Python爬虫:如何下载懂车帝的电动车数据(完整代码)
⭐️⭐️⭐️⭐️⭐️欢迎来到我的博客⭐️⭐️⭐️⭐️⭐️
作者:秋无之地简介:CSDN爬虫、后端、大数据领域创作者。目前从事python爬虫、后端和大数据等相关工作,主要擅长领域有:爬虫、后端、大数据开发、数据分析等。
欢迎小伙伴们点赞、收藏⭐️、留言、关注,关注必回关
上一篇文章已经跟大家介绍过《数据采集:数据挖掘的基础》,相信大家对用户画像都有一个基本的认识。下面我讲一下:Python爬虫:如何下载懂车帝的电动车数据。
一、确定目标数据
1、先打开目标网站,找到目标数据所在的页面
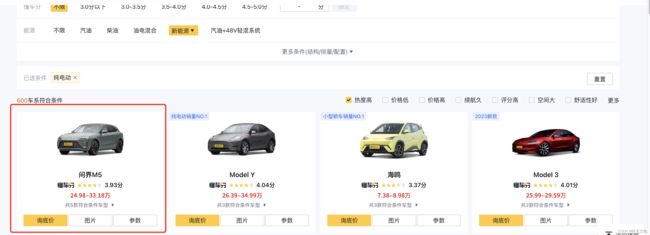
2、找到目标数据所在的api或页面
通过f12打开调试模式,通过搜索关键词,找到关键词所在的api或页面
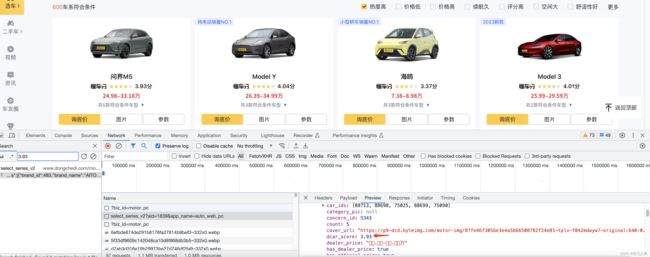
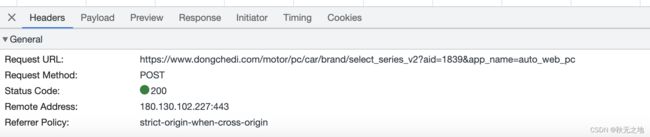
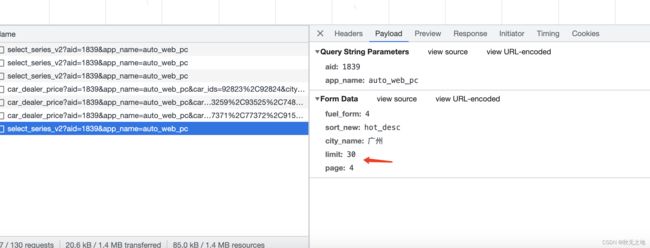
3、观察请求参数
1)header参数:没有加密数据,无需登录因此不用cookie
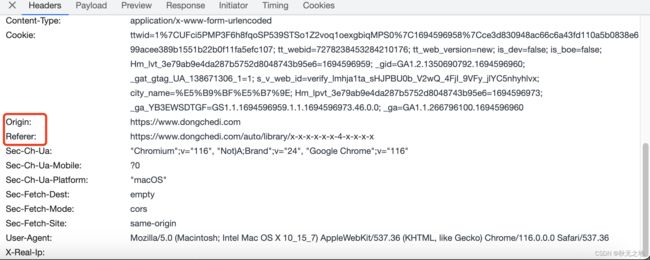
2)body参数:同样没有加密参数

3)翻页:body参数新增了limit(每页展示数量)、page(页码)
二、请求接口
使用requests库请求接口,返回数据
def get_data(self,page=1,is_total=0):
'''请求接口'''
url = "https://www.dongchedi.com/motor/pc/car/brand/select_series_v2?aid=1839&app_name=auto_web_pc"
# body参数
data_dict = {
"fuel_form": "4",
"sort_new": "hot_desc",
"city_name": "广州",
"limit": 30,
"page": page
}
res = requests.post(url=url, headers=self.header, data=data_dict).json()
# print(res)
#返回数据
if res and 'status' in res and res['status']==0:
if is_total:
return res['data']['series_count']
return res['data']['series']
else:
return []三、数据解析
将返回的数据进行json序列化,然后通过遍历、字典提取目标数据
def data_deal(self,data_list=None):
'''数据解析'''
new_list = []
for data_dict in data_list:
#品牌ID
brand_id = data_dict['brand_id']
#品牌
brand_name = data_dict['brand_name']
#封面图
cover_url = data_dict['cover_url']
#车名
outter_name = data_dict['outter_name']
#官方指导价
official_price = data_dict['official_price']
#款式数量
count = data_dict['count']
#评分
dcar_score = data_dict['dcar_score']
new_list.append([brand_id,brand_name,cover_url,outter_name,official_price,count,dcar_score])
return new_list四、数据存储
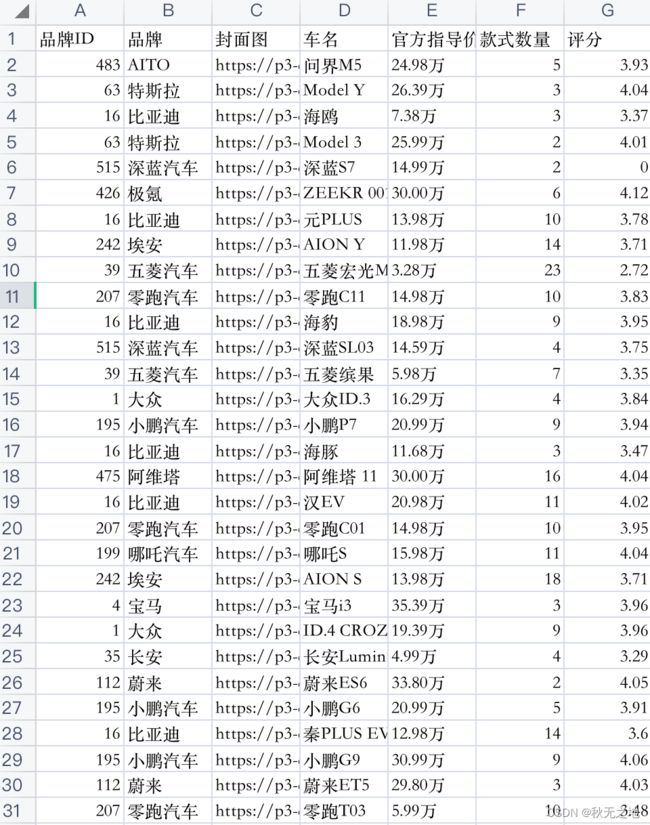
数据解析后,对数据进行拼接,然后持久化,存在csv文件
def data_to_csv(self,data_li=None):
'''数据存储'''
df = pd.DataFrame(data_li)
df.to_csv("test1.csv", index=False)文件内容:
五、完整代码
完整代码如下:
# -*- coding: utf-8 -*-
import math
import requests
import pandas as pd
class Dongchedi_class():
'''懂车帝'''
def __init__(self):
self.header = {
"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36",
"Referer":"https://www.dongchedi.com/auto/library/x-x-x-x-x-x-4-x-x-x-x",
"Origin":"https://www.dongchedi.com",
}
def get_data(self,page=1,is_total=0):
'''请求接口'''
url = "https://www.dongchedi.com/motor/pc/car/brand/select_series_v2?aid=1839&app_name=auto_web_pc"
# body参数
data_dict = {
"fuel_form": "4",
"sort_new": "hot_desc",
"city_name": "广州",
"limit": 30,
"page": page
}
res = requests.post(url=url, headers=self.header, data=data_dict).json()
# print(res)
#返回数据
if res and 'status' in res and res['status']==0:
if is_total:
return res['data']['series_count']
return res['data']['series']
else:
return []
def data_deal(self,data_list=None):
'''数据解析'''
new_list = []
for data_dict in data_list:
#品牌ID
brand_id = data_dict['brand_id']
#品牌
brand_name = data_dict['brand_name']
#封面图
cover_url = data_dict['cover_url']
#车名
outter_name = data_dict['outter_name']
#官方指导价
official_price = data_dict['official_price']
#款式数量
count = data_dict['count']
#评分
dcar_score = data_dict['dcar_score']
new_list.append([brand_id,brand_name,cover_url,outter_name,official_price,count,dcar_score])
return new_list
def data_to_csv(self,data_li=None):
'''数据存储'''
df = pd.DataFrame(data_li)
df.to_csv("test1.csv", index=False)
def run(self):
#获取总页数
total = self.get_data(page=1, is_total=1)
if total>0:
total_page = math.ceil(total/30)
print("总数:",total,",总页数:",total_page)
#翻页获取数据
all_list = []
all_list.append(["品牌ID", "品牌", "封面图", "车名", "官方指导价", "款式数量", "评分"])
for page in range(1,total_page):
print("当前页数:",page)
data_list = self.get_data(page=page)
out_date = self.data_deal(data_list=data_list)
print("*"*100)
print(out_date)
all_list += out_date
self.data_to_csv(data_li=all_list)
if __name__ == '__main__':
ddc = Dongchedi_class()
ddc.run()
六、总结
Python爬虫主要分三步:
- 请求接口
- 数据解析
- 数据存储
版权声明
本文章版权归作者所有,未经作者允许禁止任何转载、采集,作者保留一切追究的权利。