制转换成 int*类型的值赋给 ptr2,也就是说*ptr2 的值应该为元素 a[0]的第二个字节开始的连续 4 个 byte 的内容。
其内存布局如下图:
五.多维数组与多维指针
5.1二维数组
1.假想中的二维数组布局
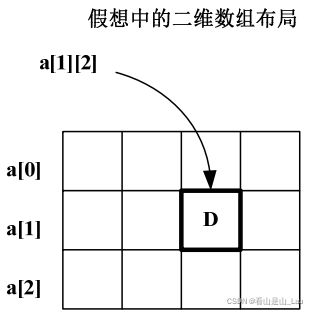
我们前面讨论过,数组里面可以存任何数据,除了函数。下面就详细讨论讨论数组里面存数组的情况。Excel 表,我相信大家都见过。我们平时就可以把二维数组假想成一个 excel表,比如:
char a[3][4];
2.内存和尺子的对比
实际上内存不是表状的,而是线性的。见过尺子吧?尺子和我们的内存非常相似。一般尺子上最小刻度为毫米,而内存的最小单位为 1 个 byte。平时我们说 32 毫米,是指以零开始偏移 32 毫米;平时我们说内存地址为 0x0000FF00 也是指从内存零地址开始偏移0x0000FF00 个 byte。既然内存是线性的,那二维数组在内存里面肯定也是线性存储的。实际上其内存布局如下图:
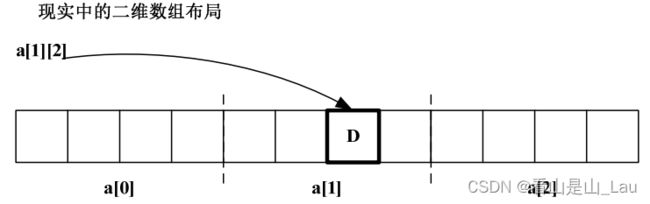
以数组下标的方式来访问其中的某个元素:a[i][j]。编译器总是将二维数组看成是一个一维数组,而一维数组的每一个元素又都是一个数组。a[3]这个一维数组的三个元素分别为:a[0],a[1],a[2]。每个元素的大小为 sizeof(a[0]),即 sizof(char)*4。由此可以计算出 a[0],a[1],a[2]三个元素的首地址分别为& a[0],& a[0]+ 1*sizof(char)*4,& a[0]+ 2*sizof(char)*4。亦即 a[i]的首地址为& a[0]+i*sizof(char)*4。这时候再考虑 a[i]里面的内容。就本例而言,a[i]内有 4 个 char 类型的元素,其每个元素的首地址分别为&a[i],&a[i]+1*sizof(char),&a[i]+2*sizof(char),&a[i]+3*sizof(char),即 a[i][j]的首地址为&a[i]+j*sizof(char)。再把&a[i]的值用 a 表示,得到 a[i][j]元素的首地址为:a+ i*sizof(char)*4+ j*sizof(char)。同样,可以换算成以指针的形式表示:*(*(a+i)+j)。
经过上面的讲述,相信你已经掌握了二维数组在内存里面的布局了。下面就看一个题:
#include
int main(int argc,char * argv[])
{
int a[3][2]={(0,1),(2,3),(4,5)};
int *p;
p=a [0];
printf("%d",p[0]);
}
问打印出来的结果是多少?
很多人都觉得这太简单了,很快就能说出答案:0。不过很可惜,错了。答案应该是 1。如果你也认为是 0,那你实在应该好好看看这个题。花括号里面嵌套的是小括号,而不是花括号!这里是花括号里面嵌套了逗号表达式!其实这个赋值就相当于 int a [3][2]={1,3,5};所以,在初始化二维数组的时候一定要注意,别不小心把应该用的花括号写成小括号了。
3.&p[4][2]-&a[4][2]的值为多少?
上面的问题似乎还比较好理解,下面再看一个例子:
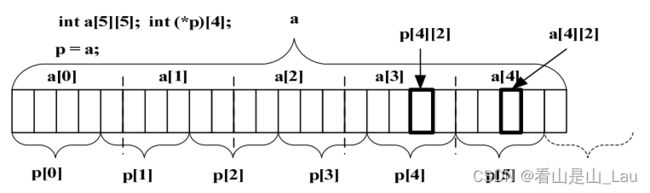
int a[5][5];
int (*p)[4];
p = a;
问&p[4][2] - &a[4][2]的值为多少?
这个问题似乎非常简单,但是几乎没有人答对了。我们可以先写代码测试一下其值,然后分析一下到底是为什么。在 Visual C++6.0 里,测试代码如下:
int main()
{
int a[5][5];
int (*p)[4];
p = a;
printf("a_ptr=%#p,p_ptr=%#p\n",&a[4][2],&p[4][2]);
printf("%p,%d\n",&p[4][2] - &a[4][2],&p[4][2] - &a[4][2]);
return 0;
}
经过测试,可知&p[4][2] - &a[4][2]的值为-4。这到底是为什么呢?下面我们就来分析一下:当数组名 a 作为右值时,代表的是数组首元素的首地址。这里的a为二维数组,我们把数组 a 看作是包含 5 个 int 类型元素的一维数组,里面再存储了一个一维数组。如此,则a在这里代表的是 a[0]的首地址。a+1 表示的是一维数组 a 的第二个元素。a[4]表示的是一维数组 a 的第 5 个元素,而这个元素里又存了一个一维数组。所以&a[4][2]表示的是&a[0][0]+4*5*sizeof(int) + 2*sizeof(int)。
根据定义,p 是指向一个包含 4 个元素的数组的指针。也就是说 p+1 表示的是指针p向后移动了一个“包含 4 个int 类型元素的数组”。这里 1 的单位是 p 所指向的空间,即4*sizeof(int)。所以,p[4]相对于 p[0]来说是向后移动了 4个“包含 4 个 int 类型元素的数组”, 即&p[4]表示的是&p[0]+4*4*sizeof(int)。由于p被初始化为&a[0],那么&p[4][2]表示的是&a[0][0]+4*4*sizeof(int)+2* sizeof(int)。
再由上面的讲述,&p[4][2] 和 &a[4][2]的值相差 4 个int类型的元素。现在,上面测试出来的结果也可以理解了吧?其实我们最简单的办法就是画内存布局图:
5.2二级指针的内存布局
二级指针是经常用到的,尤其与二维数组在一起的时候更是令人迷糊。例如:
char **p;
定义了一个二级指针变量 p。p 是一个指针变量,毫无疑问在 32 位系统下占4个 byte。
它与一级指针不同的是,一级指针保存的是数据的地址,二级指针保存的是一级指针的地
址。下图帮助理解:

我们试着给变量p初始化:
(A) p = NULL;
(B) char *p2; p = &p2;
任何指针变量都可以被初始化为 NULL(注意是 NULL,不是 NUL,更不是 null),二级指针也不例外。也就是说把指针指向数组的零地址。联想到前面我们把尺子比作内存,如果把内存初始化为 NULL,就相当于把指针指向尺子上 0 毫米处,这时候指针没有任何内存可用。
当我们真正需要使用 p 的时候,就必须把一个一级指针的地址保存到 p 中,所以(B) 的赋值方式也是正确的。
给 p 赋值没有问题,但怎么使用 p 呢?这就需要我们前面多次提到的钥匙“*”。
第一步:根据 p 这个变量,取出它里面存的地址。
第二步:找到这个地址所在的内存。
第三步:用钥匙打开这块内存,取出它里面的地址,*p 的值。
第四步:找到第二次取出的这个地址。
第五步:用钥匙打开这块内存,取出它里面的内容,这就是我们真正的数据,**p 的值。
我们在这里用了两次钥匙“*”才最终取出了真正的数据。也就是说要取出二级指针所真正指向的数据,需要使用两次两次钥匙“*”。
至于超过二维的数组和超过二维的指针一般使用比较少,而且按照上面的分析方法同样也可以很轻松的分析明白,这里就不再详细讨论。读者有兴趣的话,可以研究研究。
六.数组参数与指针参数
我们都知道参数分为形参和实参。形参是指声明或定义函数时的参数,而实参是在调用函数时主调函数传递过来的实际值。
6.1一维数组参数
1.能否向函数传递一个数组?
看例子:
void fun(char a[10])
{
char c = a[3];
}
int main()
{
char b[10] = “abcdefg”;
fun(b[10]);
return 0;
}
先看上面的调用,fun(b[10]);将 b[10]这个数组传递到 fun 函数。但这样正确吗?b[10]是代表一个数组吗?
显然不是,我们知道 b[0]代表是数组的一个元素,那 b[10]又何尝不是呢?只不过这里数组越界了,这个 b[10]并不存在。但在编译阶段,编译器并不会真正计算 b[10]的地址并取值,所以在编译的时候编译器并不认为这样有错误。虽然没有错误,但是编译器仍然给出了两个警告:
warning C4047: 'function' : 'char *' differs in levels of indirection from 'char '
warning C4024: 'fun' : different types for formal and actual parameter 1
这是什么意思呢?这两个警告告诉我们,函数参数需要的是一个 char*类型的参数,而实际参数为 char 类型,不匹配。虽然编译器没有给出错误,但是这样运行肯定会有问题。如图:

这是一个内存异常,我们分析分析其原因。其实这里至少有两个严重的错误。
第一:b[10]并不存在,在编译的时候由于没有去实际地址取值,所以没有出错,但是在运行时,将计算 b[10]的实际地址,并且取值。这时候发生越界错误。
第二:编译器的警告已经告诉我们编译器需要的是一个 char*类型的参数,而传递过去的是一个 char 类型的参数,这时候fun 函数会将传入的 char 类型的数据当地址处理,同样会发生错误。
第一个错误很好理解,那么第二个错误怎么理解呢?fun 函数明明传递的是一个数组啊,编译器怎么会说是
char *类型呢?别急,我们先把函数的调用方式改变一下:fun(b);
b 是一个数组,现在将数组 b 作为实际参数传递。这下该没有问题了吧?调试、运行,一切正常,没有问题,收工!很轻易是吧?但是你确认你真正明白了这是怎么回事?数组 b真的传递到了函数内部?
2.无法向函数传递一个数组
我们完全可以验证一下:
void fun(char a[10])
{
int i = sizeof(a);
char c = a[3];
}
如果数组 b 真正传递到函数内部,那 i 的值应该为 10。但是我们测试后发现 i 的值竟然为 4!为什么会这样呢?难道数组 b 真的没有传递到函数内部?是的,确实没有传递过去,这是因为这样一条规则:
C 语言中,当一维数组作为函数参数的时候,编译器总是把它解析成一个指向其首元素首地址的指针。
这么做是有原因的。在 C 语言中,所有非数组形式的数据实参均以传值形式(对实参做一份拷贝并传递给被调用的函数,函数不能修改作为实参的实际变量的值,而只能修改传递给它的那份拷贝)调用。然而,如果要拷贝整个数组,无论在空间上还是在时间上,其开销都是非常大的。更重要的是,在绝大部分情况下,你其实并不需要整个数组的拷贝,你只想告诉函数在那一刻对哪个特定的数组感兴趣。这样的话,为了节省时间和空间,提高程序运行的效率,于是就有了上述的规则。同样的,函数的返回值也不能是一个数组,而只能是指针。这里要明确的一个概念就是:**函数本身是没有类型的,只有函数的返回值才有类型。**很多书都把这点弄错了,甚至出现“XXX 类型的函数”这种说法。
经过上面的解释,相信你已经理解上述的规定以及它的来由。上面编译器给出的提示,说函数的参数是一个 char*类型的指针,这点相信也可以理解。
既然如此,我们完全可以把 fun 函数改写成下面的样子:
void fun(char *p)
{
char c = p[3];//或者是 char c = *(p+3);
}
同样,你还可以试试这样子:
void fun(char a[10])
{
char c = a[3];
}
int main()
{
char b[100] = “abcdefg”;
fun(b);
return 0;
}
运行完全没有问题。实际传递的数组大小与函数形参指定的数组大小没有关系。既然
如此,那我们也可以改写成下面的样子:
void fun(char a[ ])
{
char c = a[3];
}
改写成这样或许比较好,至少不会让人误会成只能传递一个 10 个元素的数组。
6.2一级指针参数
1.能否把指针变量本身传递给一个函数
我们把上一节讨论的列子再改写一下:
void fun(char *p)
{
char c = p[3];//或者是 char c = *(p+3);
}
int main()
{
char *p2 = “abcdefg”;
fun(p2);
return 0;
}
这个函数调用,真的把 p2 本身传递到了fun函数内部吗?
我们知道 p2 是main函数内的一个局部变量,它只在 main 函数内部有效。(这里需要澄清一个问题:main 函数内的变量不是全局变量,而是局部变量,只不过它的生命周期和全局变量一样长而已。全局变量一定是定义在函数外部的。初学者往往弄错这点。)既然它是局部变量,fun 函数肯定无法使用p2的真身。那函数调用怎么办?好办:对实参做一份拷贝并传递给被调用的函数。即对 p2 做一份拷贝,假设其拷贝名为_p2。那传递到函数内部的就是_p2 而并非 p2 本身。
2.无法把指针变量本身传递给一个函数
这很像孙悟空拔下一根猴毛变成自己的样子去忽悠小妖怪。所以fun函数实际运行时,用到的都是_p2 这个变量而非 p2 本身。如此,我们看下面的例子:
void GetMemory(char * p, int num)
{
p = (char *)malloc(num*sizeof(char));
}
int main()
{
char *str = NULL;
GetMemory(str,10);
strcpy(str,”hello”);
free(str);//free 并没有起作用,内存泄漏
return 0;
}
在运行 strcpy(str,”hello”)语句的时候发生错误。这时候观察str的值,发现仍然为 NULL。
也就是说 str 本身并没有改变,我们 malloc 的内存的地址并没有赋给 str,而是赋给了_str。而这个_str 是编译器自动分配和回收的,我们根本就无法使用。所以想这样获取一块内存是不行的。那怎么办? 两个办法:
第一:用 return。
char * GetMemory(char * p, int num)
{
p = (char *)malloc(num*sizeof(char));
return p;
}
int main()
{
char *str = NULL;
str = GetMemory(str,10);
strcpy(str,”hello”);
free(str);
return 0;
}
这个方法简单,容易理解。
第二:用二级指针。
void GetMemory(char ** p, int num)
{
*p = (char *)malloc(num*sizeof(char));
return p;
}
int main()
{
char *str = NULL;
GetMemory(&str,10);
strcpy(str,”hello”);
free(str);
return 0;
}
注意,这里的参数是&str 而非 str。这样的话传递过去的是 str 的地址,是一个值。在函数内部,用钥匙“*”来开锁:*(&str),其值就是 str。所以 malloc 分配的内存地址是真正赋值给了 str 本身。
6.3二维数组参数与二维指针参数
前面详细分析了二维数组与二维指针,那它们作为参数时与不作为参数时又有什么区别呢 ?看例子:
void fun(char a[3][4]);
我们按照上面的分析,完全可以把 a[3][4]理解为一个一维数组 a[3],其每个元素都是一个含有4个 char 类型数据的数组。上面的规则,“C 语言中,当一维数组作为函数参数的时候,编译器总是把它解析成一个指向其首元素首地址的指针。”在这里同样适用,也就是说我们可以把这个函数声明改写为:
void fun(char (*p)[4]);
这里的括号绝对不能省略,这样才能保证编译器把 p 解析为一个指向包含 4 个char类型数据元素的数组,即一维数组 a[3]的元素。同样,作为参数时,一维数组“[]”号内的数字完全可以省略:
void fun(char a[ ][4]);
不过第二维的维数却不可省略,想想为什么不可以省略?
注意:如果把上面提到的声明 void fun(char (*p)[4])中的括号去掉之后,声明
“void fun(char *p[4])”可以改写成:
void fun(char **p);
这是因为参数*p[4],对于 p 来说,它是一个包含 4 个指针的一维数组,同样把这个一维数
组也改写为指针的形式,那就得到上面的写法。
上面讨论了这么多,那我们把二维数组参数和二维指针参数的等效关系整理一下:

这里需要注意的是:C语言中,当一维数组作为函数参数的时候,编译器总是把它解析成一个指向其首元素首地址的指针。这条规则并不是递归的,也就是说只有一维数组才是如此,当数组超过一维时,将第一维改写为指向数组首元素首地址的指针之后,后面的维再也不可改写。比如:a[3][4][5]作为参数时可以被改写为(*p)[4][5]
至于超过二维的数组和超过二级的指针,由于本身很少使用,而且按照上面的分析方法也能很好的理解,这里就不再详细讨论。有兴趣的可以好好研究研究。
七.函数指针
7.1函数指针的定义
顾名思义,函数指针就是函数的指针。它是一个指针,指向一个函数。看例子:
(A) char* (*fun1)(char* p1,char* p2);
(B) char** fun2(char* p1,char* p2);
(C) char* fun3(char* p1,char* p2);
数组参数等效的指针参数
数组的数组:char a[3][4]
数组的指针:char (*p)[10]
指针数组: char *a[5]
指针的指针:char **p看看上面三个表达式分别是什么意思?
(C):这很容易,fun3 是函数名,p1,p2 是参数,其类型为 char *型,函数的返回值为 char *类型。
(B):也很简单,与© 表达式相比,唯一不同的就是函数的返回值类型为 char**,是个二级指针。
(A):fun1 是函数名吗?回忆一下前面讲解数组指针时的情形。我们说数组指针这么定义或许更清晰:
int (*)[10] p;
再看看 (A)表达式与这里何其相似!明白了吧。这里 fun1 不是什么函数名,而是一个指针变量,它指向一个函数。这个函数有两个指针类型的参数,函数的返回值也是一个指针。同样,我们把这个表达式改写一下:
char * (*)(char * p1,char * p2) fun1; 这样子是不是好看一些呢?只可惜编译器不这么想。
7.2函数指针的使用、
1.函数指针使用的例子
上面我们定义了一个函数指针,但如何来使用它呢?先看如下例子:
#include
#include
char * fun(char * p1,char * p2)
{
int i = 0;
i = strcmp(p1,p2);
if (0 == i)
{
return p1;
}
else
{
return p2;
}
}
int main()
{
char * (*pf)(char * p1,char * p2);
pf = &fun;
(*pf) ("aa","bb");return 0;
}
我们使用指针的时候,需要通过钥匙“*”来取其指向的内存里面的值,函数指针使用也如此。通过用(*pf)取出存在这个地址上的函数,然后调用它。这里需要注意到是,在Visual C++6.0 里,给函数指针赋值时,可以用&fun 或直接用函数名 fun。这是因为函数名被编译之后其实就是一个地址,所以这里两种用法没有本质的差别。这个例子很简单,就不再详细讨论了。
2.*(int*)&p这是什么?
也许上面的例子过于简单,我们看看下面的例子:
void Function()
{
printf("Call Function!\n");
}
int main()
{
void (*p)();
*(int*)&p=(int)Function;
(*p) ();
return 0;
}
这是在干什么?*(int*)&p=(int)Function;表示什么意思?
别急,先看这行代码:
void (*p)();这行代码定义了一个指针变量 p,p 指向一个函数,这个函数的参数和返回值都是 void。
&p 是求指针变量p本身的地址,这是一个 32 位的二进制常数(32 位系统)。
(int*)&p 表示将地址强制转换成指向 int 类型数据的指针。
(int)Function 表示将函数的入口地址强制转换成 int 类型的数据。
分析到这里,相信你已经明白*(int*)&p=(int)Function;表示将函数的入口地址赋值给指
针变量 p。那么(*p) ();就是表示对函数的调用。
讲解到这里,相信你已经明白了。其实函数指针与普通指针没什么差别,只是指向的内容不同而已。
使用函数指针的好处在于,可以将实现同一功能的多个模块统一起来标识,这样一来更容易后期的维护,系统结构更加清晰。或者归纳为:便于分层设计、利于系统抽象、降低耦合度以及使接口与实现分开。
7.3``((void() ())0)()`这是什么?
(*(void(*) ())0)();这是《C Traps and Pitfalls》这本经典的书中的一个例子。没有发狂吧?下面我们就来分
析分析:
第一步:void(*) (),可以明白这是一个函数指针类型。这个函数没有参数,没有返回值。
第二步:(void(*) ())0,这是将 0 强制转换为函数指针类型,0 是一个地址,也就是说一个函数存在首地址为 0 的一段区域内。
第三步:(*(void(*) ())0),这是取 0 地址开始的一段内存里面的内容,其内容就是保存在首地址为 0 的一段区域内的函数。
第四步:(*(void(*) ())0)(),这是函数调用。好像还是很简单是吧,上面的例子再改写改写:
(*(char**(*) (char **,char **))0) ( char **,char **);
如果没有上面的分析,肯怕不容易把这个表达式看明白吧。不过现在应该是很简单的一件事了。读者以为呢?
7.4函数指针数组
现在我们清楚表达式 “char* (*pf)(char * p)”定义的是一个函数指针 pf。既然 pf 是一个指针,那就可以储存在一个数组里。把上式修改一下:char * (*pf[3])(char * p);
这是定义一个函数指针数组。它是一个数组,数组名为 pf,数组内存储了 3 个指向函数的指针。这些指针指向一些返回值类型为指向字符的指针、参数为一个指向字符的指针的函数。这念起来似乎有点拗口。不过不要紧,关键是你明白这是一个指针数组,是数组。
函数指针数组怎么使用呢?这里也给出一个非常简单的例子,只要真正掌握了使用方法,
再复杂的问题都可以应对。如下:
#include
#include
char* fun1(char * p)
{
printf("%s\n",p);
return p;
}
char* fun2(char * p)
{
printf("%s\n",p);
return p;
}
char * fun3(char * p)
{
printf("%s\n",p);
return p;
}
int main()
{
char * (*pf[3])(char * p);
pf[0] = fun1; // 可以直接用函数名
pf[1] = &fun2; // 可以用函数名加上取地址符
pf[2] = &fun3;
pf[0]("fun1");
pf[0]("fun2");
pf[0]("fun3");
return 0;
}
7.5函数指针数组的指针
看着这个标题没发狂吧?函数指针就够一般初学者折腾了,函数指针数组就更加麻烦,现在的函数指针数组指针就更难理解了。其实,没这么复杂。前面详细讨论过数组指针的问题,这里的函数指针数组指针不就是一个指针嘛。只不过这个指针指向一个数组,这个数组里面存的都是指向函数的指针。仅此而已。
下面就定义一个简单的函数指针数组指针:
char * (*(*pf)[3])(char * p);
注意,这里的 pf 和上一节的 pf 就完全是两码事了。上一节的 pf 并非指针,而是一个数组名;
这里的pf确实是实实在在的指针。这个指针指向一个包含了 3 个元素的数组;这个数字里面存的是指向函数的指针;这些指针指向一些返回值类型为指向字符的指针、参数为一个指向字符的指针的函数。这比上一节的函数指针数组更拗口。其实你不用管这么多,明白这是一个指针就 ok 了。其用法与前面讲的数组指针没有差别。下面列一个简单的例子:
#include
#include
char* fun1(char * p)
{
printf("%s\n",p);
return p;
}
char* fun2(char * p)
{
printf("%s\n",p);
return p;
}
char* fun3(char * p)
{
printf("%s\n",p);
return p;
}
int main()
{
char* (*a[3])(char * p);
char* (*(*pf)[3])(char * p);
pf = &a;
a[0] = fun1;
a[1] = &fun2;
a[2] = &fun3;
pf[0][0]("fun1");
pf[0][1]("fun2");pf[0][2]("fun3");
return 0;
}
推荐阅读:
面试中常被问到的C语言基础知识值得收藏 (qq.com)
参考书籍:
[1]C primer
[2]C 专家编程
[3]C陷阱与缺陷
[4]C和指针
感谢阅读:)
inner peace
知行合一
